







一、现状问题、解决方案
1.问题
由于缺乏逻辑感知机制,不完美的检索问题依然显著存在。
- 在精确度方面,检索系统可能返回词汇和语义上相似但间接相关的段落;
- 在召回率方面,它可能无法检索到用户查询所需的所有必要段落。
这两种情况最终都会导致不准确或不完整的LLM响应。超过60%的检索段落是间接相关或不相关的。
2.现状
从逻辑结构的角度来看,现有的RAG系统主要可以分为三种类型:
- 非结构化RAG仅采用稀疏或密集检索器。检索仅基于关键词匹配或语义向量相似性。但是不能捕捉用户查询于文段之间的逻辑关系。
- 树状结构的RAG:关注单个文档中段落的层次逻辑,但忽略了层次结构之外或跨文档的关系,而且它在不同层次之间引入了冗余信息
- 图结构的RAG:通过构建知识图谱(KGs)来表示文档,在这种结构中,实体是顶点,它们的关系是边,最理想地建模了逻辑关系。
但是,依赖于预定义的模式限制了灵活的表达能力,构建和更新知识图谱具有挑战性,且容易出现错误或遗漏、知识的三元组格式需要额外的文本化或微调。
3.解决方案
目前两种主流检索器类型:稀疏检索器:侧重于词汇相似、密集检索器:侧重于语义相似,通常时结合起来使用。
受到小世界理论(Kleinberg, 2000)或六度分隔理论(Guare, 2016)的启发,进一步利用间接相关的段落作为跳板,最终找到真正相关的段落。
提出了HopRAG一种创新的图结构RAG系统,两个阶段:
1.索引阶段:构建一个图结构的知识索引,段落作为节点,逻辑关系作为有向边,就是通过模拟用户的查询问题连接两个节点(段落),就是将提问段落和解答段落连接起来,作为逻辑跳跃的枢纽。
2.检索过程中:采用增强推理的图遍历,遵循检索、推理、修剪的三个模式,这个过程,在多跳邻域中寻找真正相关的段落,指导这个的时索引结构和LLM推理。
二、方法
1.方法表述
现有一个段落语料库P={p1,p2,...,pN}和一个查询q,这个查询需要多个段落的信息,才能得到答案。任务设计:
1.一个图结构的RAG知识库,用来存储语料库P中的多有段落,也要建模段落之间的相似性和逻辑关系。
2.一个相应的检索策略,可以从间接相关的段落跳跃到真正的相关段落,提高检索效果
3.查询q和k个查询到的段落,作为上下文C={pi1,pi2,...,pik} 的基础上,LLM生成结果。
2. 图结构索引
构建图结构索引G=(V, E),将语料库中每个段落存储在一个顶点中,得到顶点集V,在捕获段落间的逻辑关系,构建边集,这个逻辑关系,利用模拟查询来挖掘,然后利用文本的相似性进行边的合并。
1.查询模拟
利用LLM为每个段落生成两组伪查询,用来充分挖掘段落之间的逻辑关系。
两组伪查询:
1.m个出向问题:这些问题源自该段落,但无法通过段落本身回答
2.n个入向问题:这些问题的答案可以在该段落中找到
使用命名实体识别NER(.)从外向问题和内向问题中提取关键词,用来进行稀疏表示,
然后使用嵌入模型EMB(.)将这些问题嵌入到语义向量中,进行密集表示。
接着定义外部三元组(q+, k+, v+)和内向三元组(q-, k-, v-)
每个段落pi是一个顶点vi,其特征包括外向三元组、内向三元组
2.边缘合并
给定了外向和内向的三元组,通过混合检索匹配成对的三元组,通过下面的公式找到匹配的外向三元组和内向三元组,然后在匹配的两个顶点之间建立有向边。
构建有向边:
其中:
边:(目标段落回答的问题,源点和目标点关键字的并集,目标段落的语义信息)
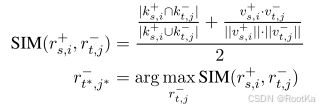
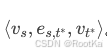
3.推理增强图遍历
为了获得更准确和完整的响应,HopRAG 的检索策略利用大模型(LLM)的推理能力,基于图结构中的逻辑关系,探索可能间接相关段落的邻域,从而跳跃到真正相关的段落通过对当前顶点 vi 的出边 ei,j 进行问题推理,并选择跳跃到最有可能的顶点 vj,我们实现了推理增强的图遍历,从而提升检索性能。
检索阶段:
首先。使用NER(.)和EMB(.)提取查询q的关键词kq和向量vq,这些信息将用于混合检索,来匹配最相似的top-k条边。对于这些边中的每个头顶点vj,初始化一个上下文队列Cquen,用来进行广度优先的局部搜索
推理阶段:
为了充分利用图上的逻辑关系,并从间接相关的顶点跳跃到真正相关的顶点,我们引入广度优先的局部搜索,该搜索利用 LLM 选择每个 Cqueue 中的 vj 最合适的邻居,并将其添加到队列尾部。
剪枝阶段:
据每个 vi 的 Hi,我们对 C′ 进行剪枝,仅保留 H 最高的 topk 个顶点,从而得到最终的上下文 C。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









