







Flink Window 窗口计算
窗口计算是流计算的核心,通过使用窗口对无限的流数据划分成固定大小的 buckets,然后基于落入同一个bucket(窗口)中的元素执行计算。Flink将窗口计算分为两大类:
- 基于keyed stream窗口计算,使用的窗口分配器为window
- 基于non-keyed stream窗口计算,使用的窗口分配器为windowAll
Window Assigners 窗口分配器
Window Assigners定义了如何将元素分配给窗口。在定义完窗口之后,用户可以使用reduce/aggregate/folder/apply等算子实现对窗口的聚合计算。
| 窗口类型 | 说明 |
|---|---|
| Tumbling Windows | 滚动窗口,窗口长度和滑动间隔相等,窗口之间没有重叠 |
| Sliding Windows | 滑动窗口,窗口长度大于滑动间隔,窗口之间存在数据重叠 |
| Session Windows | 会话窗口,窗口没有固定大小,每个元素都会形成一个新窗口,如果窗口的间隔小于指定时间,这些窗口会进行合并 |
| Global Windows | 全局窗口,窗口并不是基于时间划分窗口,因此不存在窗口长度和时间概念。需要用户定制触发策略,窗口才会触发 |
注意,在以上四种窗口中,前三种为TimeWindow,最后一种为GlobalWindow
Window Function 窗口函数
定义Window Assigners后,我们需要指定要在每个窗口上执行的计算。 这是Window Function的职责,一旦系统确定某个窗口已准备好进行处理,该Window Function将用于处理每个窗口的元素。Flink提供了以下Window Function处理函数:
- ReduceFunction
- AggregateFunction
- FoldFunction(已废弃)
- apply/WindowFunction(旧版,一般不推荐)
ProcessWindowFunction
可以获取窗口的中的所有元素,并且拿到一些元数据信息。是WindowFunction的替代方案,因为该接口可以直接操作窗口的State|全局State
案例代码
import java.text.SimpleDateFormat
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.scala.function.ProcessWindowFunction
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.api.windowing.windows.TimeWindow
import org.apache.flink.util.Collector
object FlinkTumblingWindow {
def main(args: Array[String]): Unit = {
val flinkEnv = StreamExecutionEnvironment.getExecutionEnvironment
val dataStream = flinkEnv.socketTextStream("Spark", 6666)
dataStream
.flatMap(_.split("\\s+"))
.map((_, 1))
.keyBy(_._1)
// 滚动窗口
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.reduce((t1:(String, Int),t2:(String, Int)) => (t1._1, t1._2 + t2._2),
new ProcessWindowFunction[(String, Int), (String, Int), String, TimeWindow] {
override def process(key: String, context: Context,
elements: Iterable[(String, Int)],
out: Collector[(String, Int)]): Unit = {
val window = context.window
val sdf = new SimpleDateFormat("HH:mm:ss")
// 打印窗口的开始时间和结束时间
println(sdf.format(window.getStart) + "~" + sdf.format(window.getEnd))
val total = elements.map(_._2).sum
out.collect((key, total))
}
})
.print()
flinkEnv.execute("FlinkTumblingWindow")
}
}
Trigger 触发器
Trigger确定窗口(由Window Assigner形成)何时准备好由Window Function处理。 每个Window Assigner都带有一个默认Trigger。 如果默认Trigger不适合您的需求,则可以自定义触发器。
| 窗口类型 | 触发器 | 触发时机 |
|---|---|---|
| event-time window | EventTimeTrigger | 一旦watermarker没过窗口的末端,该触发器便会触发 |
| processing-time window | ProcessingTimeTrigger | 一旦系统时间没过窗口末端,该触发器便会触发 |
| GlobalWindow | NeverTrigger | 永远不会触发 |
案例代码
import org.apache.flink.streaming.api.functions.windowing.delta.DeltaFunction
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.scala.function.WindowFunction
import org.apache.flink.streaming.api.windowing.assigners.GlobalWindows
import org.apache.flink.streaming.api.windowing.triggers.DeltaTrigger
import org.apache.flink.streaming.api.windowing.windows.GlobalWindow
import org.apache.flink.util.Collector
object FlinkTriggerWindow {
def main(args: Array[String]): Unit = {
val flinkEnv = StreamExecutionEnvironment.getExecutionEnvironment
val dataStream = flinkEnv.socketTextStream("Spark", 6666)
// 差值大于10的时候触发
val deltaTrigger = DeltaTrigger.of[(String, Int), GlobalWindow](10.0, new DeltaFunction[(String, Int)] {
override def getDelta(oldDataPoint: (String, Int), newDataPoint: (String, Int)): Double = {
newDataPoint._2 - oldDataPoint._2
}
}, createTypeInformation[(String, Int)].createSerializer(flinkEnv.getConfig))
// a 100
dataStream
.map(_.split("\\s+"))
.map(arr => (arr(0), arr(1).toInt))
.keyBy(_._1)
.window(GlobalWindows.create())
// 配置触发器
.trigger(deltaTrigger)
.apply(new WindowFunction[(String, Int), (String, Int), String, GlobalWindow] {
override def apply(key: String, window: GlobalWindow,
input: Iterable[(String, Int)],
out: Collector[(String, Int)]): Unit = {
println("key:" + key + "window:" + window)
input.foreach(t => println(t))
}
})
.print()
flinkEnv.execute("FlinkTriggerWindow")
}
}
Evictors 剔除器
Evictors可以在触发器触发后,应用Window Function之前 和/或 之后从窗口中删除元素。 为此,Evictor界面有两种方法
自定义剔除器
import org.apache.flink.streaming.api.windowing.evictors.Evictor;
import org.apache.flink.streaming.api.windowing.windows.Window;
import org.apache.flink.streaming.runtime.operators.windowing.TimestampedValue;
import java.util.Iterator;
public class UserDefineErrorEvictor<w extends Window> implements Evictor<String, w> {
private Boolean isEvictorBefore;
private String content;
public UserDefineErrorEvictor(Boolean isEvictorBefore, String content) {
this.isEvictorBefore = isEvictorBefore;
this.content = content;
}
// 在聚合之前剔除
@Override
public void evictBefore(Iterable<TimestampedValue<String>> elements, int size,
w window, EvictorContext evictorContext) {
if(isEvictorBefore){
evict(elements, size, window, evictorContext);
}
}
// 在聚合之后剔除
@Override
public void evictAfter(Iterable<TimestampedValue<String>> elements, int size,
w window, EvictorContext evictorContext) {
if(!isEvictorBefore){
evict(elements, size, window, evictorContext);
}
}
// 剔除的核心逻辑
private void evict(Iterable<TimestampedValue<String>> elements, int size,
w window, EvictorContext evictorContext){
Iterator<TimestampedValue<String>> iterator = elements.iterator();
while (iterator.hasNext()){
TimestampedValue<String> next = iterator.next();
String value = next.getValue();
// 如果包含指定的字符串,则剔除
if(value.contains(content)){
iterator.remove();
}
}
}
}
使用方法
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.scala.function.AllWindowFunction
import org.apache.flink.streaming.api.windowing.assigners.GlobalWindows
import org.apache.flink.streaming.api.windowing.triggers.CountTrigger
import org.apache.flink.streaming.api.windowing.windows.GlobalWindow
import org.apache.flink.util.Collector
object FlinkEvictor {
def main(args: Array[String]): Unit = {
val flinkEnv = StreamExecutionEnvironment.getExecutionEnvironment
val dataStream = flinkEnv.socketTextStream("Spark", 6666)
dataStream
.windowAll(GlobalWindows.create())
// 记录达到5条触发
.trigger(CountTrigger.of(5))
// 剔除包含error的数据
.evictor(new UserDefineErrorEvictor[GlobalWindow](true, "error"))
.apply(new AllWindowFunction[String, String, GlobalWindow] {
override def apply(window: GlobalWindow, input: Iterable[String], out: Collector[String]): Unit = {
input.foreach(t => out.collect(t))
}
})
.print("窗口输出")
flinkEnv.execute("FlinkEvictor")
}
}
EventTime Window 事件时间的窗口计算
Flink在流式传输程序中支持不同的时间概念。包含:Processing Time(处理时间)/Event Time(事件时间)/Ingestion Time(摄入时间)
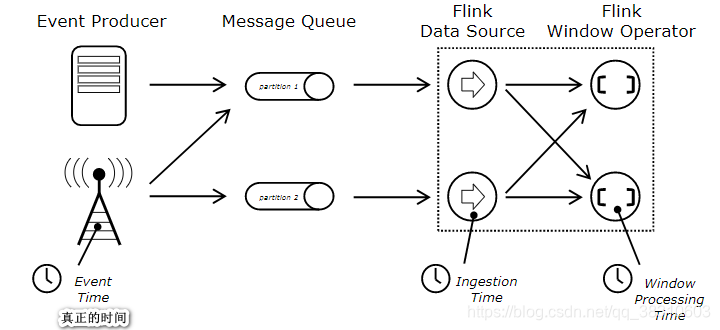
如果用户不指定Flink处理时间属性,默认使用的是ProcessingTime.其中Ingestion和Processing Time都是系统产生的,不同的是Ingestion Time是Source Function产生,而Processing Time由计算节点产生,无需用户指定时间抽取策略。
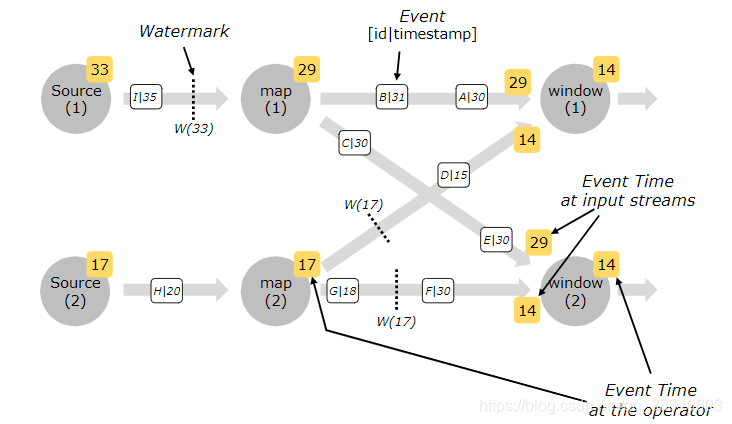
Flink中用于衡量事件时间进度的机制是水位线。 水位线作为数据流的一部分流动,并带有时间戳。 Watermark(t)声明事件时间已在该流中达到时间t,这意味着该流中不应再有时间戳t’<= t的元素。水位线计算方式如下
watermarker(T)= max Event time seen by Process Node(节点所能看到的最大事件时间) - maxOrderness 时间 (最大的乱序时间)
水位线计算策略分为两种
- AssignerWithPeriodicWatermarks: 会定期的计算watermarker的值
- AssignerWithPunctuatedWatermarks:系统每接收一个元素,就会触发水位线的计算
基本案例
import java.text.SimpleDateFormat
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.functions.AssignerWithPeriodicWatermarks
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.scala.function.AllWindowFunction
import org.apache.flink.streaming.api.watermark.Watermark
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.api.windowing.windows.TimeWindow
import org.apache.flink.util.Collector
object FlinkWaterMark {
def main(args: Array[String]): Unit = {
val flinkEnv = StreamExecutionEnvironment.getExecutionEnvironment
// 设置并行度为1,方便测试
flinkEnv.setParallelism(1)
// 设置时间特性为事件时间
flinkEnv.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
// 设置水位线计算频率为每秒一次
flinkEnv.getConfig.setAutoWatermarkInterval(1000)
val dataStream = flinkEnv.socketTextStream("Spark", 6666)
val lateTag = new OutputTag[(String, Long)]("late")
// 数据格式 a 时间戳 (2019-11-20 20:36:00 1574253360000)
val stream = dataStream
.map(_.split("\\s+"))
.map(arr => (arr(0), arr(1).toLong))
// 使用定制的水位线计算规则
.assignTimestampsAndWatermarks(new UserDefineAssignTimestampsAndWatermark)
// 滚动窗口,窗口大小为5秒
.windowAll(TumblingEventTimeWindows.of(Time.seconds(5)))
// 允许迟到,可以迟到的时间为2秒
.allowedLateness(Time.seconds(2))
// 将迟到太多的数据作为边输出
.sideOutputLateData(lateTag)
.apply(new AllWindowFunction[(String, Long), String, TimeWindow] {
val sdf = new SimpleDateFormat("HH:mm:ss")
override def apply(window: TimeWindow, input: Iterable[(String, Long)],
out: Collector[String]): Unit = {
println(sdf.format(window.getStart) + "~" + sdf.format(window.getEnd))
out.collect(input.map(t => t._1 + "->" + sdf.format(t._2))
.reduce((v1, v2) => v1 + "|" + v2))
}
})
stream.print("纳入窗口计算的数据")
stream.getSideOutput(lateTag).printToErr("迟到太晚被丢弃的数据")
flinkEnv.execute("FlinkWaterMark")
}
}
class UserDefineAssignTimestampsAndWatermark extends AssignerWithPeriodicWatermarks[(String, Long)]{
// 设置乱序时间为2秒
var maxOrdernessTime = 2000L
var maxSeenTime = 0L
// 获取水位线
override def getCurrentWatermark: Watermark = {
new Watermark(maxSeenTime - maxOrdernessTime)
}
// 抽取时间戳
override def extractTimestamp(element: (String, Long), previousElementTimestamp: Long): Long = {
maxSeenTime = Math.max(element._2, previousElementTimestamp)
element._2
}
}
Watermarks in Parallel Streams 在并行流中的水位线
watermarker 在Source Function 之后直接生成。 Source Function 的每个并行子任务通常独立生成其watermarker 。随着watermarker 在流程序中的流动,它们会增加计算节点的EventTime。 每当Operator更新了事件时间,该事件事件都会为其后Operator在下游生成新的watermarker。当下游操作符接收到多个watermarker的值得时候,系统会选择最小的watermarker。
join 流的连接
在Flink中流的join分为两种 Window Join 和 Interval Join
Window Join
Window Join要求两个数据流必须在同一个窗口下才可以进行连接。 使用格式如下:
stream.join(otherStream) //指定连接的流
.where() // 判断条件
.equalTo() // 连接条件
.window() // 指定窗口
.apply() // 具体操作
| 方式 | 说明 |
|---|---|
| Tumbling Window Join | 两个数据流在滚动窗口中进行join |
| Sliding Window Join | 两个数据流在滑动窗口中进行join |
| Session Window Join | 两个数据流在会话窗口中进行join |
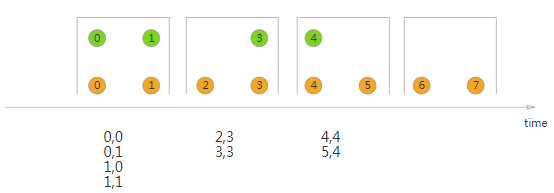
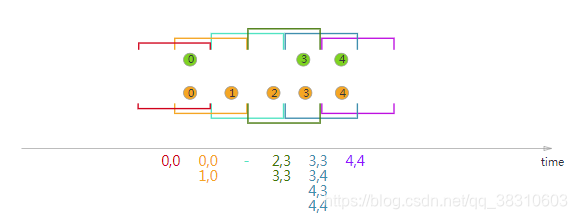
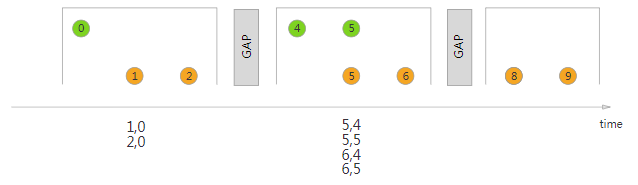
Interval Join
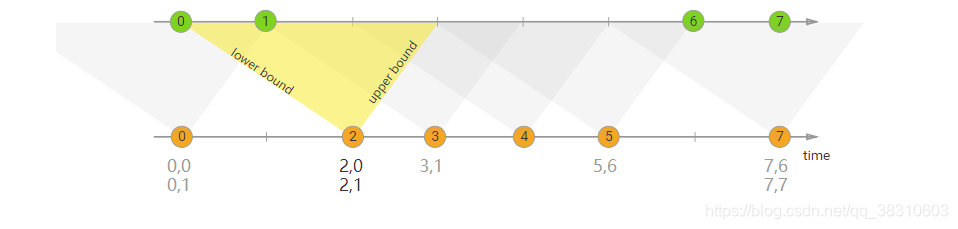
Interval Join与窗口无关,只关心要连接的数据流的数据是否处于该数据流的数据所规定的上下界的时间范围内(包含上下界),如果满足条件,则可以进行连接,如图所示:
案例代码
val fsEnv = StreamExecutionEnvironment.getExecutionEnvironment
fsEnv.setParallelism(1)
//设置时间特性
fsEnv.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
//设置水位线计算频率 1s
fsEnv.getConfig.setAutoWatermarkInterval(1000)
// 001 zhangsan 时间戳
val userkeyedStrem: KeyedStream[(String,String,Long),String] = fsEnv.socketTextStream("Spark",9999)
.map(_.split("\\s+"))
.map(ts=>(ts(0),ts(1),ts(2).toLong))
.assignTimestampsAndWatermarks(new UserAssignerWithPunctuatedWatermarks)
.keyBy(t=>t._1)
// 001 100.0 时间戳
val orderStream: KeyedStream[(String,Double,Long),String] = fsEnv.socketTextStream("Spark",8888)
.map(_.split("\\s+"))
.map(ts=>(ts(0),ts(1).toDouble,ts(2).toLong))
.assignTimestampsAndWatermarks(new OrderAssignerWithPunctuatedWatermarks)
.keyBy(t=>t._1)
userkeyedStrem.intervalJoin(orderStream)
// 定义上下界时间范围
.between(Time.seconds(-2),Time.seconds(2))
.process(new ProcessJoinFunction[(String,String,Long),(String,Double,Long),String] {
override def processElement(left: (String, String, Long),
right: (String, Double, Long),
ctx: ProcessJoinFunction[(String, String, Long), (String, Double, Long), String]#Context,
out: Collector[String]): Unit = {
// 连接流的时间
val leftTimestamp = ctx.getLeftTimestamp
// 要连接的流的时间
val rightTimestamp = ctx.getRightTimestamp
// 以上两个时间中较大的时间
val timestamp = ctx.getTimestamp
println(s"left:${leftTimestamp},right:${rightTimestamp},timestamp:${timestamp}")
out.collect(left._1+"\t"+left._2+"\t"+right._2)
}
})
.print()
fsEnv.execute("FlinkWordCountsQuickStart")

















 270
270

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









