







中和的介绍
随着业务发展,系统拆分导致系统调用链路愈发复杂一个前端请求可能最终需要调用很多次后端服务才能完成
当整个请求变慢或不可用时,我们是无法得知该请求是由某个或某些后端服务引起的,
这时就需要解决如何快读定位服务故障点,以对症下药。于是就有了分布式系统调用跟踪的诞生。
一般的,一个分布式服务跟踪系统,主要有三部分:数据收集、数据存储和数据展示。根据系统大小不同,
每一部分的结构又有一定变化。譬如,对于大规模分布式系统,数据存储可分为实时数据和全量数据两部分,
实时数据用于故障排查(troubleshooting),全量数据用于系统优化;
数据收集除了支持平台无关和开发语言无关系统的数据收集,还包括异步数据收集
(需要跟踪队列中的消息,保证调用的连贯性),以及确保更小的侵入性;数据展示又涉及到数据挖掘和分析。
虽然每一部分都可能变得很复杂,但基本原理都类似。
服务追踪的追踪单元是从客户发起请求(request)抵达被追踪系统的边界开始,
到被追踪系统向客户返回响应(response)为止的过程,称为一个“trace”。
每个 trace 中会调用若干个服务,为了记录调用了哪些服务,以及每次调用的消耗时间等信息
,在每次调用服务时,埋入一个调用记录,称为一个“span”。这样,若干个有序的 span 就组成了一个 trace。
在系统向外界提供服务的过程中,会不断地有请求和响应发生,也就会不断生成 trace,
把这些带有span 的 trace 记录下来,就可以描绘出一幅系统的服务拓扑图。
附带上 span 中的响应时间,以及请求成功与否等信息,就可以在发生问题的时候,找到异常的服务;
根据历史数据,还可以从系统整体层面分析出哪里性能差,定位性能优化的目标。
Spring Cloud Sleuth为服务之间调用提供链路追踪。通过Sleuth可以很清楚的了解到一个服务请求经过了哪些服务,
每个服务处理花费了多长。从而让我们可以很方便的理清各微服务间的调用关系。此外Sleuth可以帮助我们:
耗时分析: 通过Sleuth可以很方便的了解到每个采样请求的耗时,从而分析出哪些服务调用比较耗时;
可视化错误: 对于程序未捕捉的异常,可以通过集成Zipkin服务界面上看到;
链路优化: 对于调用比较频繁的服务,可以针对这些服务实施一些优化措施。
spring cloud sleuth可以结合zipkin,将信息发送到zipkin,利用zipkin的存储来存储信息,利用zipkin ui来展示数据。
提取
随着服务的增多需要理清楚各个工程之间的调用会很难
而zipkin根据日志分析,能使用视图的形式将各个工程之间的调用展示出来
名词和基本术语(Spring Cloud Sleuth采用的是Google的开源项目Dapper的专业术语。)
Span:基本工作单元,发送一个远程调度任务 就会产生一个Span,Span是一个64位ID唯一标识的,
Trace是用另一个64位ID唯一标识的,Span还有其他数据信息,比如摘要、时间戳事件、Span的ID、以及进度ID。
Trace:一系列Span组成的一个树状结构。请求一个微服务系统的API接口,这个API接口,需要调用多个微服务,
调用每个微服务都会产生一个新的Span,所有由这个请求产生的Span组成了这个Trace。
Annotation:用来及时记录一个事件的,一些核心注解用来定义一个请求的开始和结束 。这些注解包括以下:
cs - Client Sent -客户端发送一个请求,这个注解描述了这个Span的开始
sr - Server Received -服务端获得请求并准备开始处理它,如果将其sr减去cs时间戳便可得到网络传输的时间。
ss - Server Sent (服务端发送响应)–该注解表明请求处理的完成(当请求返回客户端),如果ss的时间戳减去sr时间戳,
就可以得到服务器请求的时间。
cr - Client Received (客户端接收响应)-此时Span的结束,如果cr的时间戳减去cs时间戳便可以得到整个请求所消耗的时间。
快速上手
1下载zipkin的jar查看视图
在F版本以后就不需要单独创建一个Server了需要下载一个jar
下载链接https://dl.bintray.com/openzipkin/maven/io/zipkin/java/zipkin-server/
本人下载的2.10.2
下载以后可直接双击启动 ,
或者cmd窗口用命令启动`java -jar zipkin-server-2.10.2-exec.jar`
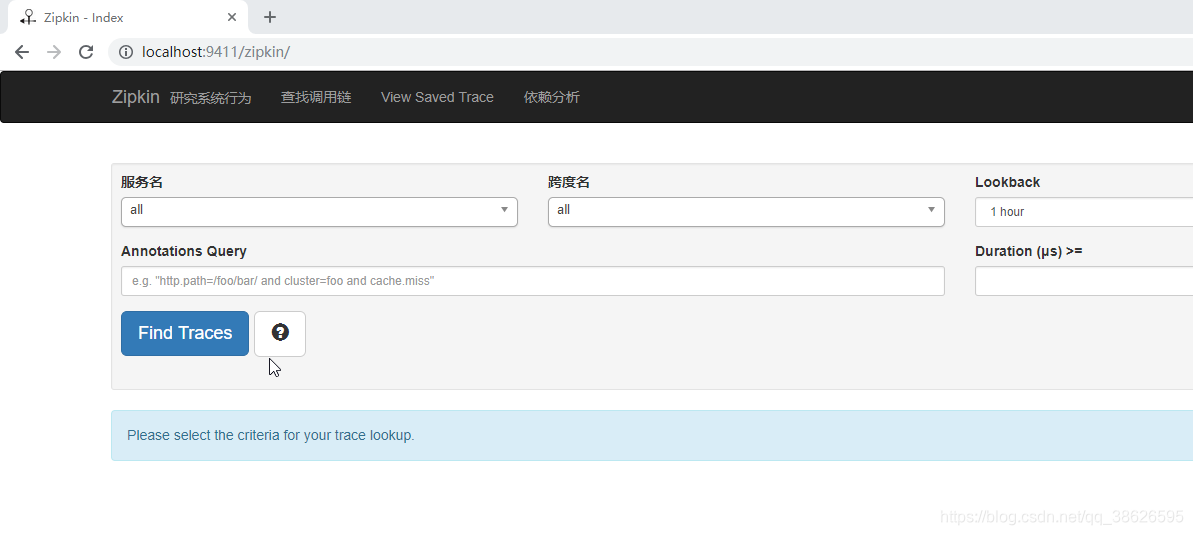
端口是9411可直接访问 127.0.0.1:9411
如图
2 SpringCloud各个服务的消费者+提供者都加依赖
!!注册中心不用父工程不用
!!只添加在个服务的消费者+提供者
1.添加依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
2. yml配置
spring:
zipkin:
base-url: http://localhost:9411 # zipkin的url
sleuth:
sampler:
probability: 1.0 # 值为0.1-1.0(默认为0.1)1表示100%保证被抓取
然后重启项目,发现打印的日志有所不同 如图
zipkin就是根据日志中的这些信息来分析各个工程之间的调用
其实就是 INFO [项目名,上面提到的traceId,上面提到的spanId,export]
export — 布尔类型。表示是否要将该信息输出到类似Zipkin这样的聚合器进行收集和展示。
这时刚启动 所有不是被请求
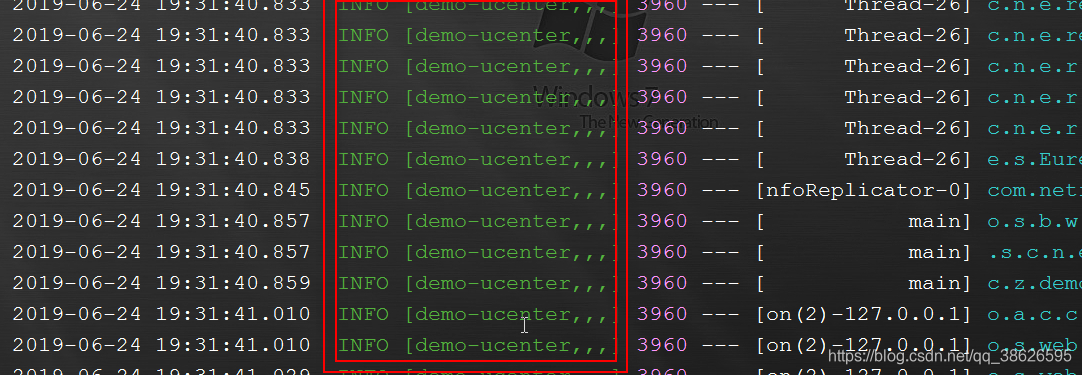
2.1 如果启动时没有打印类似的日志请在yml配置文件添加(有也可以加)我感觉依赖已经有了
logging:
level:
org.springframework.cloud.openfeign: debug
3 测试 启动各个工程 访问一个有调用服务的生产者的url
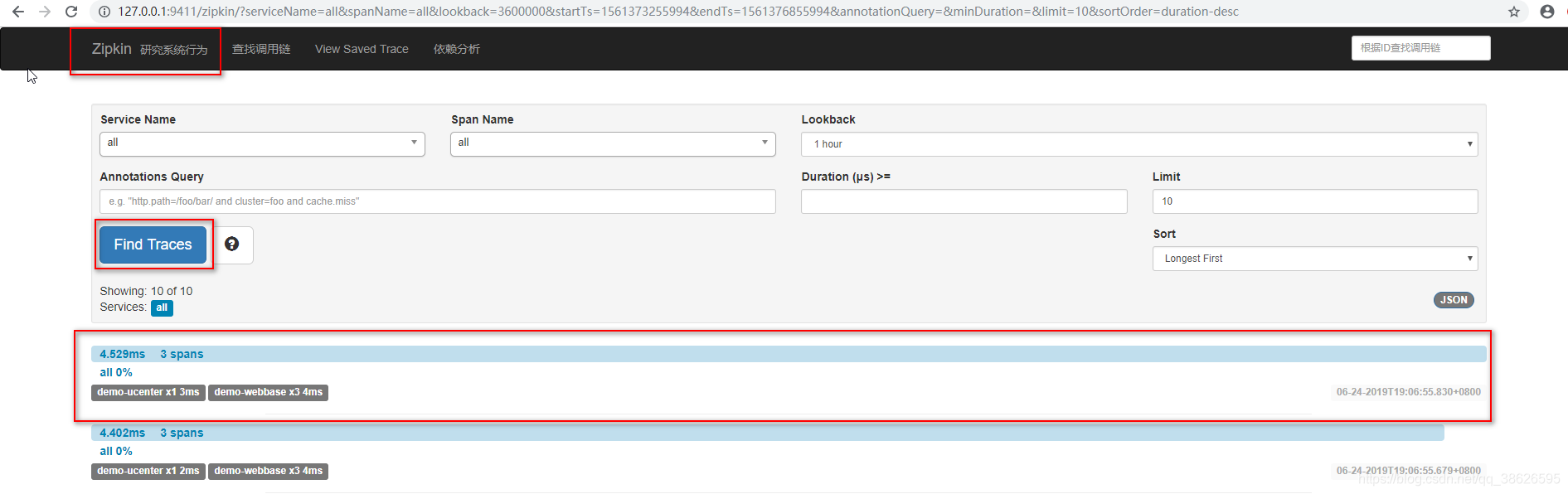
访问127.0.0.1:9411
单击Find Traces
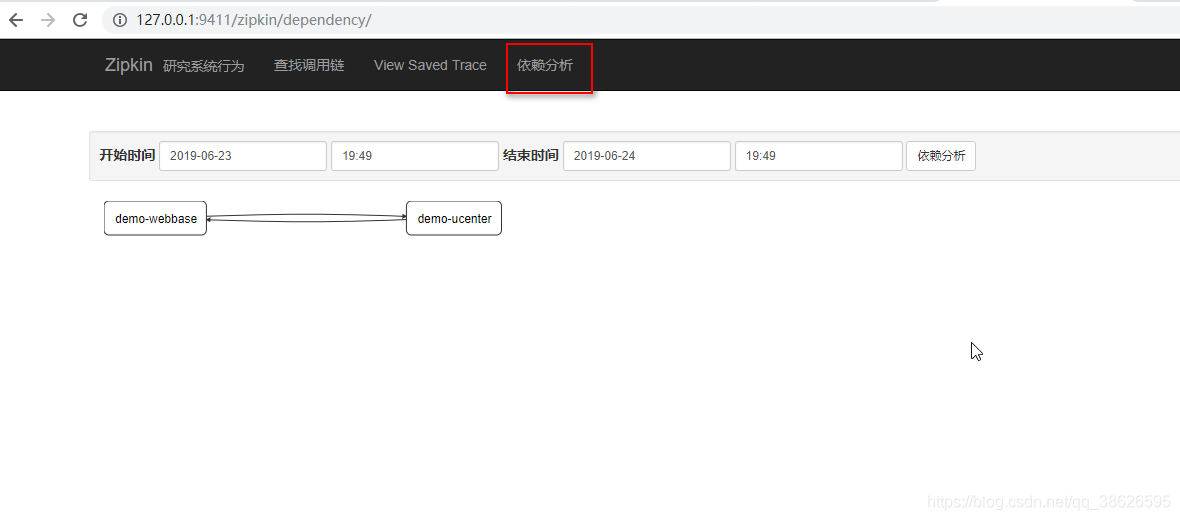
点依赖分析可以看到各个工程之间的调用关系

















 7863
7863

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









