









目录
一、安装准备
1.安装VM
4.安装JDK
5.下载Hadoop安装包(本次使用hadoop-2.7.5)
https://archive.apache.org/dist/hadoop/common/
二、服务器环境设置
三、Hadoop安装与环境配置
先用下面的命令给opt文件夹中新建一个hapoop文件夹
mkdir /opt/hadoop然后把hadoop-2.7.5.tar.gz上传到/opt/hadoop文件夹中
使用下面命令进入到hadoop文件夹
cd /opt/hadoop使用下面命令把hadoop-2.7.5进行解压
tar -zxvf hadoop-2.7.5.tar.gz使用下面命令把hadoop-2.7.5文件夹重命名成hadoop
mv hadoop-2.7.5 hadoop1.配置hadoop-env.sh
然后输入下面命令进入该文件所在的文件夹
cd /opt/hadoop/hadoop/etc/hadoop输入下面命令打开文件
vi hadoop-env.sh修改JAVA_HOME地址为服务器jdk安装路径
export JAVA_HOME=/usr/local/java/jdk1.8.0_162/2.配置core-site.xml
vi core-site.xml接着把下面命令写入<configuration></configuration>中,注释不用写
<!-- 指定Hadoop所使用的文件系统schema(URL),HDFS的老大(NameNode)的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<!-- 指定Hadoop运行时产生文件的储存目录,默认是/tmp/hadoop-${user.name} -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop/hadoopdata</value>
</property>3.配置hdfs-site.xml
vi hdfs-site.xml接着把下面命令写入<configuration></configuration>中,注释不用写
<!-- 指定HDFS副本的数量 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>4.配置yarn-site.xml
vi yarn-site.xml接着把下面命令写入<configuration></configuration>中,里面自带的注释不用删除
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:18040</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:18030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:18025</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:18141</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:18088</value>
</property>5.配置mapred-site.xml
还是在/opt/hadoop/hadoop/etc/hadoop目录下(也就是上个文件所在的目录),有一个叫 mapred-site.xml.template的文件,把它复制到/opt/hadoop/hadoop/etc/hadoop目录下(也就是mapred-queues.xml.template文件所在的目录)重命名为mapred-site.xml,命令如下
mv mapred-site.xml.template mapred-site.xml然后用下面命令打开该文件
vi mapred-site.xml接着把下面命令写入<configuration></configuration>中,注释不用写
<!-- 指定mr运行时框架,这里指定在yarn上,默认是local -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>6.配置slaves
vi slaves先把localhost这行删除,然后把下面代码写进去
master
slave0
slave17.配置Hadoop环境变量
输入下面命令开始配置
vi /root/.bash_profile把下面命令添加至最后
export HADOOP_HOME=/opt/hadoop/hadoop
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH然后保存退出输入下面内容使环境变量生效
source /root/.bash_profile8.新建Hadoop运行时产生文件的储存目录
mkdir /opt/hadoop/hadoopdata9.给slave0和slave1复制Hadoop
用下面命令就可以把master的Hadoop复制到slave0上
scp -r /opt/hadoop root@slave0:/opt用下面命令把master的Hadoop复制到slave1上
scp -r /opt/hadoop root@slave1:/opt接着用下面命令把master的环境变量复制到slave0上
scp -r /root/.bash_profile root@slave0:/root接着用下面命令把master的环境变量复制到slave1上
scp -r /root/.bash_profile root@slave1:/root在slave0和slave1服务器上执行
source /root/.bash_profile10.格式化文件系统
在master中输入下面命令格式化文件系统,其余俩台服务器不用,注意该命令只能使用一次
hadoop namenode -format11.启动Hadoop
在master服务器上,先用下面命令进入Hadoop的sbin目录
cd /opt/hadoop/hadoop/sbin然后输入下面命令启动
start-all.sh在三台服务器分别输入jps可以判断是否启动成功,出现下面内容说明成功
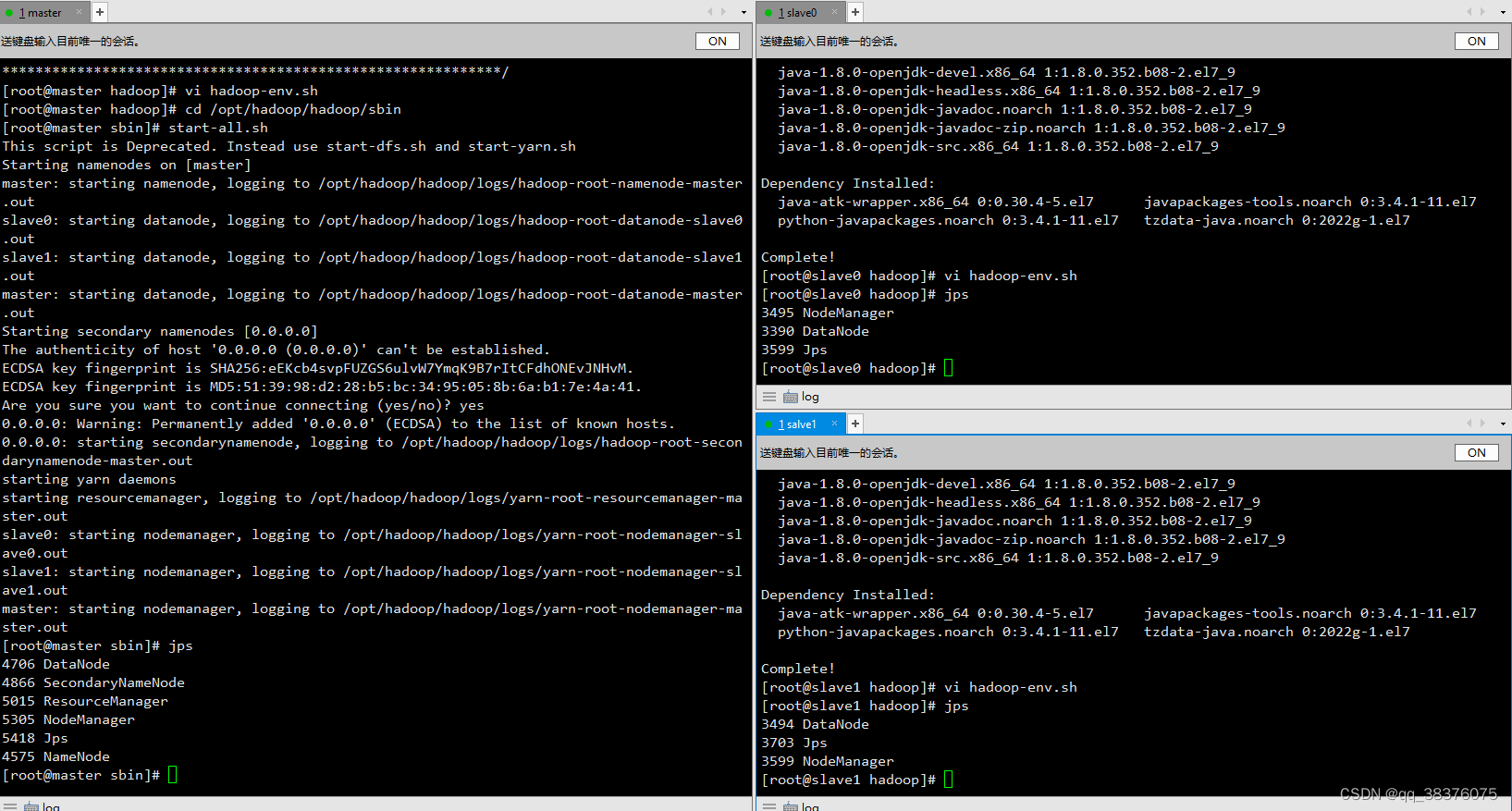
12.关闭Hadoop
只需要在master服务器输入下面命令即可
stop-all.sh13.访问UI页面
http://master:50070

















 44万+
44万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









