







一、python
1.assert
assert 是 Python 语言中的断言语句,主要用于在代码运行时检查某个条件是否成立。如果条件为 False,assert 语句会抛出 AssertionError,从而终止程序执行。这通常用于调试和测试,以确保程序在特定条件下正确运行。
assert x > 0, "x should be positive"
如果 x 的值小于或等于 0,会抛出一个 AssertionError,并显示消息 "x should be positive"2.类
#类的定义
class ClassName:
"""属性和方法"""
#类对象
"""
类对象支持两种操作:属性引用和实例化。
属性引用使用和 Python 中所有的属性引用一样的标准语法:obj.name。
类对象创建后,类命名空间中所有的命名都是有效属性名。
"""
class MyClass:
"""一个简单的类实例"""
i = 12345
def f(self):
return 'hello world'
# 实例化类
x = MyClass()
# 访问类的属性和方法
print("MyClass 类的属性 i 为:", x.i)
print("MyClass 类的方法 f 输出为:", x.f())
#构造方法
"""
类有一个名为 __init__() 的特殊方法
该方法在类实例化时会自动调用
def __init__(self):
self.data = []
当然, __init__() 方法可以有参数,参数通过 __init__() 传递到类的实例化操作上
class Complex:
def __init__(self, realpart, imagpart):
self.r = realpart
self.i = imagpart
x = Complex(3.0, -4.5)
print(x.r, x.i) # 输出结果:3.0 -4.5
"""
"""
self 代表类的实例,而非类
类的方法与普通的函数只有一个特别的区别——它们必须有一个额外的第一个参数名称, 按照惯例它的名称是 self。
class Test:
def prt(self):
print(self)
print(self.__class__)
t = Test()
t.prt()
<__main__.Test instance at 0x100771878>
__main__.Test
注意:elf 代表的是类的实例,代表当前对象的地址,而 self.class 则指向类。
self 不是 python 关键字,我们把他换成 runoob 也是可以正常执行的:
"""
#类的方法
"""
在类的内部,使用 def 关键字来定义一个方法,与一般函数定义不同,类方法必须包含参数 self, 且为第一个参数,self 代表的是类的实例。
"""
3.super
单继承
在单继承中 super 就像大家所想的那样,主要是用来调用父类的方法的。4.list.append()
"""
list.append() 是用来向列表(list)末尾添加一个元素的方法
"""5.列表推导式
列表推导式(List Comprehension)是一种在 Python 中创建列表的简洁方式。它允许你在一行代码中构建列表,而不需要使用传统的循环结构。列表推导式的语法通常如下:
[nn.Linear(10, 10) for i in range(10)]
"""
这段代码是用 Python 的列表推导式创建一个包含 10 个线性层的列表。
"""
[expression for item in iterable if condition]
expression:对每个元素执行的表达式。
item:迭代变量。
iterable:可迭代对象,如列表、元组、字符串等。
condition(可选):过滤条件,只有满足条件的元素才会被包含在最终的列表中6.isinstance
isinstance 是 Python 中用于检查一个对象是否是某个特定类或其子类的实例的内置函数。它的基本语法如下:
isinstance(object, classinfo)
object:你要检查的对象。
classinfo:可以是一个类或类元组,表示你希望检查的类型。
7..zip
zip() 是一个非常有用的 Python 函数,它可以将多个可迭代对象(比如列表、元组)打包成一个个元组,元组中的元素来自不同的可迭代对象,按照它们的位置进行配对。
用法:
# 示例:将两个列表打包成一个
list1 = [1, 2, 3]
list2 = ['a', 'b', 'c']
result = zip(list1, list2)
print(list(result)) # 输出:[(1, 'a'), (2, 'b'), (3, 'c')]
解包:
你可以使用
zip(*iterables)来解压已经打包的可迭代对象。
zipped = [(1, 'a'), (2, 'b'), (3, 'c')]
list1, list2 = zip(*zipped)
print(list1) # 输出:(1, 2, 3)
print(list2) # 输出:('a', 'b', 'c')
-
zip()将每个可迭代对象的第一个元素打包成一个元组,接着将第二个元素打包成一个元组,依此类推。如果可迭代对象的长度不同,zip()会在最短的可迭代对象被耗尽时停止打包。 -
不同长度的可迭代对象:
list1 = [1, 2, 3]
list2 = ['a', 'b']
result = zip(list1, list2)
print(list(result)) # 输出:[(1, 'a'), (2, 'b')],第三个元素被忽略
8.with
Python 中的
with语句用于包裹执行代码块,以便于资源管理,比如文件操作、数据库连接等。使用with语句可以确保代码块执行完毕后,资源能够被正确地关闭或清理,即使在代码块中发生异常也是如此。
语法格式
with expression [as variable]:
block其中:
expression返回一个支持上下文管理协议(__enter__和__exit__方法)的对象。as variable(可选)用于接收__enter__方法返回的值。block代码块是with语句控制的作用范围,执行完后会自动调用__exit__释放资源。
9.set
set()函数可以将一个可迭代对象转换为一个集合(set)。集合是一个无序的、不包含重复元素的数据结构。如果你有一个列表(list)、元组(tuple)、字符串(string)或其他任何可迭代对象,并且你想要创建一个包含这些元素但不包含重复项的集合,你可以使用set()函数。
set是一个非常灵活的数据结构,它在需要快速成员测试、去除重复项或执行集合运算时非常有用。由于集合是无序的,所以它不支持索引操作
10.read()
在Python中,当你使用
read()方法时,如果没有指定参数,它会读取整个文件的内容,并将其作为一个字符串返回。
11.enumerate()
enumerate()是一个内置函数,它用于将一个可迭代对象(如列表、元组、字符串等)组合为一个索引序列,同时列出数据和数据下标。这在进行循环遍历时非常有用,尤其是当你需要跟踪元素的索引时。
12.//
在Python中,
//是一个内置的算术运算符,称为地板除(floor division)。地板除与普通的除法运算符/不同,它返回的是除法操作的整数部分,即向下取整的结果。
13.range()
在Python中,
range(0, num_examples, batch_size)是一个用于生成数字序列的函数调用,它可以按指定的步长(即batch_size)生成从0到num_examples范围内的数字。语法解释
range(start, stop, step):生成一个从start到stop(不包括stop)的数字序列,按step增量。
0:起始值,从 0 开始。
num_examples:结束值,循环会在到达这个值前停止。
batch_size:步长,每次递增的量。语法:
setattr(object, name, value)
- object:你想要设置属性的对象。
- name:属性名,作为字符串传递。
- value:属性的值。
示例:
class Person: pass p = Person() # 使用 setattr 设置 p 对象的 'name' 属性 setattr(p, 'name', 'Alice') print(p.name) # 输出: Alice # 使用 setattr 动态设置属性 setattr(p, 'age', 25) print(p.age) # 输出: 25
14.setattr
在 Python 中,
setattr是一个内置函数,用于动态地设置对象的属性。setattr的常见用法是允许在运行时改变或添加属性,而不需要在代码中硬编码每个属性名。
15.getattr
getattr:动态获取对象的属性
16. raise NotImplementedError
这里
forward方法抛出了NotImplementedError,表示Encoder是一个抽象类或接口,不能直接使用。具体的子类需要实现这个方法,定义实际的前向传播逻辑。
17.hasattr()
是 Python 中的一个内置函数,用于检查对象是否具有给定名称的属性。
hasattr(object, name)object:要检查的对象。name:要检查的属性名称,它是一个字符串。
18.del
一个内置的语句,用于删除对象。
del可以删除对象的属性、列表的元素、字典中的键值对,甚至是整个变量。
class MyClass:
def __init__(self):
self.my_attr = 42
obj = MyClass()
del obj.my_attr # 删除 obj 的属性 my_attrdel value 用于删除 self.name_mapping 字典中每个键对应的值。这通常用于清理或重置字典,特别是在需要重新初始化字典内容时。
19.全局变量在类内部访问
在 Python 中,全局变量可以在类的内部方法中访问,但有一些注意事项:
- 直接访问:如果全局变量在类的方法中只读取而不修改,可以直接访问。
- 修改全局变量:如果需要在类的方法中修改全局变量,需要使用 global 关键字声明该变量为全局变量
20.hasattr()
是 Python 中的一个内置函数,用于检查对象是否包含某个属性。这个函数接受两个参数:第一个参数是对象,第二个参数是字符串形式的属性名。如果对象包含这个属性,
hasattr()返回True;否则返回False。
21.return_dict: Optional[bool] = None
在Python中,
return_dict: Optional[bool] = None这种写法是函数参数定义的一部分,它包含了几个关键信息:
参数名称:
return_dict是参数的名称,这是函数调用时传递值的标识符。类型注解:
Optional[bool]是参数的类型注解。bool表示这个参数期望的值是一个布尔类型(True或False)。Optional是一个来自typing模块的泛型,表示参数可以是布尔类型,也可以是None。这意味着这个参数是可选的,并且可以接受布尔值或None。默认值:
= None指定了参数的默认值是None。这意味着如果在函数调用时没有提供return_dict参数,它将自动被设置为None。综合来看,
return_dict: Optional[bool] = None表示return_dict是一个可选参数,它可以被设置为True、False或者不设置(默认为None)。
22.条件表达式
<value_if_true> if <condition> else <value_if_false>
<value_if_true>:当<condition>为True时返回的值。<condition>:一个布尔表达式,其结果为True或False。<value_if_false>:当<condition>为False时返回的值。
23.def string_generator() -> Generator[str, Any, None]:
这是 Python 中的类型注解(type hint)写法,通常用来指示一个函数的返回类型。具体来说:
Generator[str, Any, None]表示一个生成器(generator)对象,它具有三个部分:
str:生成器产生的每个值的类型是str(字符串)。Any:生成器可以接收的输入值的类型是Any,也就是可以是任何类型。None:表示生成器在完成时不会返回任何值,即它没有返回值(None表示没有返回)。- Union[Tuple, CausalLMOutputWithPast]:
Union[Tuple, CausalLMOutputWithPast]:
使用Union表示返回值可以是多种类型之一。在这个例子中,函数f的返回值既可以是一个Tuple(元组),也可以是一个CausalLMOutputWithPast类型。
CausalLMOutputWithPast:
这是 Hugging Face Transformers 中用于包装语言模型输出的一个类。它通常包含logits、past_key_values等字段。
24.yield
yield的作用
创建生成器:
- 使用
yield的函数不是普通函数,而是生成器函数。- 生成器函数不会一次性返回所有结果,而是每次执行到
yield时返回一个值并暂停。逐步返回值(懒加载):
yield会逐步“生成”值,适用于处理大数据或流式数据。- 调用生成器时,返回的是一个生成器对象,需要用迭代器(如
for循环)或显式调用next()来获取值。生成器的执行流程
1. 生成器函数是什么?
生成器函数是使用
yield关键字定义的函数,它和普通函数的主要区别是,生成器函数不会一次性返回所有的结果,而是每次通过yield暂停并返回一个值,然后等待下一次请求时从暂停的地方继续执行。2. 暂停和恢复
暂停:当生成器函数执行到
yield语句时,它会返回一个值给调用者,但不会结束函数的执行,它会暂停在yield处。此时,函数的状态(变量的值、执行位置等)会被“保存”。恢复:当调用者(比如通过
next()或for循环)请求下一个值时,函数会从上一次暂停的地方恢复执行,继续执行后面的代码,直到遇到下一个yield或函数结束。3. 关键点:生成器函数的执行是分段进行的,每次只执行一部分代码,直到遇到
yield,然后暂停等待下一次请求。
25.类型注解(type annotation)
a(name: str)是 Python 中的一种 类型注解(type annotation),用于表明函数参数的预期类型。
name: str表示函数参数name的预期类型是str(字符串)。- 类型注解本身不会影响代码的运行,但它能帮助开发者更清楚地理解代码,同时为静态类型检查工具(如 MyPy)提供支持。
26.为什么打印实例化对象显示是字典
这是因为在
Hugging Face的Transformers库中,GenerationConfig的实例是一个对象,但它实现了特殊的方法(如__repr__或__str__),使得它可以以字典形式呈现其内部配置。当你打印default_config时,它会显示为类似字典的格式,但实际上仍是GenerationConfig的实例。
27.**kwargs
在 Python 中,
**kwargs是一种用于函数定义的特殊语法,它允许函数接受任意数量的关键字参数(keyword arguments)。kwargs是一个以字典形式存储所有传入的关键字参数的变量。
28.生成器函数(Generator Function)
生成器函数(Generator Function)是 Python 中一种特殊的函数,用于生成迭代器(iterator)。与普通函数不同,生成器函数通过
yield关键字返回值,并在每次暂停时保留其状态,能够逐步生成值。这使得生成器在处理需要大量计算或大规模数据集时非常高效。
生成器函数的特点
yield关键字:
yield用于生成值,并暂停函数的执行。- 下次恢复执行时,会从上次暂停的地方继续运行。
惰性求值(Lazy Evaluation):
- 生成器不会一次性生成所有值,而是按需生成,这对于处理大数据特别有用。
保存状态:
- 每次调用生成器时,它都会记住上次执行的状态,包括局部变量和执行位置。
返回生成器对象:
- 调用生成器函数返回一个生成器对象,而不是普通的返回值。
生成器函数和生成器对象的区别
生成器函数:
- 包含
yield关键字的函数会被定义为生成器函数。- 调用生成器函数时,并不会立即执行函数内部的代码,而是返回一个生成器对象。
生成器对象:
- 生成器对象是一种特殊的可迭代对象(iterator)。
- 每次调用生成器对象(如
next())时,会从上一次中断的地方继续执行,直到遇到下一个yield。
29.嵌套函数
嵌套函数(Nested Function)指的是在一个函数内部定义的另一个函数。嵌套函数与普通函数的主要区别在于它的作用域受外部函数限制,通常用于封装局部逻辑或增强功能。
嵌套函数的特点
作用域局限性:
- 嵌套函数只能在其外部函数内部访问,外部代码无法直接调用。
封装逻辑:
- 将辅助功能封装在嵌套函数中,避免外部代码的干扰,提升代码可读性和组织性。
访问外部变量:
- 嵌套函数可以访问外部函数的变量(闭包特性),但只能读取不可变变量,除非显式声明。
闭包(Closure)支持:
- 嵌套函数如果被返回或作为参数传递,可能形成闭包,保持外部函数的状态。
def outer_function(a):
b = 10
def 内部函数():
return a + b # 嵌套函数可以访问外部函数的变量
return 内部函数()# 返回嵌套函数30. @staticmethod
@staticmethod是 Python 中的一种装饰器,用于定义一个静态方法(Static Method)。静态方法属于类,但不依赖于类实例,因此可以直接通过类名调用,而不需要创建类的对象。
特点:
-
不依赖于类实例:
- 静态方法与类实例无关,因此方法内部不能访问
self(实例)或cls(类本身)。 - 它类似于一个普通函数,但放在类的作用域内,以便逻辑上与类相关联。
- 静态方法与类实例无关,因此方法内部不能访问
-
通过类名或实例调用:
- 可以通过类名直接调用,也可以通过类的实例调用。
-
没有隐式的第一个参数:
- 普通方法的第一个参数是
self,类方法的第一个参数是cls,静态方法没有任何隐式参数。
- 普通方法的第一个参数是
31.seq_k.data.eq(0)
这一行代码的作用是检查张量
seq_k中每个元素是否等于0,并返回一个 布尔张量。
解释
seq_k:
- 是一个二维张量,形状为
(batch_size, len_k),表示键序列。
.data:
- 访问
seq_k的原始数据张量。在 PyTorch 中,.data通常用于直接访问张量的数据(虽然新版 PyTorch 中建议直接使用张量本身)。
.eq(0):
- 比较
seq_k中的每个元素是否等于0。- 如果某个位置的值等于
0,对应位置返回True,否则返回False。结果形状:
- 返回的布尔张量形状与
seq_k相同,即(batch_size, len_k)。
生成的布尔张量可以用于构建 Mask(遮掩矩阵),用来忽略注意力计算中的填充位置,从而避免对无意义的填充值进行计算。
32.isinstance
isinstance(object, classinfo)参数说明:
object:要检查的对象。classinfo:可以是一个类型、类,或者由类型和类组成的元组。返回值:
- 如果
object是classinfo的实例,返回True。- 否则,返回
False。
33.json.dumps
json.dumps是 Python 标准库json模块中的一个方法,用于将 Python 对象转换为 JSON 格式的字符串。简单来说,它把 Python 数据转成 JSON 数据。
json.dumps(obj, *, skipkeys=False, ensure_ascii=True, check_circular=True, allow_nan=True, cls=None, indent=None, separators=None, default=None, sort_keys=False)常见参数
obj: 要转换的 Python 对象。indent: 设置缩进级别,使输出的 JSON 更易读(美化 JSON)。ensure_ascii: 默认True,将非 ASCII 字符转为 Unicode 转义字符。如果设置为False,则输出原始字符。sort_keys: 如果为True,字典的键会按升序排序。separators: 定义 JSON 中键值对和项之间的分隔符,默认值是(',', ': ')。
34. getattr
getattr是 Python 内置的一个函数,用于获取对象的属性值。其常见的用法如下:
getattr(object, name[, default])参数说明:
object: 要查询的对象。name: 属性的名称(字符串类型)。default(可选): 如果指定的属性不存在,则返回该默认值;若不提供此参数且属性不存在,会引发AttributeError。
二、pytorch
1.torch.zeros_like()
用于创建一个与给定张量形状相同的全零张量。它会根据输入张量的数据类型和设备(CPU 或 GPU)来自动匹配这些属性
参数
input: 要基于其形状创建全零张量的输入张量。
dtype: 可选参数,指定输出张量的数据类型。如果没有提供,将使用输入张量的数据类型。
device: 可选参数,指定输出张量所在的设备。如果没有提供,将使用输入张量所在的设备。
2.torch.randn
用于生成具有正态分布(均值为 0,标准差为 1)的随机数张量
size: 可以是一个整数或一个整数组成的元组,指定返回张量的形状。例如,torch.randn(2, 3) 创建一个形状为 (2, 3) 的随机张量。3.(torch.randa(X.shape) > droup
torch.rand(X.shape): 生成一个与 X 相同形状的随机张量,其值在 [0, 1) 范围内。
random_tensor > drop: 比较随机张量中的每个元素是否大于阈值 drop,返回一个布尔张量4.
nn.Linear
nn.Linear 层可以处理任意维度的输入张量,只要输入张量的最后一维(即特征维度)与 in_features 参数相匹配。这是因为 nn.Linear 层在内部实现了对输入张量的批处理和维度扩展,以支持批量数据的线性变换。
"""
PyTorch 中用于创建线性(全连接)层的类,通常用于神经网络的构建。它可以将输入张量与权重矩阵进行线性变换,并加上偏置项。
"""
"""
基本用法
nn.Linear 的构造函数需要两个参数:
in_features: 输入特征的维度(输入个数)。
out_features: 输出特征的维度(输出个数)。
"""
"""
在 PyTorch 中,nn.Linear 类的实例(如 linear_layer)实现了 __call__ 方法,这使得它可以像函数一样被调用。下面是对这一机制的详细解释:
1. __call__ 方法
当你调用一个对象(例如 linear_layer(input_tensor)),Python 实际上是在调用该对象的 __call__ 方法。在 PyTorch 的 nn.Module 类中(nn.Linear 是其子类),__call__ 方法会自动处理前向传播的逻辑。
2. 前向传播(前向传播说白了就是在计算方程的结果)
在 nn.Linear 的实现中,当你传入一个张量(如 input_tensor)时,__call__ 方法会执行以下操作:
计算输出: 将输入张量与线性层的权重矩阵相乘,并加上偏置项。这是一个线性变换,可以用公式表示为:
output=input⋅weightsT+bias
output=input⋅weightsT+bias
返回结果: 最后返回计算得到的输出张量。
"""5.nn.CrossEntropyLoss
"""概念"""
"""
PyTorch 中用于多类分类任务的损失函数。它结合了 nn.LogSoftmax 和 nn.NLLLoss,通常用于训练神经网络以解决分类问题
"""
"""参数:"""
"""
weight: 一个可选的张量,用于给不同类别分配不同的权重,帮助处理类别不平衡问题。
ignore_index: 指定一个类别索引,该索引对应的样本将被忽略在损失计算中。
reduction: 指定损失的归约方式,取值可以是:
'none': 不进行归约,返回每个样本的损失。
'mean': 计算平均损失(默认)。
'sum': 计算总损失。
"""
"""
使用 nn.CrossEntropyLoss(reduction='none') 时,你需要传入真实标签和预测标签(logits)。
具体要求
预测标签(logits):
形状为 (N, C),其中 NN 是批量大小,CC 是类别数。注意,这些 logits 是未经过 Softmax 的原始输出。
真实标签:
形状为 (N,),包含每个样本对应的真实类别索引
"""6.torch.zeros
PyTorch 中用于创建一个全零张量的函数。它可以接受多个参数,以指定输出张量的形状和数据类型。
torch.zeros(size, dtype=None, device=None, requires_grad=False)
- size (tuple): 输出张量的形状,可以是一个整数或一个整数元组。例如,
(2, 3)表示创建一个 2 行 3 列的张量。- dtype (torch.dtype, optional): 指定张量的数据类型,例如
torch.float32或torch.int64。默认为torch.float32。- device (torch.device, optional): 指定张量所在的设备(如 CPU 或 GPU),例如
'cuda:0'或'cpu'。默认为当前设备。- requires_grad (bool, optional): 如果设置为
True,则会记录此张量的操作,以便后续进行自动求导。默认值为False。
7.K.shape
用于获取张量
K的形状。这个属性返回一个表示张量各维度大小的元组print(K.shape[0]) # 输出: 3 (第一维的大小) print(K.shape[1]) # 输出: 4 (第二维的大小)
8.net.eval()
net.eval()不是我们自己写的模型中特有的函数,而是 PyTorch 中nn.Module类的一个方法。任何继承自nn.Module的类(包括你自己定义的模型)都可以使用这个方法。具体说明:
继承自
nn.Module:
- 当你定义一个自己的模型类时,通常会继承
nn.Module。- 在这个过程中,你的模型就自动拥有了
train()和eval()方法。调用方法:
net.train()用于将模型设置为训练模式。net.eval()将模型设置为评估模式。
9..cpu()
- 这个方法将张量从当前设备(例如 GPU)移动到 CPU 上。PyTorch 支持在 GPU 上加速计算,但有时需要将结果移回 CPU 以便进一步处理或可视化。
- 如果张量已经在 CPU 上,调用
.cpu()不会有任何影响
10..tolist()
在PyTorch中,可以使用
.tolist()方法将张量转换为列表。这适用于带有一个元素的张量,例如标量。对于多维张量,.tolist()会将张量的各个维度转换为嵌套列表
11..numpy()
在PyTorch中,可以使用
.numpy()方法将Tensor转换为NumPy数组,前提是Tensor包含的数据类型必须是可以被NumPy支持的类型。如果Tensor在GPU上,需要先将其移动到CPU,然后才能转换为NumPy数组。
# 假设tensor在GPU上
tensor = tensor.cpu()
numpy_array = tensor.numpy()
12.
12.argmax:一句话概括,返回最大值的索引。
13. nn.Conv2d
在 PyTorch 中,
nn.Conv2d是用于定义二维卷积层的一个模块,输入是四维的参数解释
in_channels=1:
- 输入通道数为1,这通常表示输入数据是单通道(例如灰度图像)。
out_channels=1:
- 输出通道数为1,表示卷积层将输出一个特征图。
kernel_size=(1, 2):
- 卷积核的大小为1行2列。这意味着卷积将在高度为1的范围内滑动,并在宽度上覆盖2个元素。
bias=False:
- 这个参数表示不使用偏置项。在很多情况下,偏置项可以帮助模型学习更复杂的函数,但有时为了简化模型或在某些特定的网络结构中,可以选择不使用偏置。
14.torch创建张量维度问题
在使用
torch.tensor()创建张量时,外层的方括号[]实际上是用来表示张量的层次结构,而不是张量的维度。
15.torch.rand()
torch.rand是 PyTorch 中用于生成一个包含随机数的张量的函数。生成的随机数在区间 [0,1)内,服从均匀分布。语法:
torch.rand(*size, out=None, dtype=None, layout=torch.strided, device=None, requires_grad=False)
- size: 定义输出张量的形状,使用整数指定每个维度的大小,例如
(3, 4)表示生成一个 3 行 4 列的张量。- out: 可选,用于存储输出的张量。
- dtype: 指定返回张量的数据类型,默认是
torch.float32。- layout: 张量布局,默认是
torch.strided。- device: 指定生成的张量存储的设备(如
cpu或cuda)。- requires_grad: 如果设置为
True,则会为计算图记录操作,适用于自动求导。
16..reshape()
.reshape()是 PyTorch 中用于改变张量形状的方法。它允许你重新安排张量的维度,而不改变其数据。reshape()返回一个新的张量在 PyTorch 中,使用
.reshape()方法通常不会重新开辟内存空间来存放新张量,而是返回一个视图(view),这个视图共享原始数据的内存。这意味着,如果你对原始张量进行修改,可能会影响到通过.reshape()得到的张量
17.torch.stack()
torch.stack是一个非常有用的函数,用于将多个张量沿着一个新维度进行堆叠。它与torch.cat不同,因为torch.cat是在现有的维度上连接张量,而torch.stack则是增加一个新的维度。指定维度
你可以通过
dim参数指定堆叠的维度。例如,如果希望在第 0 维堆叠:# 创建几个张量 tensor1 = torch.tensor([1, 2, 3]) tensor2 = torch.tensor([4, 5, 6]) tensor3 = torch.tensor([7, 8, 9]) # 使用 torch.stack 将它们堆叠在一起 stacked_tensor = torch.stack((tensor1, tensor2, tensor3)) tensor([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
18.torchvision.transforms.Resize
torchvision.transforms.Resize是 PyTorch 的 torchvision 库中的一个转换类,用于调整图像的大小。它通常用于预处理图像数据,以便将不同尺寸的图像标准化为相同的尺寸。主要功能
- 调整大小:将输入图像的高度和宽度调整到指定的大小。
- 保持比例:可以选择保持图像的宽高比,避免图像变形。
参数
size:可以是一个整数或一个元组。
- 如果是整数,例如
size = 256,则图像会被调整为256 x 256。- 如果是元组,例如
size = (256, 128),则图像会被调整为指定的高度和宽度
19.torch.cat
在PyTorch中,
torch.cat函数用于将多个张量沿指定维度拼接在一起,这在深度学习中是一个非常常见的操作,尤其是在处理序列数据或需要将多个特征图组合在一起时。
20.model.named_modules()
在 PyTorch 中,
model.named_modules()是一个方法,它用于遍历模型中的所有模块(包括子模块)。这个方法返回一个迭代器,其中每个元素都是一个元组,包含模块的名称和模块本身。
21.module.register_forward_hook(hook)
在 PyTorch 中,
module.register_forward_hook(hook)是一个非常有用的功能,它允许你在模型的前向传播过程中插入一个自定义的钩子(hook)函数。这个钩子函数会在每次前向传播完成后被调用,允许你访问和修改模块的输入和输出。
22.0轴
0轴是竖着排的
23.scatter_
它是对张量的元素进行赋值的高级操作,根据给定的索引将一个张量的元素“分散”到另一个张量中。
tensor.scatter_(dim, index, src)
参数说明:
dim:表示要在哪个维度上进行散射操作。index:表示目标张量中要填充的索引位置。src:是源数据,提供要写入的值。
24.torch.nn.Parameter
在PyTorch中,
torch.nn.Parameter是一种用于将张量注册为模型参数的特殊类型。它通常用于神经网络模型中,使张量能够参与反向传播,并且在训练时可以自动更新。主要作用:
- 区别普通张量:当你将一个张量定义为
torch.nn.Parameter,它就被标记为模型的可学习参数,意味着这个张量的值会在反向传播时自动更新。而普通的torch.Tensor不会自动注册为模型参数。- 自动加入模型的参数列表:当你在
torch.nn.Module中使用Parameter时,它会被自动添加到模型的参数列表中(通过model.parameters()方法可以看到)。这对于优化器来说很重要,因为优化器需要知道哪些参数需要更新。
25.torch.nn.ParameterList
在 PyTorch 中,
torch.nn.ParameterList是一个用于存储torch.nn.Parameter对象的容器。它的作用类似于 Python 中的list,但专门用于存储模型的可训练参数。这使得你可以在模型中动态管理和存储多个Parameter对象,而这些参数会自动被模型注册,并参与反向传播。主要作用:
- 存储多个参数:
ParameterList用于存储多个Parameter对象。如果你有一系列参数需要管理(如一组权重矩阵),可以将它们保存在ParameterList中。- 自动注册为模型的参数:所有存储在
ParameterList中的Parameter对象都会被自动注册为模型的参数,因此在调用model.parameters()时,ParameterList中的参数会包含在内。使用场景:
ParameterList通常在需要动态定义多个参数时使用。例如,某些模型可能有多个层,每一层的参数数量是动态确定的。在这种情况下,ParameterList就非常有用。
26.transpose()
在 PyTorch 中,
transpose()用于交换张量的两个维度。这个操作通常用于改变张量的形状# 语法:tensor.transpose(dim0, dim1) # dim0 和 dim1 是要交换的两个维度索引
27.contiguous()
在 PyTorch 中,
contiguous()用于将一个张量转换为在内存中连续存储的形式。某些操作(如transpose()或view())会导致张量在内存中的存储方式变得不连续,这会影响后续操作(例如view())的正确性。调用contiguous()可以确保张量在内存中是连续的,
28.torch.LongTensor
是 PyTorch 中用于表示64位整型(long型)张量的数据类型。它通常用于需要整数表示的数据,例如索引、类别标签等
29.yield
yield是 Python 中的一个关键字,用于定义生成器函数(generator function)。生成器函数是一种特殊的函数,不会立即执行完毕并返回结果,而是会在需要时逐步生成数据。每次调用yield时,生成器会暂停执行,并“yield”出一个值,供外部调用使用;在下一次迭代时,它会从暂停处继续执行
30..index_select()
在 PyTorch 中,
.index_select()是一种用于从张量中根据索引选择特定元素的操作。.index_select(dim, index)函数会在指定的维度(dim)上,从给定的index中选择对应的元素。
31.view()
view返回的是一个新张量,和原张量共享内存。这意味着如果你对重塑后的张量进行修改,原张量也会相应改变。
tensor.view(shape)
tensor:要重塑的张量。shape:一个元组或列表,指定新的形状。
32.TensorDataset
把两个数据对应起来,打包,在 PyTorch 中,
Dataset类是数据加载的基础类,它用于封装数据,
33.DataLoader
读取一个小批量
34.创建网络
事实上我们还可以用
nn.Sequential来更加方便地搭建网络,Sequential是一个有序的容器,网络层将按照在传入Sequential的顺序依次被添加到计算图中。# 写法一 net = nn.Sequential( nn.Linear(num_inputs, 1) # 此处还可以传入其他层 ) # 写法二 net = nn.Sequential() net.add_module('linear', nn.Linear(num_inputs, 1)) # net.add_module ...... # 写法三 from collections import OrderedDict net = nn.Sequential(OrderedDict([ ('linear', nn.Linear(num_inputs, 1)) # ...... ])) print(net) print(net[0])Copy to clipboardErrorCopied输出:
Sequential( (linear): Linear(in_features=2, out_features=1, bias=True) ) Linear(in_features=2, out_features=1, bias=True)
35. 初始化模型的参数
1.自定义模型(纯手写)
w = torch.normal(0, 0.01,(input_num, 1), dtype=torch.float32) b = torch.zeros(1,dtype=torch.float32) w.requires_grad_(True) b.requires_grad_(True)或者
w = torch.normal(0, 0.01,(input_num, 1), dtype=torch.float32, requires_grad=True) b = torch.zeros(1,dtype=torch.float32, requires_grad=True)2.使用nn里的东西写的
from torch.nn import init init.normal_(net.linear.weight, mean=0, std=0.01) init.constant_(net.linear.bias, val=0)
3.用
nn.Sequential来更加方便地搭建网络from torch.nn import init init.normal_(net[0].weight, mean=0, std=0.01) init.constant_(net[0].bias, val=0)
对nn里的模型进行手动初始化:
net.transpose_conv.weight:指向转置卷积层的权重参数。PyTorch 中的每个卷积层都有一个weight属性,表示该层的权重张量。.data:这是一个 PyTorch 的属性,允许你直接访问weight的原始数据张量。虽然.data在旧版 PyTorch 中常用,但现代 PyTorch 中建议使用with torch.no_grad()来进行参数的修改,以确保不会记录梯度。.copy_(W):将权重张量W复制到net.transpose_conv.weight.data中。copy_是一个原地操作,会用W中的值覆盖转置卷积层的权重。
36.为不同的网络层设置不同的学习率
optimizer =optim.SGD([ # 如果对某个参数不指定学习率,就使用最外层的默认学习率 {'params': net.subnet1.parameters()}, # lr=0.03 {'params': net.subnet2.parameters(), 'lr': 0.01} ], lr=0.03)
37.动态的调整学习率
有时候我们不想让学习率固定成一个常数,那如何调整学习率呢?主要有两种做法。一种是修改
optimizer.param_groups中对应的学习率,# 调整学习率 for param_group in optimizer.param_groups: param_group['lr'] *= 0.1 # 学习率为之前的0.1倍
37.1.在模型里添加层
net.add_module是 PyTorch 中的一种方法,用于动态地向nn.Module的子类(通常是你的神经网络模型类)中添加子模块。通过add_module,你可以灵活地为网络添加新的层或模块,而不需要在模型定义时就固定所有结构。语法:
net.add_module(name, module)
name:一个字符串,表示你为这个模块取的名字。这个名字会成为模型的属性名,可以用来访问这个模块。module:要添加的 PyTorch 模块(例如,nn.Conv2d,nn.Linear,nn.ReLU等层或自定义的子模块)。
38.transforms.ToTensor()
transforms.ToTensor()将尺寸为 (H x W x C) 且数据位于[0, 255]的PIL图片或者数据类型为np.uint8的NumPy数组转换为尺寸为(C x H x W)且数据类型为torch.float32且位于[0.0, 1.0]的Tensor如果用像素值(0-255整数)表示图片数据,那么一律将其类型设置成uint8,避免不必要的bug。
39..gather
在PyTorch中,
y_hat.gather(1, y.view(-1, 1))的作用是从预测结果y_hat中选出每个样本对应的实际类别的预测值。具体解释如下:
y_hat是模型的输出,通常是一个二维张量,形状为[batch_size, num_classes],表示每个样本对于每个类别的预测得分。y是实际的标签,通常是一维张量,形状为[batch_size],表示每个样本的正确类别的索引。分析代码分步作用:
y.view(-1, 1):将y重新调整形状,使其变为[batch_size, 1]。这样做是为了与y_hat的形状匹配,方便进行gather操作。
y_hat.gather(1, y.view(-1, 1)):
gather(dim, index)会根据指定的index张量,在指定的dim维度上收集元素。
dim=1表示在类别维度上收集元素。y.view(-1, 1)提供了索引,即每个样本的真实类别索引。这样做的结果是:从
y_hat的每一行中选出对应y所指定类别的预测值,得到一个形状为[batch_size, 1]的张量,表示每个样本在其真实类别上的预测得分。
40.梯度清零
if optimizer is not None: optimizer.zero_grad()
- 清除梯度 (使用优化器的方式)
如果optimizer不为None,就调用optimizer.zero_grad()来清除模型所有参数的梯度。
- 这是标准的做法,通常在每个训练迭代的开始调用,以防止上一次的梯度影响到当前的反向传播。
elif params is not None and params[0].grad is not None: for param in params: param.grad.data.zero_()
- 手动清除梯度
当optimizer为None时,但params(模型的参数列表)不为空,而且其中的参数有非空的梯度 (grad不为None),就会手动将每个参数的梯度置零。
param.grad.data.zero_()直接将梯度清零,确保不影响当前的梯度计算。- 这种方式适用于未使用
optimizer时的场景,通常在一些自定义的优化实现中可能会用到。
optimizer.zero_grad()和param.grad.data.zero_()都用于清除梯度,但它们在操作方式和使用场景上有些区别:1.
optimizer.zero_grad()
- 作用:清除由
optimizer管理的所有参数的梯度。- 实现方式:
optimizer.zero_grad()会自动遍历optimizer中的所有参数,清除它们的梯度,因此适用于使用标准优化器(如SGD、Adam等)管理参数的情况。- 使用场景:适合大多数模型训练过程,通常在每个训练循环的开始调用,以避免梯度累积。
optimizer.zero_grad() # 清除优化器管理的所有参数的梯度2.
param.grad.data.zero_()
- 作用:直接访问单个参数的
.grad属性,将其.grad.data清零。- 实现方式:直接操作参数的
.grad数据部分 (data) 清零,不会影响计算图,因此适合更低级的自定义梯度操作场景。- 使用场景:适用于不使用优化器的情况(比如自定义更新策略),或在某些场合只希望清零特定参数的梯度。
`param.grad.data.zero_()` 和 `param.grad.zero_()` 都用于清零 `param` 的梯度,但在操作方式上有一些细微的区别:
### 1. `param.grad.data.zero_()`
- **作用**:直接对 `param.grad` 的底层数据(即 `.data`)进行清零。
- **实现细节**:`param.grad.data` 直接访问了梯度张量的底层数据,这种操作**不影响计算图**,也不会记录在计算图中,因此不会干扰自动求导。
- **使用场景**:在手动管理梯度或自定义更新场景中,如果希望清除梯度并确保操作不记录在计算图中,可以使用这种方式。### 2. `param.grad.zero_()`
- **作用**:直接对 `param.grad` 调用 `zero_()`,清零梯度。
- **实现细节**:`param.grad.zero_()` 更为直接地操作 `param.grad`,在多数情况下,它是首选,因为它会更清晰地表示我们希望清零梯度的意图。由于 `zero_()` 是**原地操作**,它通常也不会引入新的计算图记录。
- **使用场景**:大多数情况下,`param.grad.zero_()` 更直接,适合标准清零梯度的需求。### 总结
- **推荐使用**:一般情况下使用 `param.grad.zero_()` 即可,因为它表达更清晰且通常满足需求。
- **差异**:`param.grad.data.zero_()` 明确绕过计算图,避免任何可能的记录,但在 PyTorch 的大多数版本中,`param.grad.zero_()` 也不会导致图的额外记录,二者通常没有实质差异。
41.OrderedDict
OrderedDict 的作用:
OrderedDict在nn.Sequential中使用,可以为每一层指定名字,使得模型更具可读性,同时在调用某层时可以通过名字来访问。
42.nn.Sequential
主要用于将多个子模块按顺序组合起来,方便地定义网络结构。你可以将多个层(例如线性层、卷积层、激活函数等)按顺序放入
nn.Sequential,这样输入数据会依次通过每一层。注意事项
nn.Sequential按顺序传递输入,因此不适合包含复杂结构(如跳跃连接、分支结构)的网络。- 若需要更复杂的结构,可以继承
nn.Module类来自定义模型。
43.torch.set_default_tensor_type(torch.FloatTensor)
torch.set_default_tensor_type(torch.FloatTensor)是一个 PyTorch 中的设置,用于指定默认的张量类型。将默认张量类型设置为torch.FloatTensor意味着所有在不指定类型的情况下创建的张量都会是浮点型的torch.FloatTensor类型。
44.ImageFolder
ImageFolder适用于数据组织为文件夹结构的图像数据集。通常,每个类别有一个单独的子文件夹,其中包含属于该类别的所有图像。
数据集目录结构
ImageFolder要求数据按照特定结构组织:
root/ class1/ image1.jpg image2.jpg ... class2/ image3.jpg image4.jpg ...
root是数据集的根目录。- 每个
class子目录代表一个类别,包含类别对应的图像。
45.torchvision的transforms的用法
torchvision.transforms是 PyTorch 中用于图像预处理和数据增强的模块。它包含一系列实用的图像转换工具,如调整大小、裁剪、翻转、归一化等。这些转换通常在加载数据时使用,尤其适用于深度学习任务中的图像预处理。
1.transforms.Compose()
将多个转换方法组合在一起,形成一个完整的转换流水线。
from torchvision import transforms
transform = transforms.Compose([
transforms.Resize((256, 256)), # 调整图像大小
transforms.CenterCrop(224), # 裁剪中心区域
transforms.ToTensor(), # 转换为张量
transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5]) # 归一化
])
2.transforms.Resize()
调整图像大小到指定尺寸,参数可以是单个数值或元组
(height, width)。
transform = transforms.Resize((256, 256)) # 调整图像到 256x256
46.weight_decay
weight_decay是深度学习中用于 正则化 的一种方法,通常在训练神经网络时使用,以防止模型过拟合。它通过在优化过程中添加一个惩罚项来约束模型的权重大小,使得模型参数不会过于复杂。weight_decay也称为 L2 正则化,其作用是向损失函数中添加一个与模型权重相关的惩罚项。这个惩罚项是所有权重平方和的加权总和在 PyTorch 中,可以直接在优化器中设置
weight_decay参数
weight_decay=0.0001表示 L2 正则化系数 λ=0.0001\lambda = 0.0001λ=0.0001。- 支持
weight_decay的优化器包括SGD,Adam,RMSprop等。
47.pretrained_net.features
通过
pretrained_net.features访问模型的特征提取层。
pretrained_net.features代表模型的特征提取部分。对于像 VGG 这样的卷积神经网络,features通常包含了一系列的卷积层(Conv2d)、激活层(如ReLU)、池化层(MaxPool)等。
48.torch.optim.lr_scheduler.StepLR()
这行代码使用了 PyTorch 提供的
StepLR学习率调度器,它会根据预定的步长(epoch 数)来衰减学习率。
scheduler = torch.optim.lr_scheduler.StepLR(trainer, lr_decay_epoch, 0.8)
- torch.optim.lr_scheduler.StepLR: 这是一个学习率调度器,用来在训练过程中调整学习率。
StepLR以固定的步长衰减学习率。- 参数解释:
trainer: 传入的优化器对象,这里指你的trainer,即用于优化合成图片的Adam优化器。lr_decay_epoch: 学习率衰减的步长,表示每隔多少个 epoch 就会调整一次学习率。0.8: 学习率衰减的系数(gamma)。每当达到步长时,学习率会乘以这个系数,缩小为原来的 0.8 倍。例子
如果初始学习率是 0.01,
lr_decay_epoch = 10,并且gamma = 0.8,那么:
- 在训练达到第 10 个 epoch 时,学习率变成 0.01×0.8=0.0080.01 \times 0.8 = 0.0080.01×0.8=0.008。
- 在第 20 个 epoch 时,学习率再次变成 0.008×0.8=0.00640.008 \times 0.8 = 0.00640.008×0.8=0.0064。
- 依此类推,学习率在每个
lr_decay_epoch之后都会衰减一次。作用
StepLR调度器通过逐步减小学习率,帮助模型更稳定地进行训练,尤其是在后期,能够更精确地收敛到最优解。注意:
最后要有两次:
trainer.step() scheduler.step()
49.torch.eye()
torch.eye(10)是 PyTorch 中用于创建一个 10×10 的**单位矩阵(identity matrix)**的函数解释
torch.eye(n)会生成一个 n×nn \times nn×n 的二维张量,对角线上的元素为 1,其余元素为 0。- 在
torch.eye(10)的情况下,会生成一个 10 行 10 列的矩阵,主对角线上全为 1,其他位置为 0。
50.torch.sort()
torch.sort是 PyTorch 中用于对张量进行排序的函数,它可以根据给定的维度对张量中的元素进行升序或降序排列。语法:
sorted_tensor, indices = torch.sort(input, dim=-1, descending=False)
- input: 需要排序的张量。
- dim: 指定排序的维度,默认值是
-1,表示最后一个维度。- descending: 布尔值,表示是否按降序排列,默认值为
False,即升序排序。返回值:
sorted_tensor: 排序后的张量。indices: 一个张量,表示排序后每个元素在原始张量中的索引位置
51.torch.arange()
torch.arange是 PyTorch 中用于生成一个包含等差数列的 1D 张量的函数。它类似于 Python 中的range函数,但生成的是一个张量对象。语法:
torch.arange(start=0, end, step=1, out=None, dtype=None, layout=torch.strided, device=None, requires_grad=False)
- start: 序列的起始值,默认为 0。
- end: 序列的终止值(不包含该值)。
- step: 序列的步长,默认为 1。
- out: 可选,用于存储输出的张量。
- dtype: 指定返回张量的数据类型(如
torch.float32、torch.int等)。- layout: 张量布局,默认是
torch.strided。- device: 指定生成张量所在的设备(如
cpu或cuda)。- requires_grad: 如果设置为
True,会记录操作以支持自动求导。
52.torch.repeat_interleave
torch.repeat_interleave是 PyTorch 中用于将张量的元素按指定的重复次数进行展开的函数。每个元素都可以重复多次,从而生成一个新的张量。语法:
torch.repeat_interleave(input, repeats, dim=None)
- input: 输入的张量。
- repeats: 指定每个元素要重复的次数。可以是一个整数(为所有元素指定相同的重复次数)或一个张量(为每个元素指定不同的重复次数)。
- dim: 指定沿哪个维度进行重复。如果不设置,输入会被展平成一维张量后再进行重复。
queries.repeat_interleave()
repeat_interleave是 PyTorch 中的一个函数,用于在指定的维度上重复元素。这样做的目的是将queries扩展,使得每个查询样本能够与所有的键样本进行配对比较。解释
queries.repeat_interleave(4, dim=0)将queries的每个样本在第 0 个维度上重复 4 次。结果是一个形状为(8, 3)的张量,其中每个查询样本都被重复了 4 次。- 这样,我们就可以将扩展后的
queries_expanded与形状为(4, 3)的keys进行一一比较,实现每个查询样本与所有键样本的多对多比较。
53.repeat
repeat是 PyTorch 中另一个用于张量扩展的方法,它可以通过在指定维度上多次重复张量来生成更大的张量。与repeat_interleave不同的是,repeat会将整个张量在指定维度上进行复制,而不是对每个元素进行重复。
语法:
tensor.repeat(*sizes)
- tensor: 需要重复的张量。
- sizes: 一个整数元组,表示在每个维度上重复的次数。
54.(1 - torch.eye(n_train)).type(torch.bool)
这一步将矩阵转换为布尔类型,其中 0 会变成
False,1 会变成True。
55.X_tile[(1 - torch.eye(n_train)).type(torch.bool)]
- 这是在使用布尔掩码对
X_tile进行索引。布尔掩码的作用是过滤X_tile中的位置,只保留掩码中为True的元素。- 这种方式将
X_tile视作一个扁平化的一维数组,选取所有对应为True的元素。- 按照从上至下从左至右进行拉成一个一维数组
56.dim=-1
dim=-1通常用于指定操作应该沿着最后一个维度进行。
57.nn.GRU(embed_size, num_hiddens, num_layers, dropout=dropout)
是 PyTorch 中的一个 GRU(门控循环单元)层的构造函数。它定义了一个 GRU 网络层,通常用于处理序列数据。下面是每个参数的解释:
1.
embed_size(输入维度,或输入特征的维度)
- 这个参数表示每个时间步的输入特征的大小,或者说输入的维度。
- 在许多应用中,
embed_size可能对应于嵌入层(embedding layer)的输出维度。例如,在自然语言处理中,embed_size可能是词嵌入的维度。- 每个输入的时间步将是一个向量,大小为
embed_size。2.
num_hiddens(隐藏层的维度)
- 这个参数指定了 GRU 隐藏状态的维度,也就是每个时间步的隐藏状态向量的大小。
num_hiddens控制了 GRU 的“容量”,它决定了模型可以在隐藏状态中存储多少信息。较大的num_hiddens可能会提高模型的表达能力,但也可能导致过拟合。3.
num_layers(GRU 层数)
- 这个参数指定了堆叠的 GRU 层的数量。GRU 是可以堆叠的,即多层 GRU 可以相互连接,每一层的输出都作为下一层的输入。
num_layers设置了模型的深度。更深的模型能够捕捉到更复杂的模式,但也可能更难训练。4.
dropout(Dropout 概率)
- 这是一个可选参数,指定在 GRU 网络中使用的 Dropout 概率。Dropout 是一种正则化方法,它在训练过程中随机丢弃神经元的连接,以防止过拟合。
dropout的值应该在0和1之间。dropout=0表示没有应用 Dropout,而dropout=0.5表示每个神经元在训练过程中有 50% 的概率被丢弃。- 当
num_layers > 1时,Dropout 将应用于中间层之间的连接,避免过拟合。
58.masked_fill
PyTorch 中的一个函数,它用于根据给定的掩码(mask)将张量中的特定元素替换为指定值。以下是关于
masked_fill的详细介绍:
输入参数:
- 输入张量(Tensor):这是需要被操作的原始数据张量。
- 掩码(Mask):一个与输入张量形状相同的布尔型张量,
True表示需要填充的位置,False表示保持原值。- 填充值(Value):一个标量值,用于替换掩码中为
True的位置对应的元素值。功能:
masked_fill会检查掩码中每个元素的值,如果掩码对应的位置为True,则在输出张量中填充指定的值;如果为False,则保留输入张量中对应位置的值。
import torch
# 创建一个张量
tensor = torch.tensor([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
# 创建一个掩码,标记要填充的位置
mask = torch.tensor([[False, True, False], [True, False, True], [False, False, True]])
# 使用 masked_fill 填充掩码位置为 -1
result = tensor.masked_fill(mask, -1)
print("原始张量:")
print(tensor)
print("\n填充后的张量:")
print(result)
tensor([[-1., 2., -1.],
[ 4., -1., 6.]])59.nn.Softmax(dim=-1)(scores)
这种写法是 PyTorch 中的一种简洁的链式调用方式。让我们分点来解释:
nn.Softmax(dim=-1) 创建了一个 Softmax 实例,dim=-1 表示在最后一个维度上应用 Softmax 函数。
(scores) 对创建的 Softmax 实例立即进行调用,并将 scores 作为输入传递给它。
等价于以下两步写法:注意:这种方式常用于一次性使用某个模块或函数时,可以减少变量定义,使代码更加简洁。
softmax = nn.Softmax(dim=-1)
attn = softmax(scores)
60.torch.gt
是 PyTorch 中的一个函数,用于逐元素比较两个张量(Tensor)的大小,并返回一个布尔型张量,表示第一个张量中的元素是否大于第二个张量中对应元素。以下是
torch.gt函数的详细介绍:
函数作用:
torch.gt(a, b)函数比较两个张量a和b中对应元素的大小。如果a中的元素严格大于b中的对应元素,则结果张量中对应的位置为True,否则为False。输入参数:
a(Tensor):第一个参与比较的张量。b(Tensor 或 float):第二个参与比较的张量或一个标量值。如果b是一个张量,它的形状必须与a相同或能够通过广播机制与a相匹配。输出结果:
- 返回一个布尔型张量(
torch.ByteTensor),其中包含了每个位置的比较结果。
61.nn.Embedding
nn.Embedding是一个用于查找固定大小嵌入向量的层,通常用来处理离散的、索引表示的数据(如单词索引或类别索引)。它可以看作是一种查询表(lookup table),将输入的整数索引映射到连续的向量表示。
torch.nn.Embedding(num_embeddings, embedding_dim, padding_idx=None, max_norm=None, norm_type=2.0, scale_grad_by_freq=False, sparse=False, _weight=None)
1. 必需参数
num_embeddings:
- 表示嵌入矩阵的大小,即字典的大小或词汇表的大小。
- 输入索引的范围是
[0, num_embeddings - 1]。embedding_dim:
- 每个嵌入向量的维度大小。
- 例如,如果你想将一个单词映射为一个 100 维向量,则设置为
100。2. 可选参数
padding_idx:
- 指定一个索引,该索引的嵌入向量会被固定为全零,且不会被更新。
- 常用于处理序列任务中的填充(padding)操作。
max_norm:
- 如果设置了这个参数,每次调用
Embedding时,嵌入向量会被重新正则化,使其范数不超过max_norm。norm_type:
- 控制正则化时使用的范数类型(默认为 L2 范数,即
norm_type=2.0)。scale_grad_by_freq:
- 如果设置为
True,则会根据输入中每个词的频率来缩放梯度,常用于自然语言处理任务。sparse:
- 如果设置为
True,则使用稀疏梯度更新。- 对于非常大的嵌入表,这可以显著节省内存并提高计算效率。
3. 特殊参数
_weight:
- 允许用户直接提供一个嵌入矩阵(形状为
[num_embeddings, embedding_dim]),作为初始化权重。
工作原理
nn.Embedding 背后的核心思想是定义一个形状为 [num_embeddings, embedding_dim] 的嵌入矩阵,每一行表示一个嵌入向量。
- 当输入是索引(如
[1, 3, 5])时,nn.Embedding会将这些索引映射到对应的嵌入向量,例如返回第 1、3 和 5 行。
注意:可以使用自己预定义的嵌入矩阵
nn.Embedding的嵌入矩阵是可以学习更新的。它的嵌入矩阵本质上是一个可训练的权重张量,在模型训练过程中,会通过反向传播算法不断更新其值,以优化任务目标。
***1.临时
1.获取参数
param.data通常用于直接访问和修改模型参数的原始数据param 是一个 torch.nn.Parameter对象,它包含了张量数据和梯度信息 param.data是一个普通的张量(torch.Tensor),只包含参数的值
param.data可以用于所有torch.Tensor对象,无论它们是直接创建的张量(如w和b),还是torch.nn.Parameter对象。实际上,PyTorch 中所有张量都有data属性,它用于访问张量的底层数据,无需经过计算图。这意味着,即使param是一个普通张量而不是nn.Parameter,你仍然可以通过param.data来直接操作它的值,而不触发自动微分计算。当一个普通张量
w设置了requires_grad=True时,PyTorch 会自动为它分配一个grad属性,用于存储它的梯度信息。这样,即使w是一个普通的torch.Tensor,只要requires_grad=True,在进行反向传播后,它的grad属性就会包含相对于某个损失函数的梯度。
2.求梯度
如果,不对损失函数求和的话,直接求梯度,需要给backword传一个反向传播要求链式法则的起始梯度是一个标量。所以如果
y是向量,PyTorch 需要知道我们希望如何组合y中的每个元素的梯度。为此,需要传入一个与y同形的张量,用来指定每个元素在最终梯度计算中的“权重”
三、项目中的问题
1.没有梯度清零
模型没问题,但是损失值,准确率不对
解决:就是在使用nn的优化算法,没有进行梯度清零
2.激活函数
1. 线性层(没有激活函数)
- 如果所有的灯都连接到一个简单的开关(没有激活函数),那么无论你怎么调节电流(输入信号),灯都是以一种线性的方式来响应。例如,调高电流,所有灯亮得越亮;调低电流,所有灯就会变暗。
- 这种情况下,你只能得到一种简单的亮度变化,无法创造不同的模式或氛围。
2. 引入激活函数
- 当你加入不同类型的开关(激活函数)时,就可以创造出多种灯光效果。例如:
- ReLU:这个开关只有在电流超过某个阈值时才会让灯亮起,意味着小于0的电流(负值)让灯不亮,只有当电流大于0时,灯才会亮。这使得灯的反应变得非常直接且简单。
- Sigmoid:这个开关会将电流压缩到一个范围内(0到1),灯的亮度根据电流的强弱逐渐变化,但永远不能完全熄灭或完全亮起。
- Tanh:这个开关则让灯可以亮到正的最大值和负的最大值,灯的亮度更加丰富,可以呈现出更多样的效果。
3.模型的参数的确定
在构建卷积神经网络(CNN)时,确定每层的参数(如通道数、卷积核大小等)是一个关键过程。这些参数通常基于以下几个方面进行选择:
1. 输入数据的特征
- 输入通道数:第一层的输入通道数通常与输入图像的通道数相同,例如灰度图像有1个通道,彩色图像有3个通道。
- 输出通道数:后续层的输出通道数通常是根据特征图的复杂性和模型的设计来决定。你可以通过实验确定,这里使用6和16是为了逐步增加特征的表示能力。
2. 卷积核大小(Kernel Size)
- 常用的卷积核大小:通常选择3x3、5x5、7x7等,较小的卷积核(如3x3)能更好地捕捉细节,而较大的卷积核(如5x5)则能捕捉更大的特征。这里使用5x5是一个常见的选择,可以有效提取局部特征。
3. 池化层的使用
- 最大池化(Max Pooling):池化层用于降低特征图的尺寸,减少计算量,并帮助防止过拟合。采用2x2的池化层是常见的做法,它将特征图的尺寸减半,从而保留重要特征。
4. 层的深度
- 逐层增加通道数:随着层数的增加,通常会增加输出通道数。这是因为较高层的特征表示通常需要更为复杂和丰富的特征。在你的例子中,从6到16的增加是一个合理的选择。
5. 实验与调优
- 超参数调整:这些参数通常需要通过实验来调整,以找到最适合特定任务的组合。网络的性能可以通过交叉验证、学习曲线等方法进行评估和优化。
总结
在卷积神经网络中,参数的选择依赖于输入数据的特性、模型的目标以及实验结果。初学者通常会使用一些经验法则,但最终还是需要通过实验找到最优配置。
四、Pycharm问题
1.页内查找
ctrl + f
五、模型维度
1.FCN的输出形状
批量大小、类别数、长、宽,没有展平
标签的形状:
2.RNN
在循环神经网络模型中,第一个轴对应于时间步
六、数学问题
1.条件概率
条件概率是指在某个条件或事件已经发生的前提之下,另一个事件发生的概率。
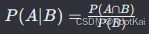

2.联合概率
在条件概率的公式中使用事件A和事件B同时发生的概率(即P(A∩B)),是因为我们想要计算的是在事件B已经发生的条件下,事件A发生的概率。这个同时发生的概率,也就是联合概率,提供了一个基础,用来衡量事件A和事件B之间的关联性
3.均值消失/去中心化
在标准化过程中,均值“消失”是因为我们将每个数据点减去了该列的均值,这一步操作将整个列的均值调整为 0。因此标准化后的数据不再具有原来的均值值,而是围绕 0 分布。这个过程称为“去均值”或“中心化”。
4.预测的相对误差和绝对误差
这句话的意思是,在预测房价时,由于不同地区房价的绝对值差异很大,我们更关注的是预测的相对误差,即预测与真实价格的比例差异,而不是预测的绝对误差(即具体差了多少金额)。这种相对误差考虑到了房价的基准,因此更公平合理。
例子解释
- 在价格较低的地区(如俄亥俄州农村地区),一栋房子价格大约为 12.5 万美元,如果我们的预测偏差了 10 万美元,那意味着预测和实际价格的相对差异很大,模型的表现就相对较差。
- 相反,在加州的豪宅区,一栋房子的价格可能超过 400 万美元,在这种情况下,即使预测误差仍是 10 万美元,偏差相对于高房价来说是很小的比例。这时,模型的表现就相对更好。
为什么用价格的对数
用价格的对数来衡量误差可以更好地捕捉这种相对误差,而不是单纯的绝对误差。原因如下:
对数缩小高值之间的差异:对数会使大的房价差异变小,从而让高价区和低价区的误差变得更加相对,避免低价区的误差显得过于显著。
反映比例差异:对数变换后,差异(比如对数误差)更能反映实际值的比例差异而非绝对差异。比如,对一个 100 万美元的房子和 200 万美元的房子的预测误差,经过对数变换,差异会更均匀,类似于百分比误差。
数学解释
假设实际价格是 yyy,预测价格是 y^\hat{y}y^。则它们的对数差异是:
log-difference=log(y^)−log(y)\text{log-difference} = \log(\hat{y}) - \log(y)log-difference=log(y^)−log(y)或等价地:
log(y^y)\log\left(\frac{\hat{y}}{y}\right)log(yy^)这反映的是预测值与实际值的相对误差。这种对数差异有助于减小高房价预测的绝对误差,使模型对不同地区房价的预测更加一致和公平。
七、网络
1. ReLU
ReLU会将所有负数输出为 0,而正数则保持不变。这意味着当输入大于 0 时,输出为该正数本身;当输入小于或等于 0 时,输出为 0。
2.获得网络每层的名称和参数
在 PyTorch 中,可以通过
model.named_parameters()或model.parameters()来打印网络每层的参数。以下是一些方法来查看和打印每层的参数:1. 使用
named_parameters()
named_parameters()会返回每一层的名称和参数,通过循环遍历它们可以查看每一层的参数:
for name, param in model.named_parameters(): print(f"Layer: {name} | Size: {param.size()} | Values : {param[:2]}") # 打印前两个值作为示例
name:层的名称。param.size():参数的尺寸。param[:2]:查看参数的前两个元素(可以省略或根据需要调整)。2. 使用
parameters()如果只想打印参数而不关心层的名称,可以直接用
parameters():
for param in model.parameters(): print(param.size()) print(param)3. 查看特定层的参数
如果想要查看模型中特定层的参数,例如某一层的权重和偏置,可以直接通过层名访问。例如,对于一个名为
fc1的全连接层:
print(model.fc1.weight) # 打印 fc1 层的权重 print(model.fc1.bias) # 打印 fc1 层的偏置4. 以字典形式打印所有参数
将参数转换为字典会使得输出更清晰:
params_dict = dict(model.named_parameters()) for layer_name, param in params_dict.items(): print(f"{layer_name}: {param.size()}")示例
假设你有一个简单的模型:
import torch.nn as nn model = nn.Sequential( nn.Linear(784, 256), nn.ReLU(), nn.Linear(256, 10) )
3.深度学习的要求格式
形状(批量大小、通道数、高度、宽度)
使用torchversion.transforms.Totensor()转换,用法与图像操作一致
4.在GPU上计算
1.多GPU计算
要把数据移动到指定的GPU上
torch.nn.DataParallel是 PyTorch 提供的一个用于多 GPU 并行计算的模块,可以轻松地将模型分布到多个 GPU 上进行训练。它通过将输入数据划分到不同的 GPU 上并行计算,然后聚合每个 GPU 上的结果,来加速深度学习模型的训练。
用法:
import torch
import torch.nn as nn
# 假设我们有一个简单的模型
model = nn.Linear(10, 2)
# 检查是否有多个 GPU
if torch.cuda.device_count() > 1:
print("使用", torch.cuda.device_count(), "个GPU进行训练")
# 使用 DataParallel 将模型封装起来
model = nn.DataParallel(model)
# 将模型移动到第一个 GPU 上
model = model.to('cuda')
原理:
- 模型并行:
DataParallel会自动将模型复制到每个可用的 GPU 上。- 数据并行:当有输入数据时,
DataParallel会将数据划分为多个子批次,并将这些子批次分配到不同的 GPU 上。每个 GPU 会独立地执行前向和后向传播,然后DataParallel会将所有 GPU 的梯度聚合,并更新模型参数。
torch.nn.parallel.DistributedDataParallel:推荐用于分布式训练,尤其是当你的集群中有多个节点时,它比DataParallel更高效,尤其是在大规模分布式训练中。
这时,默认所有存在的GPU都会被使用。
如果我们机子中有很多GPU(例如上面显示我们有4张显卡,但是只有第0、3块还剩下一点点显存),但我们只想使用0、3号显卡,那么我们可以用参数
device_ids指定即可:torch.nn.DataParallel(net, device_ids=[0, 3])。
注意:
当你创建一个 PyTorch 模型时,默认情况下模型参数是在 CPU 上的。如果你希望在 GPU 上进行训练,你必须显式地将模型移动到 GPU。这是通过
model.to('cuda')来实现的。
model = model.to('cuda'):将模型的主副本移动到 GPU 上,通常是第一个 GPU (cuda:0)。这使得模型可以在 GPU 上进行计算,而不是在 CPU 上。
nn.DataParallel(model):将model封装起来,使其能够在多个 GPU 上并行运行。当DataParallel将数据分发到多个 GPU 时,模型的主副本仍然需要位于某个 GPU 上(通常是cuda:0),并由DataParallel负责将模型的副本分配到其他 GPU。如果你没有使用
model.to('cuda')将模型移动到 GPU 上,那么即使你使用了nn.DataParallel,模型仍然会在 CPU 上,这会导致计算无法在 GPU 上进行,或者会引发错误,因为输入数据和模型参数在不同的设备上(CPU 和 GPU)。
5.使用预训练模型
1.使用预训练模型
ResNet-18作为源模型。这里指定
pretrained=True来自动下载并加载预训练的模型参数。在第一次使用时需要联网下载模型参数。pretrained_net = models.resnet18(pretrained=True)不管你是使用的torchvision的
models还是pretrained-models.pytorch仓库,默认都会将预训练好的模型参数下载到你的home目录下.torch文件夹。你可以通过修改环境变量$TORCH_MODEL_ZOO来更改下载目录:``` export TORCH_MODEL_ZOO="/local/pretrainedmodels ```linux里面:home\.cache\torch\checkpoints
windows:C:\Users\xxx\.cache\torch\hub\checkpoints\
注意:注: 在使用预训练模型时,一定要和预训练时作同样的预处理。
注意:预训练模型的权重已经经过大量数据的训练学习,但是当你改变模型的结构时,比如调整输出类别的数量,PyTorch 会用默认的初始化方式重新随机初始化新的层的参数,而不是保留预训练权重。这使得新层能适应你要解决的特定任务。
注意:由于是在很大的ImageNet数据集上预训练的,所以参数已经足够好,因此一般只需使用较小的学习率来微调这些参数,而
fc中的随机初始化参数一般需要更大的学习率从头训练。
2.修改 ResNet-18 的输出层
torchvision提供的resnet18默认用于 ImageNet 分类任务,输出 1000 个类别。因此,你需要将最后的全连接层(fc)调整为输出 10 个类别。具体的代码如下:
import torch import torchvision.models as models # 加载预训练的 ResNet-18 模型 resnet18 = models.resnet18(pretrained=True) # 修改最后的全连接层,使其输出 10 个类别 resnet18.fc = torch.nn.Linear(resnet18.fc.in_features, 10) # 检查模型结构 print(resnet18)解释
models.resnet18(pretrained=True): 加载预训练的 ResNet-18 模型。如果你不需要预训练权重,可以将pretrained设置为False。resnet18.fc: ResNet-18 的最后一层是一个全连接层,名为fc。resnet18.fc.in_features获取输入到这层的特征数。通过torch.nn.Linear(resnet18.fc.in_features, 10),将输出类别数修改为 10 个。
6.特征标准化
特征标准化(Feature Standardization)是将数据的分布调整为均值为0,标准差为1的过程。
使特征具有相似的尺度:
- 数据集中的不同特征可能具有不同的单位和范围。例如,年龄可能在 0 到 100 之间,而收入可能在 1000 到 1,000,000 之间。这样,特征的尺度差异会导致模型训练时某些特征对结果的影响远大于其他特征。
- 标准化后,每个特征的值被转换为均值为0、标准差为1,确保每个特征的尺度相似,从而避免某些特征对模型的训练过程产生过大影响。
加速收敛速度(特别对于梯度下降优化的模型):
- 对于许多优化算法(如梯度下降),特征的尺度差异会导致算法的收敛速度变慢。因为优化过程中的梯度更新是基于特征的数值大小进行的,如果特征尺度差异大,梯度下降可能会出现“方向不一致”的问题,使得优化过程需要更多的迭代。
- 标准化后的特征有助于提高训练的稳定性和收敛速度,尤其是在神经网络训练中。
有助于距离计算:
- 对于依赖距离度量的算法(如 K-近邻(KNN)和支持向量机(SVM)),特征尺度的不同可能导致某些特征对距离计算的贡献过大,从而影响模型性能。
- 标准化后,每个特征对距离计算的影响是均等的,避免了模型受到某些特征的过度影响。
避免某些特征主导模型训练:
- 如果数据中某些特征的数值范围远大于其他特征(例如,收入范围远大于年龄),这些特征会主导模型的训练过程,从而影响最终的预测结果。
7.修改学习率
PyTorch可以方便的对模型的不同部分设置不同的学习参数
output_params = list(map(id, pretrained_net.fc.parameters())) feature_params = filter(lambda p: id(p) not in output_params, pretrained_net.parameters()) lr = 0.01 optimizer = optim.SGD([{'params': feature_params}, {'params': pretrained_net.fc.parameters(), 'lr': lr * 10}], lr=lr, weight_decay=0.001)
八、数据格式
1.csv
CSV(Comma-Separated Values,逗号分隔值)是一种简单的、基于文本的文件格式,用于存储表格数据。每行代表一条记录,每列之间用逗号分隔。CSV格式被广泛用于数据导入、导出,因为它易于处理和广泛兼容。
CSV的主要特点包括:
- 分隔符:每个字段之间用逗号(
,)分隔,有些地区可能用分号(;)。- 换行:每条记录通常用换行符(
\n)分隔。- 头部行(可选):通常,第一行包含字段名称,表示每列的内容。
- 字符编码:常用编码为UTF-8。
- 字符串处理:若字段中包含逗号或换行符,通常会使用双引号包围该字段内容。
示例
假设我们有一个人员信息表,包含姓名、年龄、城市: 姓名,年龄,城市 张三,25,北京 李四,30,上海 王五,22,广州在CSV文件中,这段内容保存为纯文本文件(如
example.csv),可以用Excel、文本编辑器、编程语言(如Python、R等)方便地读取和操作。
九、文件操作
1.打开图片
使用 Pillow(PIL 库)Pillow 是 Python 中用于处理图像的常用库。你可以用它来打开和显示图片。
from PIL import Image # 打开图片 image = Image.open("path_to_image.jpg") # 显示图片 image.show()注意:
image.show()会在默认的图片查看器中显示图片。
2.读取数据文件
torchversion.datasets.写好的读取的数据文件
torch.utils.data.Dataset:自定义数据集的基类
torch.utils.data.DataLoader:批量加载数据集的工具
3.python的文件操作
1.打开和关闭文件
- 使用
open()函数打开文件,返回一个文件对象。- 使用
close()方法关闭文件。file = open('example.txt', 'r') # 打开文件用于读取 file.close() # 关闭文件
2. 读取文件内容
read(): 读取整个文件内容。readline(): 逐行读取,每次读取一行。readlines(): 读取所有行,并返回一个列表。# 读取整个文件 with open('example.txt', 'r') as file: content = file.read() print(content) # 逐行读取 with open('example.txt', 'r') as file: for line in file: print(line.strip()) # 使用 readlines() with open('example.txt', 'r') as file: lines = file.readlines() print(lines)
3. 写入文件
write(): 将字符串写入文件。如果文件已存在,会覆盖内容。如果文件不存在,会创建一个新文件。writelines(): 将一个字符串列表写入文件。# 写入内容到文件 with open('example.txt', 'w') as file: file.write('Hello, world!\n') file.write('This is a new line.\n') # 使用 writelines() lines = ['Line 1\n', 'Line 2\n', 'Line 3\n'] with open('example.txt', 'w') as file: file.writelines(lines)
4. 追加内容
使用
'a'模式可以将新内容追加到文件末尾。with open('example.txt', 'a') as file: file.write('This is an appended line.\n')
5. 文件模式
'r': 只读模式(默认)。'w': 写入模式(会覆盖文件)。'a': 追加模式。'b': 二进制模式(如'rb','wb')。'+': 读写模式(如'r+','w+','a+')。
6. 处理二进制文件
可以使用
'b'模式打开二进制文件,如图片或音频文件。# 读取二进制文件 with open('image.png', 'rb') as file: content = file.read() # 写入二进制文件 with open('copy_image.png', 'wb') as file: file.write(content)
7. 异常处理
可以使用
try-except来捕获文件操作中的异常。try: with open('example.txt', 'r') as file: content = file.read() except FileNotFoundError: print('File not found.') except IOError: print('An error occurred while reading the file.')
4.python内置os的操作
os模块是 Python 的一个内置模块,用于与操作系统交互,执行如文件和目录操作、获取环境变量、管理进程等任务。以下是一些常见的用法:
1. 获取当前工作目录
import os
current_directory = os.getcwd()
print(f"当前工作目录: {current_directory}")
2. 改变工作目录
os.chdir('/path/to/directory') # 更改当前工作目录
print(f"已更改工作目录: {os.getcwd()}")3. 创建新目录
os.mkdir('new_folder') # 创建单个目录
os.makedirs('folder/subfolder') # 递归创建多级目录
4. 删除目录或文件
os.rmdir('new_folder') # 删除单个空目录
os.removedirs('folder/subfolder') # 递归删除多级空目录
os.remove('example.txt') # 删除文件
5. 列出目录中的文件和子目录
files_and_dirs = os.listdir('/path/to/directory')
print(files_and_dirs)
6. 检查文件或目录是否存在
if os.path.exists('example.txt'):
print('文件存在')
else:
print('文件不存在')
if os.path.isdir('folder'):
print('这是一个目录')
if os.path.isfile('example.txt'):
print('这是一个文件')
7. 获取文件或目录的详细信息
file_info = os.stat('example.txt')
print(file_info)
8. 组合和拆分路径
os.path.join(): 合并路径,处理不同操作系统的路径分隔符。os.path.split(): 拆分路径,返回目录和文件名。os.path.splitext(): 拆分文件名和扩展名。
# 合并路径
path = os.path.join('/folder', 'subfolder', 'file.txt')
print(path) # 输出: /folder/subfolder/file.txt(Windows 上为 \)
# 拆分路径
directory, filename = os.path.split('/folder/subfolder/file.txt')
print(directory) # 输出: /folder/subfolder
print(filename) # 输出: file.txt
# 拆分文件名和扩展名
name, ext = os.path.splitext('file.txt')
print(name) # 输出: file
print(ext) # 输出: .txt
9. 遍历目录树
可以使用 os.walk() 遍历目录树,获取每个目录中的文件和子目录。
for root, dirs, files in os.walk('/path/to/directory'):
print(f'当前目录: {root}')
print(f'子目录: {dirs}')
print(f'文件: {files}')
10. 获取环境变量
home_directory = os.getenv('HOME') # 获取环境变量
print(f"HOME 目录: {home_directory}")
# 设置环境变量
os.environ['NEW_VARIABLE'] = 'value'
print(os.environ['NEW_VARIABLE'])
11. 执行系统命令
使用 os.system() 可以执行操作系统命令。
os.system('ls') # 在 Linux/Mac 上列出当前目录内容
os.system('dir') # 在 Windows 上列出当前目录内容
12.os.path.dirname(fname)
提取文件的目录
十、图片的操作
图片的操作是使用torchvision包
1.随机翻转
随机水平翻转:torchvision.transforms.RandomHorizontalFlip()
随机垂直翻转:torchvision.transforms.RandomVerticalFlip()
会以 50% 的概率对给定的图像进行翻转
2.随机裁剪
随机裁剪:torchversion.transforms.RandomResizedCrop(
size,scale,ratio)参数
size:输出图像的目标大小,通常为一个整数或一个元组(height, width),指定裁剪后的图像尺寸。例如,size=224会将裁剪后的图像调整为 224x224。
scale:裁剪区域相对于原始图像的面积的比例范围。默认值为(0.08, 1.0),表示裁剪区域的面积将是原始图像面积的 8% 到 100% 之间。
ratio:裁剪区域的纵横比范围。默认值为(3/4, 4/3),表示裁剪区域的宽高比将在 3:4 到 4:3 之间随机选择。
3.改变颜色
随机改变颜色:torchversion.transforms.ColorJitter(
brightness,contrast,saturation,hue)参数
brightness:控制亮度调整的范围。如果是一个浮点数 b,则亮度因子会在 [1−b,1+b][之间随机选择,默认值为 0,表示不调整亮度。
contrast:控制对比度调整的范围。如果是一个浮点数 c,则对比度因子会在 [1−c,1+c]之间随机选择,默认值为 0,表示不调整对比度。
saturation:控制饱和度调整的范围。如果是一个浮点数 s,则饱和度因子会在 [1−s,1+s]之间随机选择,默认值为 0,表示不调整饱和度。
hue:控制色调调整的范围,取值范围为 [−0.5,0.5]之间的浮点数。如果是一个浮点数 h,则色调会在 [−h,h] 之间随机调整,默认值为 0,表示不调整色调。
4.结合多种图像增广的方法
使用一个Compose实例来综合上面定义的不同的图像增广方法,并应用到每个图片上
torchvision.transforms.Compose([
torchversion.transforms.RandomHorizontalFlip(),
torchversion.transforms.ColorJitter(
brightness,contrast,saturation,hue),torchversion.transforms.RandomResizedCrop(
size,scale,ratio)])
5.对图片应用这些变化
变量 = 这些变化
newImage = 变量(要变化的图片)
6.transforms.RandomRotation()
随机旋转图像一定角度范围。
transform = transforms.RandomRotation(30) # 在 -30 到 30 度之间随机旋转
7.transforms.ToTensor()
将 PIL 图像或 NumPy 数组转换为 PyTorch 的张量,并且将像素值从 [0, 255] 归一化到 [0, 1]。
transform = transforms.ToTensor()
8.transforms.Normalize()
对图像张量进行归一化,常用于图像标准化处理。
mean和std是图像的均值和标准差,按通道分别指定。
transform = transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])
十一、pandas(数据分析工具)
使用
pandas库轻松地读取 CSV 文件并查看其内容,pandas是一个功能强大、灵活且易于使用的数据分析和数据处理库,特别适合处理结构化数据,比如 CSV 文件、Excel 表格等。以下是一些pandas的基本用法和概念,帮助你快速上手。
1.读取CSV文件
pandas提供了非常方便的方法来读取 CSV 文件
# 读取 CSV 文件
data = pd.read_csv('your_file.csv') # 替换为你的 CSV 文件路径
# 查看数据前五行
print(data.head())2.查看数据
head():查看数据的前几行(默认为 5 行)。tail():查看数据的最后几行(默认为 5 行)。shape:查看数据的维度(行数和列数)。columns:查看数据的列名。info():查看数据的总体信息,如每列的数据类型和非空值数量。
3.访问数据
1.使用列名访问特定列:
# 获取特定列
print(data['column_name']) # 替换 'column_name' 为你的列名也可以直接data[一个列表] ,选择这个列表中的列
2. 使用
iloc和loc访问特定行和列:
# 使用行索引访问
print(data.iloc[0]) # 获取第一行
print(data.iloc[:, 0]) # 获取第一列
# 使用标签访问
print(data.loc[0, 'column_name']) # 获取第一行某个列的数据4.处理缺失值
1.检查缺失值
print(data.isnull().sum()) # 每列缺失值的数量2.填充缺失值
data.fillna(0, inplace=True) # 将缺失值填充为 03.删除包含缺失值的行
data.dropna(inplace=True) # 删除包含缺失值的行5.描述性统计
获取数据的基本统计信息,如平均值、标准差、最小值、最大值等
print(data.describe())6.保存数据到CSV文件
你可以将处理后的数据保存到一个新的 CSV 文件:
data.to_csv('new_file.csv', index=False) # 不保存索引列7.选取和筛选数据
1.选取多列:
selected_data = data[['column1', 'column2']] # 替换为你的列名2.根据条件筛选数据:
filtered_data = data[data['column_name'] > 10] # 替换为你的筛选条件8.pd.concat()
pd.concat是pandas中一个非常实用的函数,用于沿着指定轴(行或列)将多个DataFrame或Series拼接在一起。它允许你进行简单的合并操作,比如将多个数据集拼接为一个大的数据集,或者进行纵向(按行)或横向(按列)拼接。
1.拼接多个
DataFrame(按行拼接):按行拼接意味着将多个
DataFrame垂直地拼接在一起(即,添加更多行)。这时,所有DataFrame必须具有相同的列名。import pandas as pd # 创建两个 DataFrame df1 = pd.DataFrame({'A': [1, 2], 'B': [3, 4]}) df2 = pd.DataFrame({'A': [5, 6], 'B': [7, 8]}) # 按行拼接 result = pd.concat([df1, df2], axis=0) print(result) oupt: A B 0 1 3 1 2 4 0 5 7 1 6 8
2.拼接多个
DataFrame(按列拼接)按列拼接意味着将多个
DataFrame水平地拼接在一起(即,添加更多列)。这时,所有DataFrame必须具有相同的行索引。# 按列拼接 result = pd.concat([df1, df2], axis=1) print(result) oupt: A B A B 0 1 3 5 7 1 2 4 6 8
3.忽略索引,重新排序索引
在拼接时,通常会保留原有的索引。如果你希望忽略原始索引并重新排序索引,可以使用
ignore_index=True。# 忽略索引并重新排序 result = pd.concat([df1, df2], axis=0, ignore_index=True) print(result) oupt: A B 0 1 3 1 2 4 2 5 7 3 6 8
4.处理不同列名的拼接
当两个
DataFrame的列名不完全相同时,pd.concat会自动填充缺失的列,并将其填充为NaN。df1 = pd.DataFrame({'A': [1, 2], 'B': [3, 4]}) df2 = pd.DataFrame({'A': [5, 6], 'C': [7, 8]}) # 拼接时列名不完全相同 result = pd.concat([df1, df2], axis=0, ignore_index=True) print(result) oupt: A B C 0 1 3.0 NaN 1 2 4.0 NaN 2 5 NaN 7.0 3 6 NaN 8.0
5.使用
keys创建多级索引你还可以使用
keys参数给拼接的DataFrame添加多级索引,便于区分不同的部分。# 使用 keys 参数创建多级索引 result = pd.concat([df1, df2], axis=0, keys=['df1', 'df2']) print(result) oupt: A B C df1 0 1 3 NaN 1 2 4 NaN df2 0 5 NaN 7.0 1 6 NaN 8.0
6.拼接
Series
pd.concat同样可以拼接多个Series对象:s1 = pd.Series([1, 2], name='A') s2 = pd.Series([3, 4], name='A') # 拼接 Series result = pd.concat([s1, s2]) print(result) oupt: 0 1 1 2 0 3 1 4 Name: A, dtype: int64
9.pd.get_dummies()
pd.get_dummies是pandas中用于将分类变量(如字符串类型或分类数据)转换为 虚拟变量(即 One-Hot Encoding)的函数。这个方法可以把分类数据列转化为一组二元变量,便于模型的训练。
1.基本用法:
如果你有一个包含分类数据的列,
pd.get_dummies可以将该列转换为虚拟变量。例如,将['cat', 'dog', 'cat']转换为cat和dog的虚拟变量。import pandas as pd # 创建一个简单的数据 data = pd.DataFrame({ 'Animal': ['cat', 'dog', 'cat', 'dog', 'fish'] }) # 使用 get_dummies 将 Animal 列转换为虚拟变量 dummies = pd.get_dummies(data['Animal']) print(dummies) outpt: cat dog fish 0 1 0 0 1 0 1 0 2 1 0 0 3 0 1 0 4 0 0 1
2. 对整个
DataFrame进行转换如果你有多个分类变量列,并希望一次性将整个
DataFrame转换为虚拟变量,可以直接传递整个DataFrame给pd.get_dummies。# 创建包含多个分类列的数据 data = pd.DataFrame({ 'Animal': ['cat', 'dog', 'cat', 'dog', 'fish'], 'Color': ['black', 'brown', 'white', 'brown', 'black'] }) # 对整个 DataFrame 进行虚拟变量转换 dummies = pd.get_dummies(data) print(dummies) outpt: Animal_cat Animal_dog Animal_fish Color_black Color_brown Color_white 0 1 0 0 1 0 0 1 0 1 0 0 1 0 2 1 0 0 0 0 1 3 0 1 0 0 1 0 4 0 0 1 1 0 0
3. 控制列名
你可以使用
prefix和prefix_sep参数来控制新列的列名。# 控制列名前缀 dummies = pd.get_dummies(data['Animal'], prefix='Type') print(dummies) outpt: Type_cat Type_dog Type_fish 0 1 0 0 1 0 1 0 2 1 0 0 3 0 1 0 4 0 0 1
4. 处理缺失值
pd.get_dummies也可以处理缺失值,它将缺失值处理为一个额外的列。# 创建包含缺失值的 DataFrame data_with_nan = pd.DataFrame({ 'Animal': ['cat', 'dog', None, 'dog', 'fish'] }) # 转换数据时保留缺失值列 dummies = pd.get_dummies(data_with_nan['Animal'], dummy_na=True) print(dummies) outpt: cat dog fish NaN 0 1 0 0 0 1 0 1 0 0 2 0 0 0 1 3 0 1 0 0 4 0 0 1 0
5. 限制转换的列
如果你只想对特定的列进行
get_dummies操作,可以传递一个列名列表。# 只转换 "Animal" 列 dummies = pd.get_dummies(data[['Animal']]) print(dummies) outpt: cat dog fish 0 1 0 0 1 0 1 0 2 1 0 0 3 0 1 0 4 0 0 1
10.astype
astype是pandas中用来转换DataFrame或Series数据类型的方法。通过astype,你可以将数据从一种类型转换为另一种类型,这对于数据清洗和预处理非常有用。
1. 基本用法
假设你有一个
DataFrame或Series,并且你希望改变某一列或整个数据集的类型。你可以使用astype方法。
1.1 转换
Series的数据类型例如,将一个
Series中的数值类型从float64转换为int32:
import pandas as pd
# 创建一个 Series
s = pd.Series([1.1, 2.2, 3.3, 4.4])
# 转换数据类型为 int32
s_int = s.astype('int32')
print(s_int)
output:
0 1
1 2
2 3
3 4
dtype: int32
1.2 转换
DataFrame的列类型你也可以转换
DataFrame中单独某一列的数据类型。例如,将DataFrame中的一列从float转换为int:
# 创建一个 DataFrame
df = pd.DataFrame({
'A': [1.1, 2.2, 3.3],
'B': [4.4, 5.5, 6.6]
})
# 将列 'A' 的数据类型转换为 int
df['A'] = df['A'].astype('int32')
print(df)
output
A B
0 1 4.4
1 2 5.5
2 3 6.6
1.3 转换多个列的类型
如果你希望同时转换多个列的数据类型,可以将一个字典传递给
astype,字典的键是列名,值是目标数据类型。
# 将 'A' 列转换为 int32,'B' 列转换为 float64
df = df.astype({'A': 'int32', 'B': 'float64'})
print(df)
output:
A B
0 1 4.4
1 2 5.5
2 3 6.6
1.4 常见数据类型转换
- 整数类型:
'int32','int64','int8'等- 浮点类型:
'float32','float64','float16'等- 字符串类型:
'str','string'- 布尔类型:
'bool'- 日期时间类型:
'datetime64'
例如,转换为日期时间类型:
# 创建一个日期时间字符串的 Series
dates = pd.Series(['2020-01-01', '2021-02-02', '2022-03-03'])
# 转换为 datetime 类型
dates = dates.astype('datetime64')
print(dates)
output:
0 2020-01-01
1 2021-02-02
2 2022-03-03
dtype: datetime64[ns]
2. 错误处理
如果数据不能正确地转换为指定的数据类型,
astype会抛出错误。例如,尝试将包含非数字字符的列转换为数字类型:
# 创建一个包含非数字字符串的 Series
s = pd.Series(['a', 'b', 'c'])
# 尝试将其转换为整数
try:
s = s.astype('int32')
except ValueError as e:
print(f"错误: {e}")
output:
错误: invalid literal for int() with base 10: 'a'
3. 使用
astype时的注意事项
- 数据丢失:在进行类型转换时,确保不会丢失数据。例如,将浮点数转换为整数时,小数部分将被舍弃。
- 内存占用:不同的数据类型会占用不同的内存空间。在处理大数据集时,可以考虑选择适当的数据类型以节省内存。
4. 转换为
category类型在处理具有有限类别值的列时,
category类型可以显著减少内存使用,并提高某些操作的性能。例如,对于有许多相同值的列,可以将其转换为category类型。
# 创建一个有重复类别值的列
data = pd.Series(['cat', 'dog', 'cat', 'bird', 'dog', 'cat'])
# 将该列转换为 'category' 类型
data = data.astype('category')
print(data)
output:
0 cat
1 dog
2 cat
3 bird
4 dog
5 cat
dtype: category
Categories (3, object): ['bird', 'cat', 'dog']11.Series
Series是pandas中最基本的数据结构之一,类似于一个一维的数组或列表,但它的元素是有标签(即索引)的。你可以将Series看作是一个带标签的数组,可以通过标签来访问数据,而不仅仅是通过位置索引。
12.prefix
在
pandas中,prefix是一个常用于函数参数的选项,特别是在处理列名时。最常见的应用场景是在pd.get_dummies函数中,用来为生成的虚拟变量(One-Hot Encoding)列添加一个前缀。这个前缀可以帮助标识转换后的列,使得列名更加清晰、易于理解。添加前缀: Color_Blue Color_Green Color_Red 0 0 0 1 1 1 0 0 2 0 0 1 3 0 1 0 未添加前缀: Blue Green Red 0 0 0 1 1 1 0 0 2 0 0 1 3 0 1 0
13.train_df['Age'].fillna(train_df['Age'].mean())
这行代码的作用是用
train_df中 'Age' 列的均值填充缺失值。不过,这样的写法并不会直接修改原始数据,需要将结果重新赋值给train_df['Age'],或者使用inplace=True参数来就地修改。train_df['Age'] = train_df['Age'].fillna(train_df['Age'].mean()) 使用 inplace=True train_df['Age'].fillna(train_df['Age'].mean(), inplace=True)
14.查看缺失值的字段
要查看哪些字段有缺失值,你可以使用 Pandas 中的
isnull()和sum()函数,这样可以快速检查数据中哪些列有缺失值以及缺失值的数量。
# 只显示有缺失值的列 missing_values = train_df.isnull().sum() missing_values = missing_values[missing_values > 0] print(missing_values)
isnull()会返回一个布尔值的 DataFrame,其中每个值是True(如果是缺失值)或False(如果不是缺失值)。sum()函数会计算每列中True值的数量,即每个字段中的缺失值数量。
15.只查看有缺失值的字段
# 只显示有缺失值的列 missing_values = train_df.isnull().sum() missing_values = missing_values[missing_values > 0] print(missing_values)这会列出所有含有缺失值的字段,并显示缺失值的数量。
16.编码类别变量
编码类别变量(Categorical Encoding)是指将分类数据(通常是文本形式的标签)转换成模型可以理解的数值格式。机器学习模型,尤其是像神经网络、决策树等大多数算法,通常不能直接处理文本数据,它们只能处理数值数据,因此需要对类别变量进行编码。
不需要编码的字段:
数值型的字段不用编码
需要编码的字段:
二分类
多分类
其他的字段
17.map
map方法是 pandas 中的一个功能,它根据给定的字典将列中的值替换成字典中对应的值。train_df['Sex'] = train_df['Sex'].map({'male': 0, 'female': 1})
18.values
.values是 pandas 中的一个属性,它将 DataFrame 转换为 NumPy 数组。这样,你就得到了一个二维的数组(即X_train),其中每一行代表一个样本,列表示每个特征。
19.mean = X_tain.mean(axis=0)
X_train:
- 这是一个包含训练数据的 NumPy 数组或 pandas DataFrame。假设它的形状为
(n_samples, n_features),即每行是一个样本,每列是一个特征。
mean(axis=0):
mean()是一个计算均值的函数,默认情况下,mean()会计算所有元素的均值。axis=0指定了沿着哪个轴计算均值。在二维数据(矩阵)的情况下:
axis=0表示按列计算均值,即对每个特征(列)计算均值。axis=1表示按行计算均值,即对每个样本(行)计算均值。因此,
X_train.mean(axis=0)会计算每个特征(列)的均值,并返回一个包含所有特征均值的向量。这个向量的长度与X_train的列数相同。
十二、大模型相关知识
1.transformers.modeling_outputs
这段代码从 transformers.modeling_outputs 模块中导入了两个类:BaseModelOutputWithPast 和 CausalLMOutputWithPast。这两个类用于定义模型输出的结构,特别是在处理自然语言生成任务时,包含过去的隐藏状态信息。
BaseModelOutputWithPast:用于基础模型的输出,包含过去的隐藏状态。
CausalLMOutputWithPast:用于因果语言模型的输出,同样包含过去的隐藏状态,但更适用于生成式任务。
1.CausalLMOutputWithPast详解
CausalLMOutputWithPast 是一个在使用基于因果语言模型(Causal Language Model,CausalLM)(自回归模型)时返回的对象类型,通常与 Transformer 模型(如 GPT 系列)一起使用。在 Hugging Face 的 Transformers 库中,CausalLMOutputWithPast 是一个专门用于处理因果语言模型输出的类。它主要包含以下几个部分:
自回归生成(Autoregressive Generation)方式。简单来说,就是模型生成一个词,然后基于这个词继续生成下一个词,一直到生成完整的句子或段落。
1. logits:
- 类型:
torch.Tensor - 说明:
logits是模型的输出,即对每个词汇(或词汇表中的每个token)的预测分数。它们是原始的预测概率(未经 softmax 转换),表示每个词汇出现在当前位置的可能性。
2. past_key_values:
-
类型: Tuple of
torch.Tensor(通常是元组或列表) -
说明:
past_key_values存储了模型在计算时的过去状态(例如注意力的键值对)。这个返回值可以帮助在序列生成过程中复用之前的计算结果,从而提高生成效率,尤其是在生成长文本时。通过这个机制,模型可以避免重复计算前面的步骤。 -
对于 GPT 等自回归语言模型,这些
past_key_values是模型中每一层的键(key)和值(value)。它们是上一轮计算时生成的注意力信息,用于加速后续的推理过程。
3. hidden_states (可选):
- 类型:
tuple(或None) - 说明:
hidden_states是模型的中间层输出。如果你需要访问中间层的激活状态,hidden_states会包含每一层的输出(通常是对每一层的特征表示)。
4. attentions (可选):
- 类型:
tuple(或None) - 说明:
attentions包含了每一层的注意力权重。它们是注意力机制在每一层的计算结果,用来衡量序列中不同位置之间的相关性。
5. loss (可选):
- 类型:
torch.Tensor(或None) - 说明: 如果提供了目标标签(通常在训练时),模型会返回损失值。这个损失值是通过计算模型输出与真实标签之间的差异来衡量模型的表现,通常用于反向传播和更新模型权重。
示例:
假设你正在使用 GPT 类的语言模型,调用 model(input_ids) 时,返回值可能类似于:
CausalLMOutputWithPast(
logits = tensor([...]),
past_key_values = (tensor([...]), tensor([...]), ...),
hidden_states = (tensor([...]), tensor([...]), ...),
attentions = (tensor([...]), tensor([...]), ...),
loss = tensor([...])
)主要用途:
-
提升推理效率:
past_key_values使得在进行自回归生成时,能够利用之前计算的中间状态,避免重复计算。每次生成新词时,模型只需要计算最新的 token,而无需从头开始重新计算之前的所有 token。 -
处理长文本生成:长文本生成时,通过
past_key_values可以避免每次生成新 token 时都需要重新计算整个上下文,从而提高生成效率。
使用场景:
- 文本生成:如 GPT 系列模型,用于自动文本生成、对话生成、摘要生成等。
- 增量推理:在生成过程中逐步处理输入,每次生成一个新 token,
past_key_values允许模型仅计算最新的部分,减少不必要的计算。
2.模型检查点
模型的检查点(Checkpoint)是深度学习训练过程中保存模型状态的一种方式。通常,检查点包括以下内容:
-
模型的权重:神经网络的所有参数(例如权重和偏置)在某一时刻的值。保存这些权重使得可以在之后恢复模型,而无需重新训练。
-
优化器的状态:优化器的状态包括关于梯度和学习率调整的信息,如动量、学习率等。优化器状态的保存可以保证从检查点恢复时,优化器继续以相同的方式进行训练。
-
当前训练轮次(epoch):保存当前训练的轮次或步骤数,这样在恢复训练时,可以从该轮次开始,避免丢失训练进度。
-
其他可能的训练元数据:例如损失函数值、训练时的其他超参数等。
检查点的作用主要体现在以下几个方面:
-
中断恢复:训练可能会因为某些原因中断(如硬件故障、时间限制等),此时可以从最后一个检查点恢复训练,而不需要重新从头开始。
-
模型保存与选择:通常训练过程中,模型的性能会在某个点达到最佳,可以通过保存多个检查点,选择在验证集上表现最好的模型进行最终评估或应用。
-
过拟合防止:可以在训练过程中定期保存检查点,并选择性能最好的检查点,避免模型训练过程中的过拟合。
如何使用
在训练时,通常会设置一个策略来定期保存检查点,例如每隔一定的迭代次数保存一次,或者当验证集上的性能改善时保存一个检查点。
例如,在PyTorch中,可以通过torch.save()来保存模型检查点:
torch.save({
'epoch': epoch,
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'loss': loss,
}, checkpoint_path)恢复检查点时,可以使用torch.load()加载并恢复模型状态:
checkpoint = torch.load(checkpoint_path)
model.load_state_dict(checkpoint['model_state_dict'])
optimizer.load_state_dict(checkpoint['optimizer_state_dict'])
epoch = checkpoint['epoch']
loss = checkpoint['loss']这种方法可以让训练过程更为灵活和稳定。
3.分词器(Tokenizer)
分词器(Tokenizer)是自然语言处理(NLP)中的一个工具,用于将文本字符串分解成更小的单元(通常是词语、子词或字符),以便计算机能够理解和处理。这个过程被称为分词。
分词器的作用
-
文本预处理:在NLP中,文本数据通常需要经过分词处理,才能转化为模型可以处理的形式。原始文本可能包含空格、标点符号、大小写等,这些都需要通过分词器进行清洗和分解。
-
构建词汇表:分词器会根据分词规则构建一个词汇表,将每个单元(如词或子词)映射到一个唯一的标识符(通常是数字ID)。这个词汇表是模型训练的基础。
-
为模型输入做准备:大多数NLP模型(如BERT、GPT等)需要输入的文本数据是由单词或子词的ID构成的,而不是原始文本。因此,分词器将文本转换成模型能够接受的数字形式。
分词的方式
分词器的工作方式通常有不同的策略,常见的包括:
-
基于空格分词:
- 这种方法是最简单的,它将文本根据空格分成单词(例如:"I love AI" -> ["I", "love", "AI"])。
- 这种方法通常只适用于英文等空格清晰分隔的语言。
-
基于规则的分词:
- 通过使用语言学规则来分词。例如,英文中的连字符(如“self-employed”)和缩写(如“I'm”)可能需要特殊处理。
-
基于子词的分词:
- 在某些情况下,单词本身不能很好地处理文本中的所有情况(例如,OOV词汇)。子词分词技术(如BPE,Byte Pair Encoding、WordPiece、SentencePiece)通过将单词进一步分解为子词单元来处理这些问题。
- 例如,“unhappiness”可以分解成["un", "happiness"]或["un", "happi", "ness"]。
-
基于字符的分词:
- 在一些语言(如中文)中,字符本身通常就代表基本的语言单元,因此可以将字符作为最小单位进行分词。
- 例如:"你好,世界" -> ["你", "好", ",", "世", "界"]。
-
基于词典的分词:
- 在一些语言中(如中文、日文),分词器会依赖词典来进行分词。它通过查找最常见的词组来将文本分成词。
4.ChatML
ChatML 是 OpenAI 提出的一个简单的标记语言(Markup Language),专门用来帮助模型理解和处理多轮对话中的结构化内容。它类似于聊天的格式化工具,能够明确区分谁在说话(比如用户还是 AI),以及对话的内容。
ChatML 的核心点
-
明确区分角色
- 在对话中,有多个参与者,比如
user(用户)、assistant(AI 助手)和system(系统提示)。ChatML 用特定的格式标记每个角色的发言内容。
- 在对话中,有多个参与者,比如
-
结构化格式
- ChatML 通过简单的格式标记文本,帮助模型理解对话的上下文和发言者角色。
-
简单易用
- 和 HTML 等复杂标记语言相比,ChatML 非常简单。它只有少量规则,适用于对话系统。
<|system|>
You are a helpful assistant.
<|user|>
What's the weather like today?
<|assistant|>
The weather is sunny with a high of 25°C.<|system|>: 系统提示,用来给 AI 设置上下文或指导,比如“你是一个善解人意的助手”。<|user|>: 用户的输入。<|assistant|>: AI 助手的响应。
通俗解释 ChatML 的作用
假设你和 AI 聊天,可能会发生以下问题:
- 谁说了什么?如果不明确标记,AI 很可能混淆。
- 如何设置 AI 的语气和风格?需要一个系统提示让 AI 明白它的角色。
ChatML 就是用来解决这些问题的:
- 分清发言者:标记哪个是用户的输入,哪个是 AI 的回复。
- 指导 AI 行为:通过
system提示,告诉 AI 如何表现。 - 保持上下文清晰:多轮对话中,ChatML 格式能让 AI 理解整个对话的逻辑。
5.停词
停词列表(Stop Words List)是一组在自然语言处理(NLP)任务中被认为对任务目标没有太大贡献的词。例如,在文本生成、文本分类或搜索引擎中,这些词通常被过滤掉以减少噪声。
停词的定义
停词是指在语言中频率很高但通常对语义或任务目标意义较小的词,比如:
- 英文中的 “a,” “the,” “is,” “in,” “and”
- 中文中的 “的,” “了,” “在,” “和”
虽然这些词语对句子结构有重要作用,但在某些 NLP 任务中,它们并不帮助区分文档或句子的具体含义。
停词列表的作用
在生成任务中,例如文本生成或对话生成,停词列表(
stop_words_ids)可以用来限制模型生成某些词。这个功能通常应用于以下场景:
避免生成无意义词语
在一些特定任务中,可以通过停词列表阻止模型生成无用或冗余的词。实现关键词屏蔽
如果有特定的词语或短语需要避免(比如敏感词),可以将其加入停词列表。提高生成质量
通过限制一些常见但无关紧要的词,可以更好地控制生成内容的主题和质量。
6.流式文本
流式文本(Streaming Text)指的是在生成或处理文本时,不是一次性完成整个内容的生成或输出,而是分段、逐步实时输出内容的一种方式。它类似于“边生成边输出”,用户可以即时看到生成结果的部分内容,而无需等待完整的文本生成完成。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









