







一、现状问题、解决方案、方案不足
1.问题:
RAG往往会用过多的信息压倒LLM,而其中只有一部分可能与当前任务相关。应该遵循有效沟通的四个准则:
- 数量准则(Maxim of Quantity):提供足够的信息,但不要多余;
- 质量准则(Maxim of Quality):要真实;避免提供虚假或未经支持的信息;
- 关系准则(Maxim of Relation):要相关,只分享与讨论相关的信息;
- 方式准则(Maxim of Manner):要清晰、简洁、有条理;避免模糊和歧义。
2.解决方案
提出一种简单的无监督方法,将语用学注入到任何的RAG框架中:
1.识别出在RAG检索的文档池中,哪些句子与当前的问题最相关(关联准则),并涵盖了输入问题中涉及的所有主题且不多于此(数量准则和方式准则);
2.在将这些句子提供给大语言模型(LLM)之前,在它们原始的上下文中对这些句子进行高亮标注。如下:

“<evidence>”标记进行高亮显示
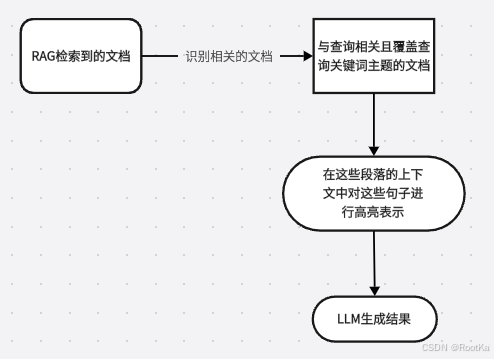
方法流程图
3.方案不足
1.当问答任务涉及算术运算或包含诸如双重否定等细微差别时,语用学的效果较差。
2.如果首先通过DPR检索到一组模糊的上下文,其中查询缺乏消歧信息,并且可能得出多个合理的答案,我们的方法在识别合适的证据句子进行突出显示时会遇到困难。
二、方法:将回退推理与语用检索相结合
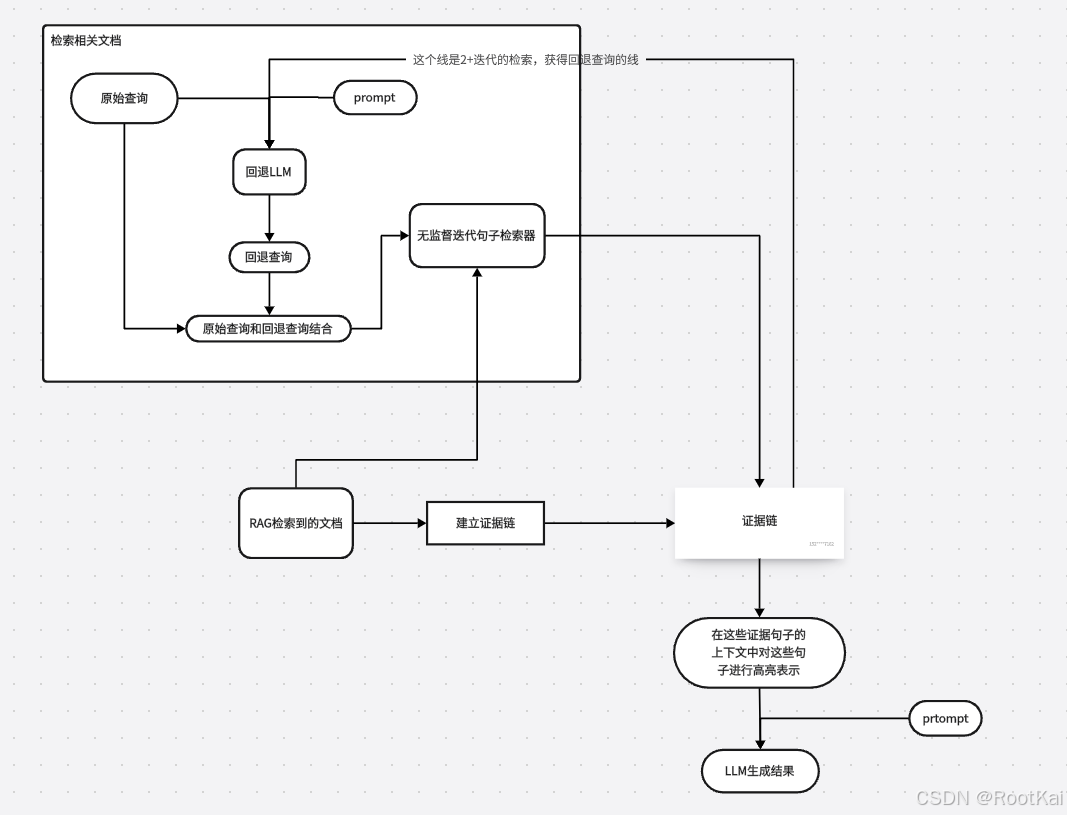
在本篇文章中,将作者提出的方法应用于通过密集段落检索器(DPR)检索到的文档集合。
采用Yadav提出的无监督迭代句子检索器,来识别通过DPR检索到的RAG文档中的重要句子:
具体方法:
1.给定一个查询和通过DPR检索到的相关段落,用一个LLM将查询生成一个更抽象的版本,然后和原来的查询连接起来
2.在第一次句子检索迭代中,将连接后的查询用于从相应的段落中检索一组相关的证据句子
3.在接下来的检索迭代中,查询在次被重新表述,用这个查询去检索上面检索迭代中为检索到的查询中的关键词,然后一直重复这个过程,直到,查询中的关键词都被覆盖到。
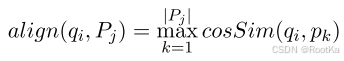
把每次检索到的句子和 之前检索到的句子进行聚合,构成证据链,然后把这些证据句子插入到原始的上下文段落中,用一个标记标注(是怎么让LLM知道这个证据标注的????), 最后,再把处理后的DPR检索到的文档传到LLM中生成答案
1.回退查询扩展
采用回退提示技术:就是好将查询用LLM变成更加抽象的问题,得到回退查询,回退查询代表了一种更加概括的查询表达,把回退查询作为迭代检索的初始输入,就会生成一个多样性且相关的候选证据集。对于多选题,为每个选项生成回退答案选项,并将其与回退查询结合,指导检索
2.并行迭代证据检索
将查询标记与知识库段落中每个句子的标记进行对齐,通过基于密集嵌入上的余弦相似度得分(方程1),从知识库段落中选择与查询标记最相似的标记,来构建证据句子。(是用这些token一起构成证据句子,还是包含这些token的句子作为句子?????待解决)
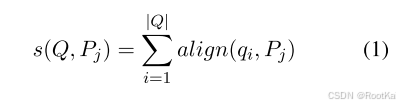
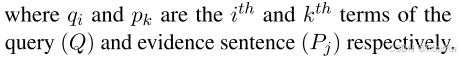
查询重构是由剩余词项驱动的,就是在多跳检索前i次,迭代中检索到的证据句子子集未覆盖的查询的关键词。公式如下;
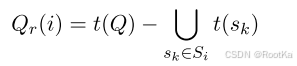
覆盖的概念是基于软匹配对齐的:就是一个查询词项的余弦相似度大于某个阈值M(作者设置的值M=0.98),就说这个查询此项就被包含在证据词项的集合中了。查询重构的目标就是通过检索到的证据链最大化对查询关键词的覆盖。
查询存在歧义时,通过动态地将所有先前检索到的证据句子中的术语扩展到当前查询中来缓解这种歧义,如果查询中未覆盖的术语数量低于 T7(作者设置的值T=4),这也符合格赖斯合作准则中的最后一条准则(方式准则)。
方法流程图
三、评估与数据集
数据集:
ARC-Challenge(多项选择推理数据集)
PubHealth(公共健康领域的事实验证数据集)
PopQA(开放域问答数据集)的测试集上评估方法
评估指标:
对于封闭任务(ARC-Challenge、PubHealth)评估准确率
对于短文本生成任务(PopQA),评估指标基于模型生成的答案是否包含黄金答案
实验细节:
实验结果(针对 Mistral-7B-Instruct v0.1、Alpaca-7B 和 Llama-2-7B)与其他研究(如 Self-RAG(Asai 等,2024)、CRAG(Yan 等,2024)以及 Speculative RAG)报告的结果有所不同
我们的实验结果与 Self-RAG、CRAG 等研究不同,主要原因如下:
- 评估标准:我们采用“包含”原则,即如果生成文本包含正确答案的子字符串,则认为正确。
- 检索段落数量(Top-K):对不同模型设置不同的 K 值,例如 Llama-2-7B 设为 11,Alpaca-7B 设为 9,以适应上下文窗口大小。
- 提示工程:优化提示,使其更符合指令微调格式,特别针对 Alpaca-7B 和 Llama-2-7B-chat。
- 回溯 LLM:所有实验中均使用 Mistral-7B-Instruct v0.1 作为回溯模型。
表 2 显示,将语用提示整合到 RAG(检索增强生成)中可以提升相较于 DPR(稠密段落检索)的性能:
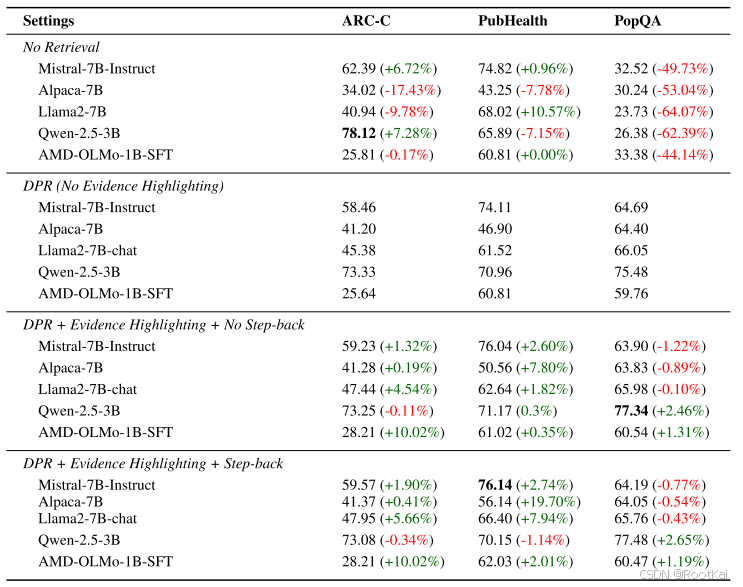
表格解释:
无检索(No Retrieval) 设定下,我们不检索任何文档,仅测试 LLM 的参数化知识
DPR(无证据高亮) 指的是在每个查询的前 K 个段落中不对任何证据句进行高亮,直接提供给 LLM
DPR + 证据高亮 + 无回溯 设定中,我们使用“<evidence>” 标记对 DPR 检索的段落进行证据高亮
DPR + 证据高亮 + 回溯 设定在前者基础上,引入回溯提示(Step-back prompting),通过重构查询和答案选项进一步增强检索效果
LLM的选择:
使用较早的语言模型,以降低数据污染的风险
排除了 DeepSeek-R1-Distill-Llama-70B(DeepSeek-AI 等,2025),因为在 无检索(No Retrieval) 设定下,该模型在 ARC-Challenge 上的准确率达到了 90%,明显表明存在数据泄露。
四、方法挑战
1.评估仅限于与标准稠密段落检索器(DPR)和 BM25 基准的对比,方法有潜力与更复杂的 RAG 系统集成
2.未全面的评估应包括更广泛的单跳和多跳任务
3.有一些场景我们的方式尚未涵盖,例如处理语言现象(如否定)、数学推理任务以及解决检索到的模糊上下文
4.它是无监督的,且查询重构主要由词袋模型驱动,通过使用 LLM 或采用弱监督策略可以简单地改进查询重构
专业术语解释
[1]“回退版本”指的是对原始查询的简化或更高层次的表达
[2]"初始化种子"指的是在开始一个过程时,所使用的初步输入或起始点。在这种情况下,"初始化种子"是指使用回退查询作为起点来启动迭代检索过程。
[3]语用学是语言学的一个分支,研究语言在实际交际中的使用方式,关注语言的意义如何在特定情境中产生。它探讨了说话者如何通过语言表达意图、理解对方的含义,以及语言在不同社会文化背景中的使用规则。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









