







文章:ACL 2024
一、动机
背景:
零样本和跨领域任务:指模型在没有见过某个任务或领域的训练数据的情况下,直接去完成该任务。
神经检索模型:在语义搜索上取得进展,但在零样本和跨领域任务中仍不如传统统计方法(如 BM25)。
现有主流方法(如 MonoT5、RankT5):采用点式重排序,缺乏对多个段落间相对比较的能力,容易导致次优排序结果。
点式重排序:就是模型一个一个地评估每个候选段落/文档的相关性得分,然后根据这些得分来排序。每次只看一个段落和问题之间的关系,完全不管其他段落。这样排序模型容易把看似相似但是相关性更低的结果放到前面。
新兴的列表式重排序方法:虽有效,但存在效率低(如 DuoT5 的二次复杂度)或大模型推理成本高、信息丢失等问题(如 LLMs 面临的“中间丢失”问题)。
二、相关的工作
1.生成模型在reranker中的应用
联合编码器比双编码器的表现更好,尤其在零样本检索中。将重排序任务转化为序列生成问题,利用LLM的自回归生成能力,可以提升排序的准确性,T5架构的成功应用,将重排序视为自回归文本生成问题,已成功应用于,零样本重排序任务。
2.基于T5模型的列表式reranker的方法
MonoT5和RankT5都是在推理的时候采用点式重排序,限制了对多个段落相对关系的判断能力,
DuoT5采用了重排序,每次预测时,对两个段落进行比较,评估哪个段落更相关,但这个方法效率低。
3.列表重排序和大语言模型(LLMs)
将列表重排序(Listwise reranking)应用于大语言模型(LLMs),通常采用将多个(例如 20 个)段落作为输入,并使用滑动窗口的方法,然而这样的方法带来了更长的上下文,导致效率低和中间信息的丢失。
三、解决方法
提出一个用于列表重排序的方法,包含两个组成部分:
(1) 基本操作单元,它处理固定数量的 m 个段落,并基于 FiD 排序前 r 个段落;
(2) 该基本单元的扩展,它处理完整的 n 个段落,并基于锦标排序(tournament sort)排序前 k 个段落。
1.基本操作单元
背景知识:
FiD模型:
将将检索回来的每个passage都与question通过encoder分别编码,然后concat在一起输入decoder生成最终的回复。
传统的E-D结构的模型对每个段落进行分别编码,没有进行特征的融合,导致不能联系上下文之间的关系。
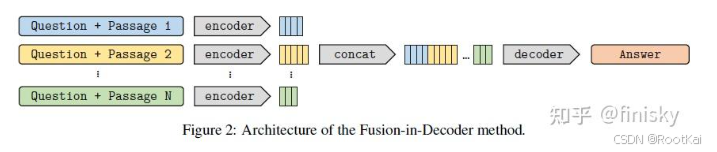
模型结构:
基本操作单元的工作流程如下:
首先, 将查询和检索到的段落还有段落的index进行拼接,如:
![]()
然后,把拼接的结果放入到编码器中进行编码,对每个段落,问题,索引拼接的结果分别编码,
![]()
最后,把这些拼接后的编码进行拼接成一个很长的单一的序列向量,
![]()
之后,把这个向量输入到Decoder中,进行自回归的生成按照相关性递增顺序排列的段落索引。
最后,只保留1~2个相关的段落。
2.扩展基本操作单元
原来的实现方法是通过一个操作的基本单元,然后通过滑动窗口,来不断的进行,滑动来找到局部的K个相关的段落,最后,在对这个K个段落,进行全局的操作单元选取最终的结果。
作者提出的新方法:使用锦标赛算法,来取代滑动窗口,提高效率
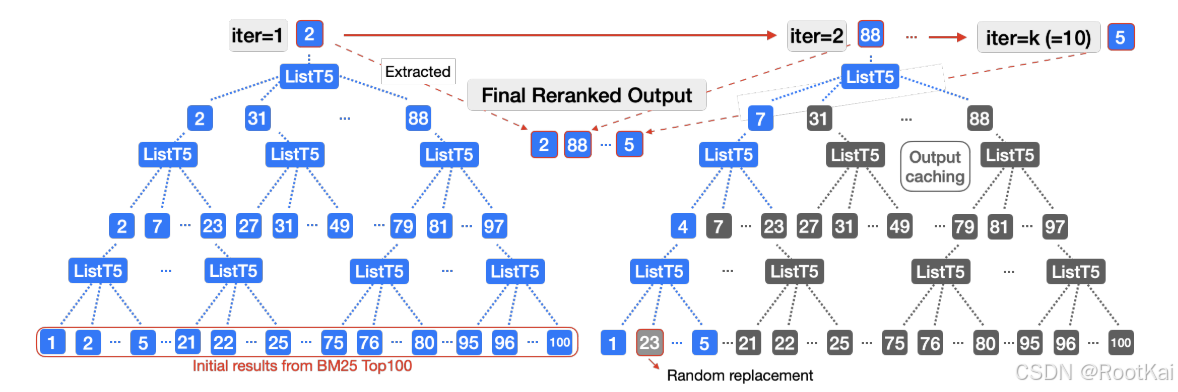
如何扩展基本操作单元,由n个段落选出k个相关的段落
就是以下两步:
-
从二叉锦标赛树扩展到m叉锦标赛树;
-
在锦标赛树的每个节点上调用基本单元m → r(第3.1节)。
四、实验
1.训练细节
使用MS MARCO段落排名数据集来训练LISTT5。
数据细节的处理:该数据集包含532,761个不同的查询和880万段落,并且具有二进制的相关性标注。由于负样本之间的相关性顺序没有提供,我们使用一个双编码器检索模型,具体是COCO-DR large(Yu等,2022),来检索Top-1000段落并为MS MARCO训练数据集中的负样本标注相关性得分。
实验结果:
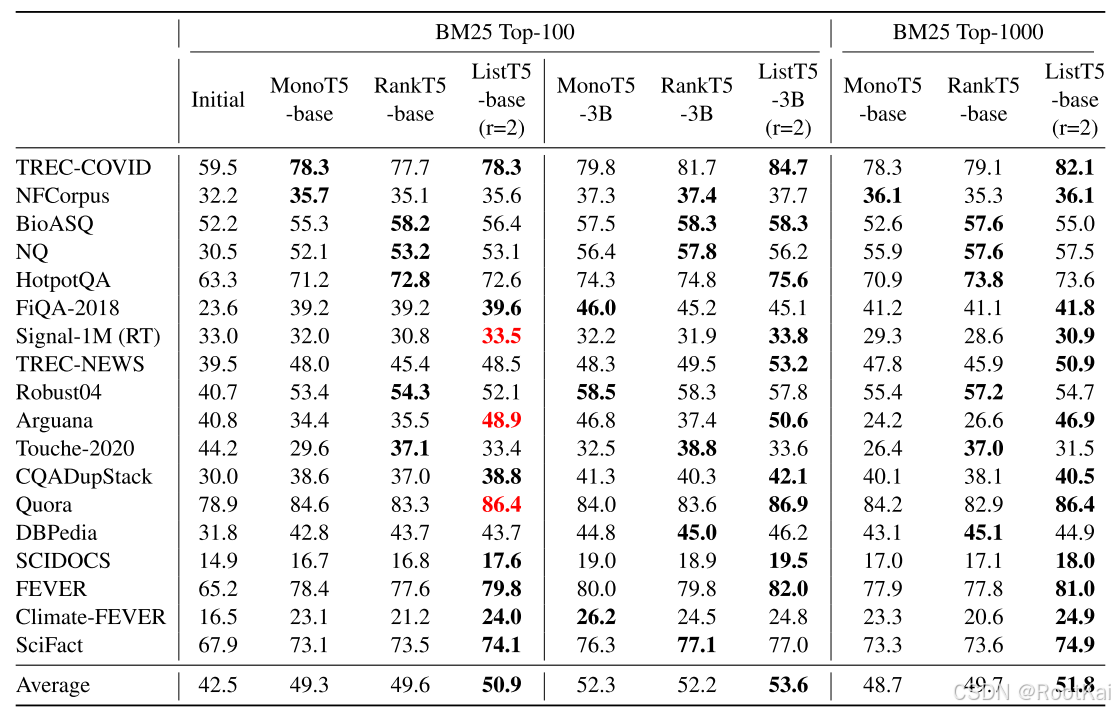
指标:NDCG@10 用来评价模型在排序任务中效果的指标,主要衡量的是,给定一个查询,排名前10的结果是不是最相关的。
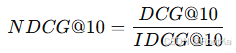



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









