






笔者从事Spark组件的开发,工作涉及到Parquet文件相关的知识,本文简要介绍一下Parquet编码相关的知识。
Parquet数据类型
在介绍Parquet编码之前我们需要先了解一下Parquet类型与Spark类型之间的关系,因为在Parquet的实现当中,选择何种编码是根据列对应的类型来决定的。具体的对应关系如下:
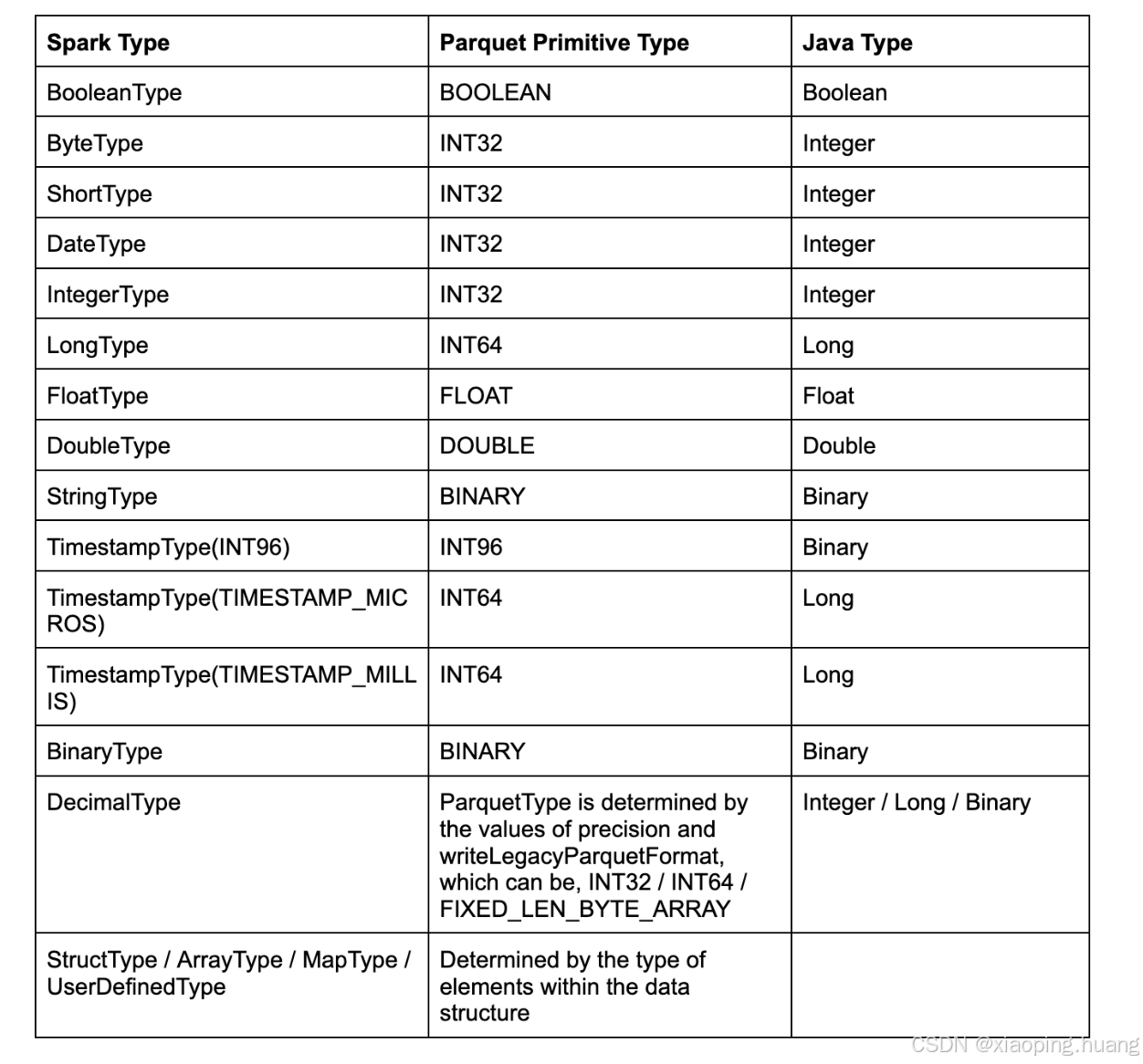 关于Spark读写的时候如何转换到对应的Parquet类型,可以参考Spark代码中的ParquetToSparkSchemaConverter和SparkToParquetSchemaConverter。
关于Spark读写的时候如何转换到对应的Parquet类型,可以参考Spark代码中的ParquetToSparkSchemaConverter和SparkToParquetSchemaConverter。
Parquet ValuesWriter
Parquet的写入有两种实现,通过parquet.writer.version指定,可选的值有v1, v2,默认是v1。writer version会选择对应的ValuesWriterFactory,ValuesWriterFactory会负责为不同的类型选择不同的ValuesWriter。
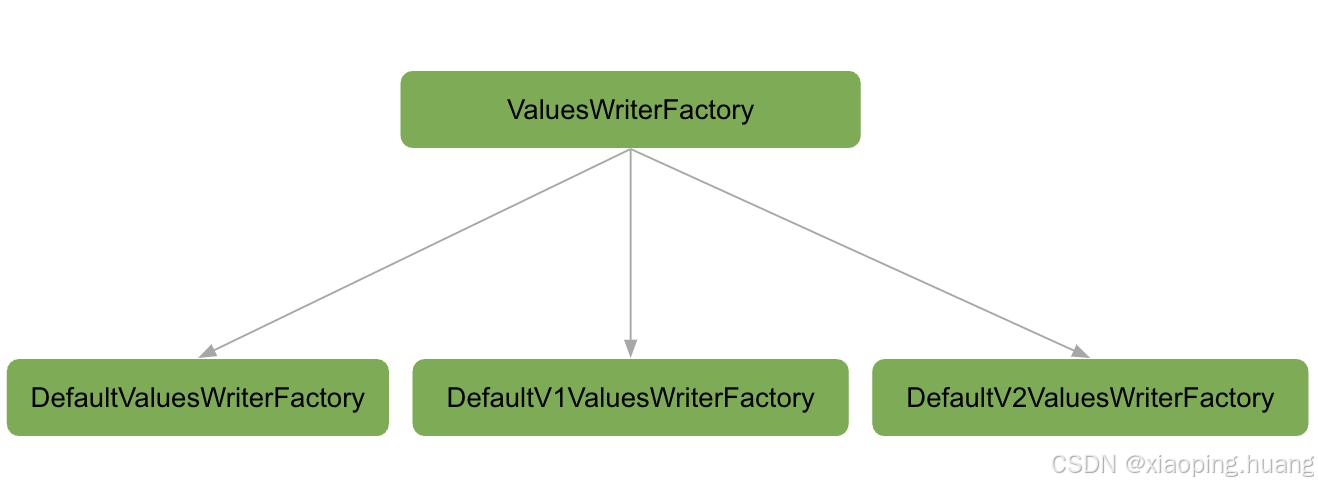
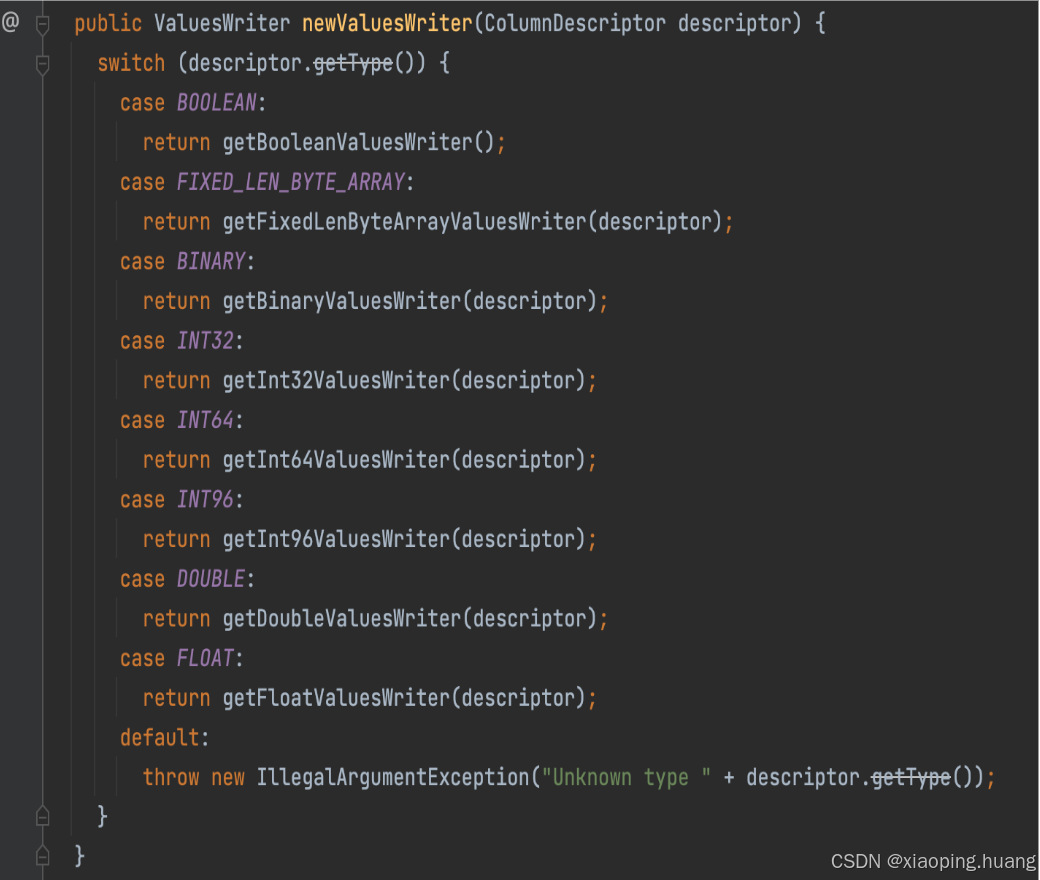
ValuesWriterFactory都会实现newValuesWriter方法:
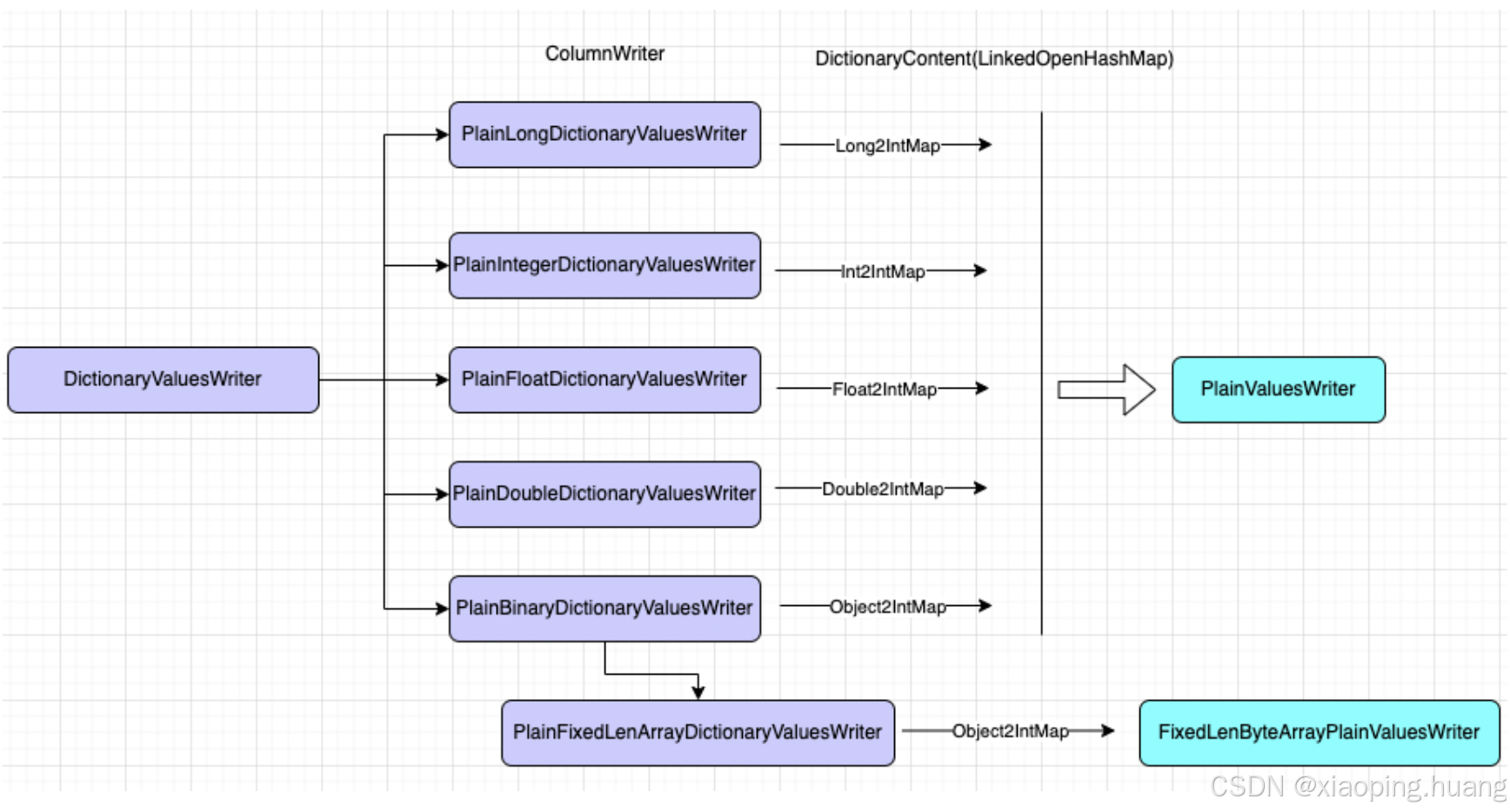
ValuesWriter是负责在写入过程中的实现类,针对每一种类型,Parquet都有对应的ValuesWriter实现,所有的编码实现都在ValuesWriter的子类当中,如下:
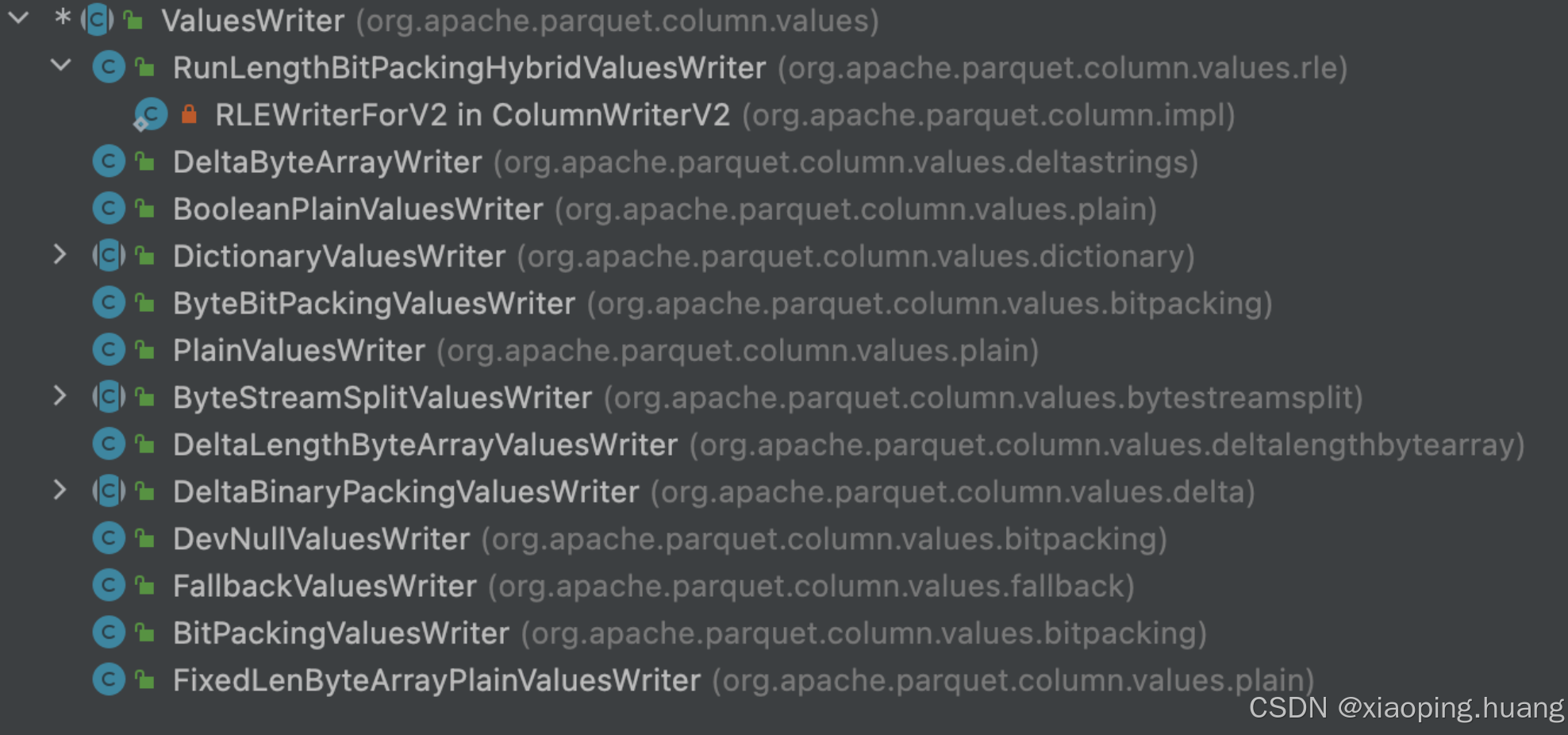
其中FallbackValuesWriter的实现比较特殊,它没有实现具体的编码,而是定义了2个ValuesWriter对象,达到fallback的效果,这里主要是被用于字典编码写入不符合预期的时候进行fallback。
一般initialWriter是DictionaryValuesWriter,fallbackWriter是PlainValuesWriter,currentWriter是一个指针的角色,根据是否fallback指向initialWriter或者fallbackWriter。这顺便提一下什么时候会发生fallback,主要有两种情况,一是使用DictionaryValuesWriter写第一个Page的时候,如果(encodedSize + dictionaryByteSize) < rawSize,则执行fallback。二是当写入具体的value到Page后会进行sizeCheck,检查到Dictionary的Size大于1MB或者Dictionary元素个数大于Integer.MAX_VALUE - 1也会进行fallback。
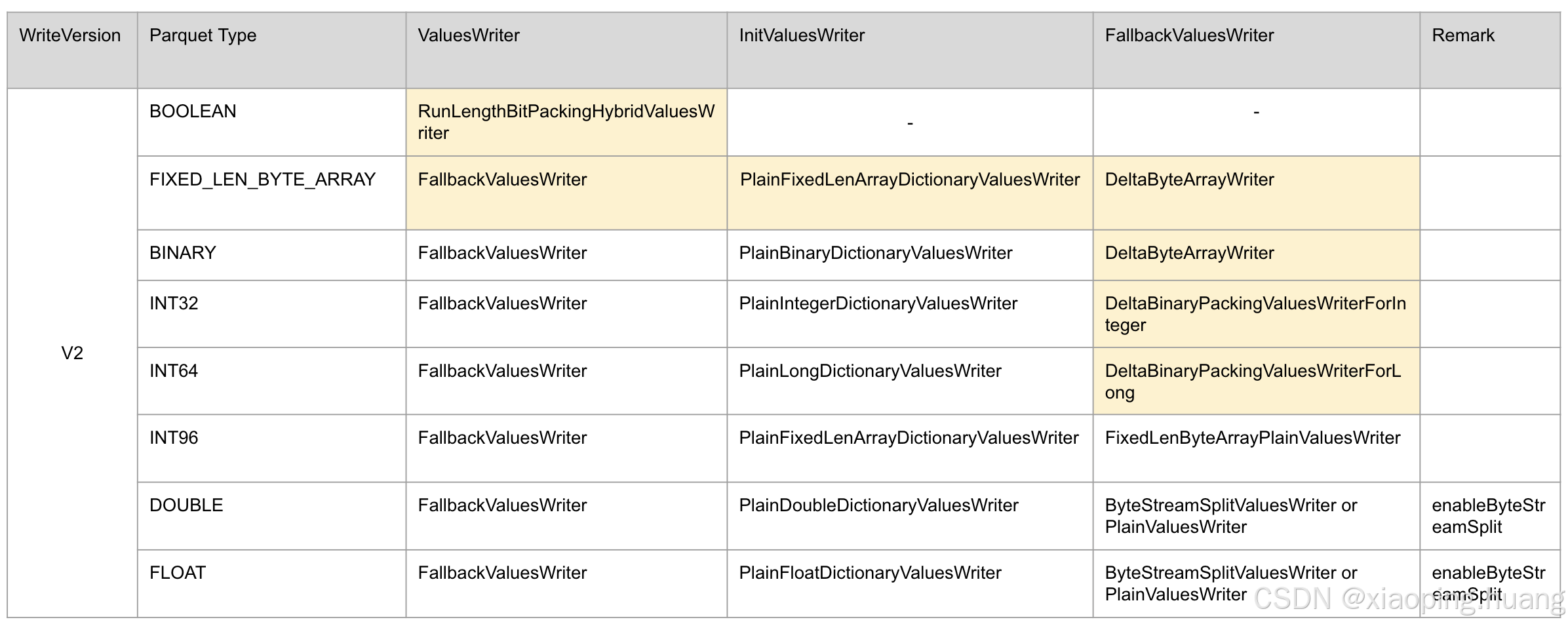
笔者整理了V1和V2具体的ValuesWriter,V2主要是增加了Delta 编码相关的ValuesWriter,具体区别在下面图片黄色的部分: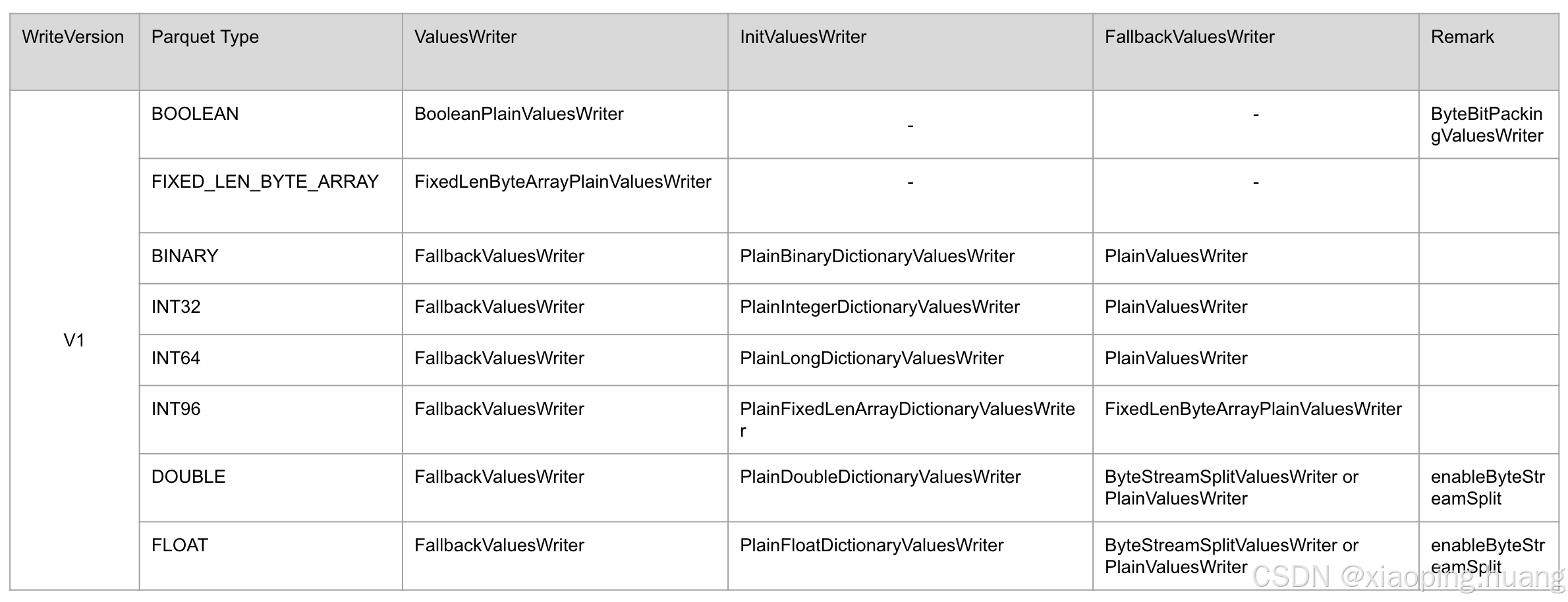
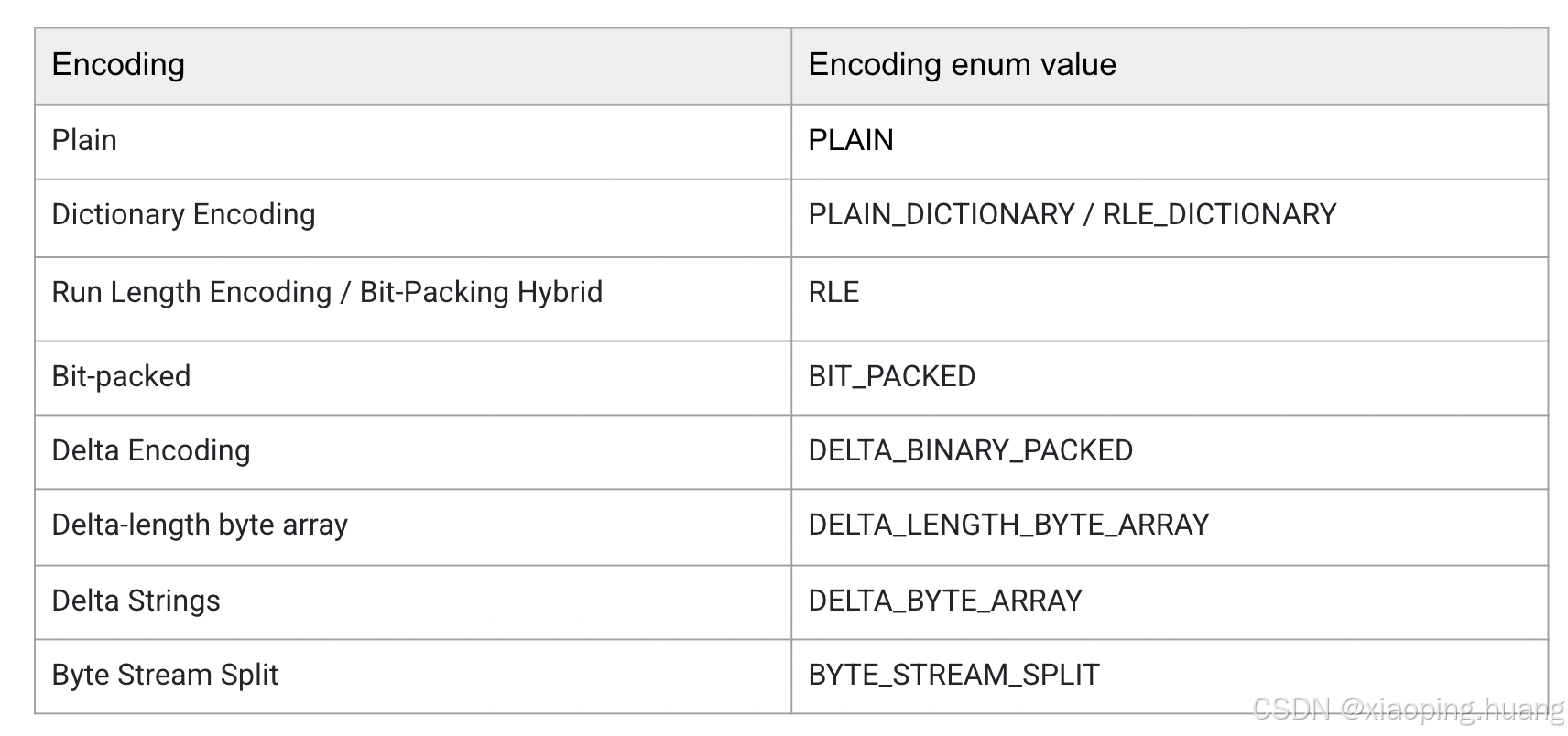
Parquet编码(Encoding)
Parquet的编码是为了重新调整数据的分布,从而让数据存储更加高效,实现了的编码如下:
这一部分为了方便理解需要结合图片和文字讲解,比较难一两句话讲清楚,需要结合原理和看具体的代码理解,所以这里先偷个懒,直接贴一下整理过的PPT,后面有时间了再针对每种编码进行详细的介绍:
PLAIN
PLAIN编码就是明文存储,具体的实现是Little-endian:

BIT_PACKED
bit_packed只支持Integer和boolean类型,因为其实现的原因,排序对这种编码的影响不大:

Run Length Encoding / Bit-Packing Hybrid
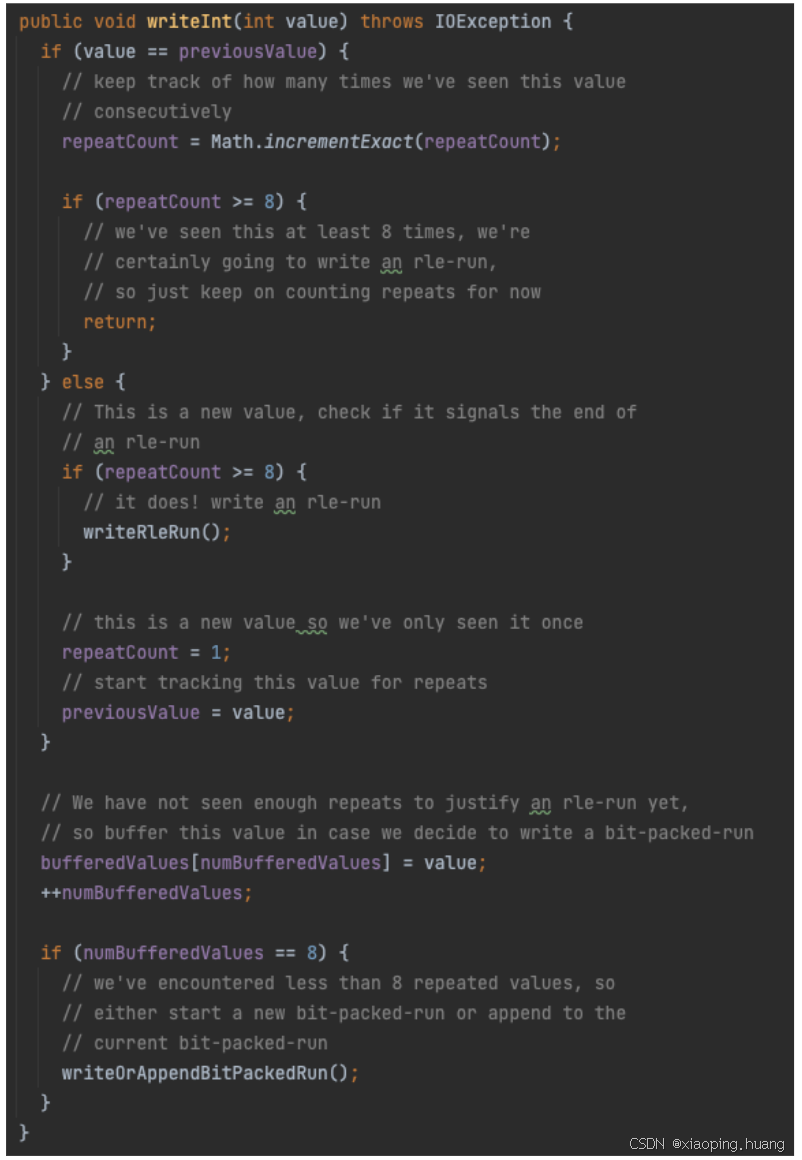
这个是RLE和bit-packing的混合编码,结合了两种的优点,在V2当中是Boolean类型的默认编码,同时还被用于Dictionary indices和definition / repetition level的写入。下面简单介绍了什么时候用RLE,什么时候用bit- packing,这里就不重复描述了:

下面的代码是何时使用RLE或者bit-packing的条件判断:
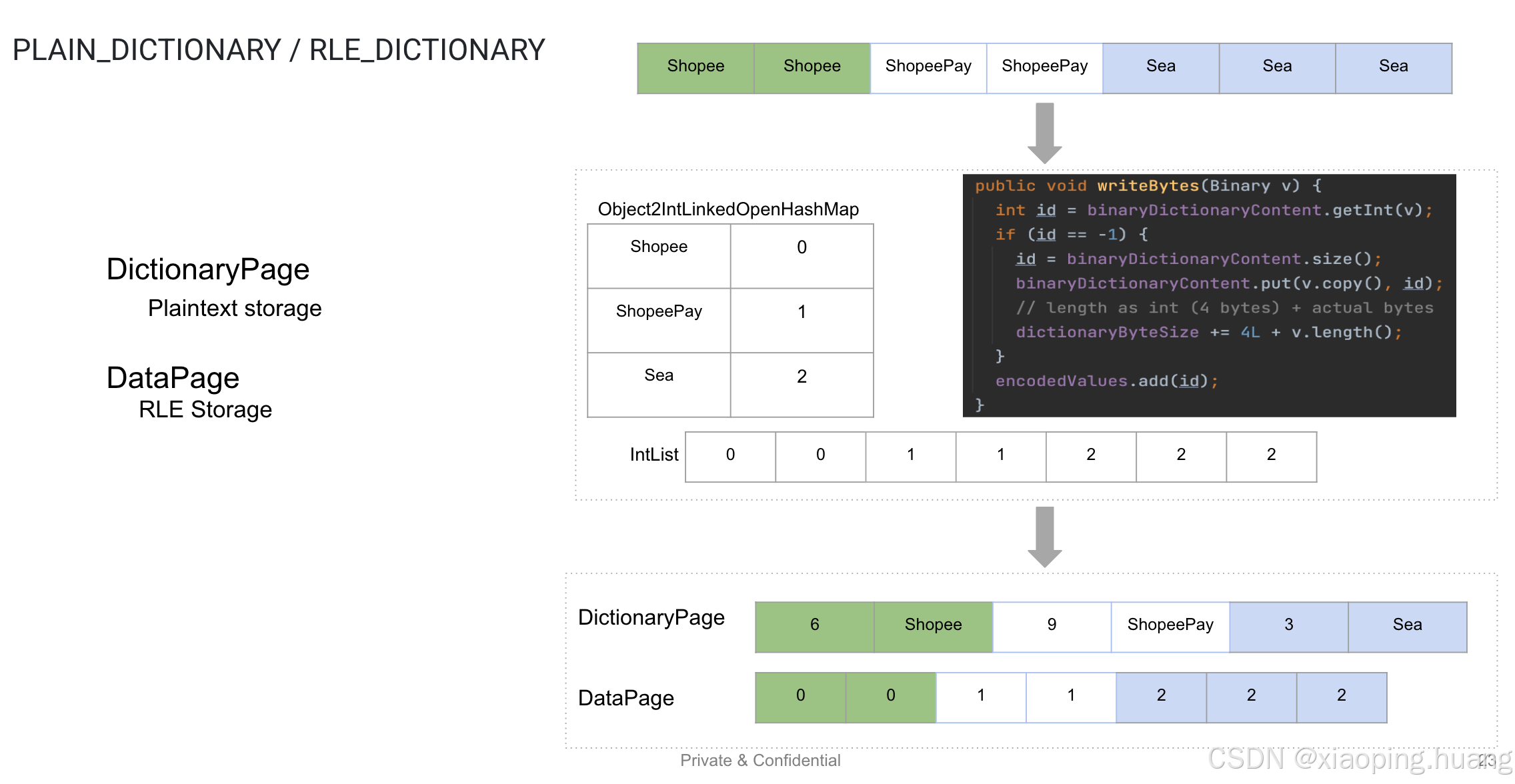
PLAIN_DICTIONARY / RLE_DICTIONARY
这块是字典编码,字典的文本是PLAIN编码明文存储的,字典index是RLE混合编码的实现:
Delta Encoding
下面是增量编码(delta encoding的部分),Parquet实现了三种delta编码,分别是DELTA_BINARY_PACKED,DELTA_LENGTH_BYTE_ARRAY, DELTA_BYTE_ARRAY,实现的ValuesWriter之间存在继承和调用的关系,关系图见下图:
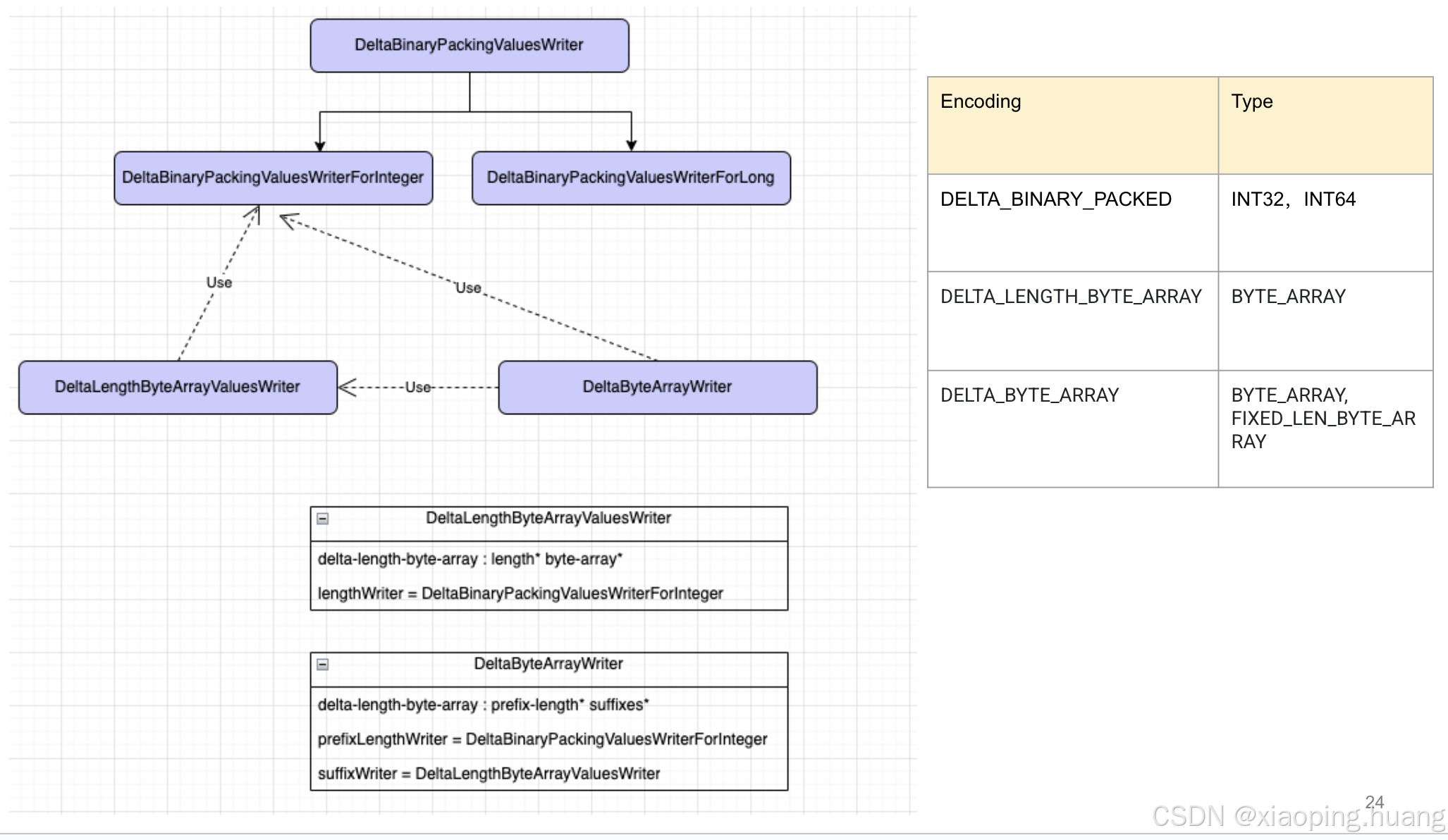
DELTA_BINARY_PACKED

DELTA_LENGTH_BYTE_ARRAY

DELTA_BYTE_ARRAY

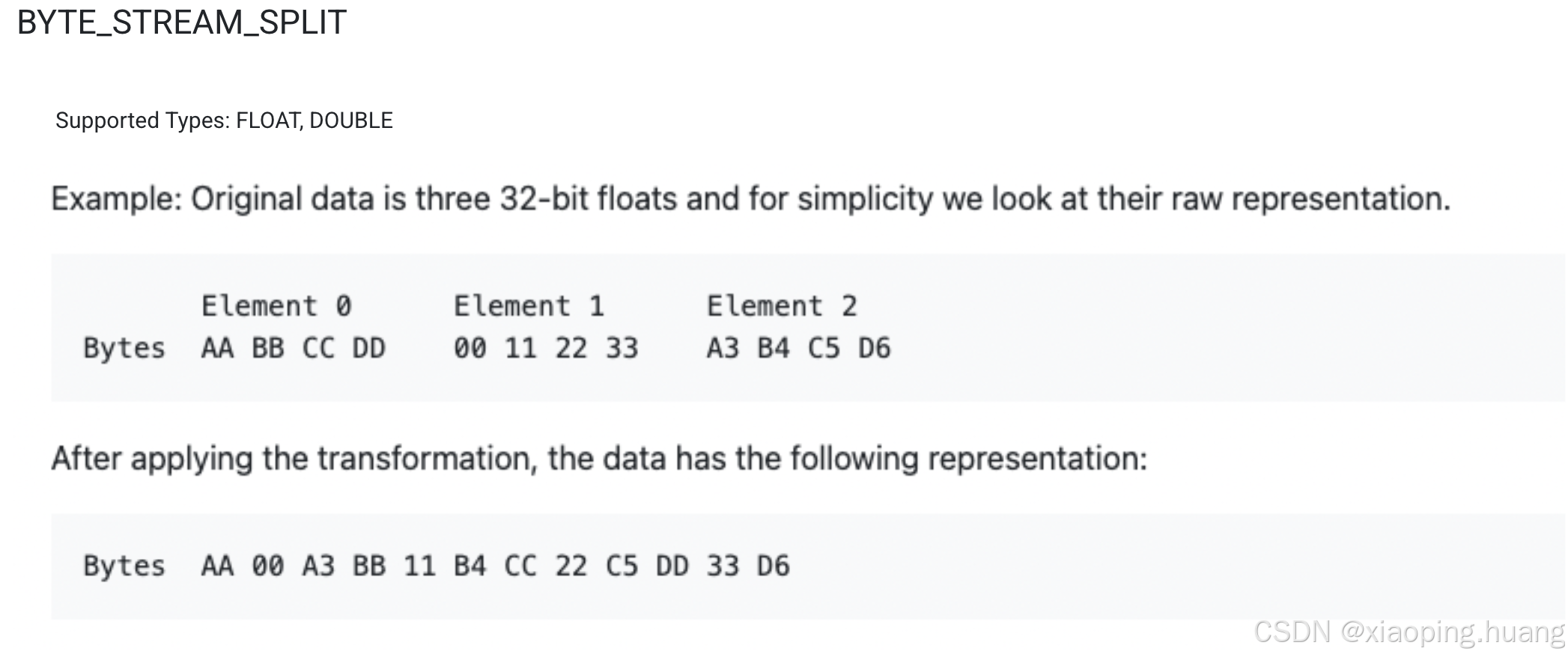
BYTE_STREAM_SPLIT
BYTE_STREAM_SPLIT准确的来说其实不是一种编码,它不能对调整数据的分布,只是在写入的过程做了加速的效果。

















 627
627

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









