







 本文介绍深度学习在文本分类任务中的应用,包括Word2Vec、fastText、textCNN、DPCNN、textRNN、HAN、Transformer和BERT等模型原理。深入探讨了词向量、卷积神经网络、循环神经网络、注意力机制和预训练模型在处理文本数据方面的优势。
本文介绍深度学习在文本分类任务中的应用,包括Word2Vec、fastText、textCNN、DPCNN、textRNN、HAN、Transformer和BERT等模型原理。深入探讨了词向量、卷积神经网络、循环神经网络、注意力机制和预训练模型在处理文本数据方面的优势。
文章目录
Word2Vec 原理
(无监督训练)
Word2vec 使用的词向量不是我们上述提到的One-hot Representation那种词向量,而是 Distributed representation 的词向量表示方式。其基本思想是 通过训练将每个词映射成 K 维实数向量(K 一般为模型中的超参数),通过词之间的距离(比如 cosine 相似度、欧氏距离等)来判断它们之间的语义相似度。
Continuous Bag of Words(CBOW)模型:用上下文预测目标词
基于上下文单词(周围单词)预测当前目标单词(中心单词)。
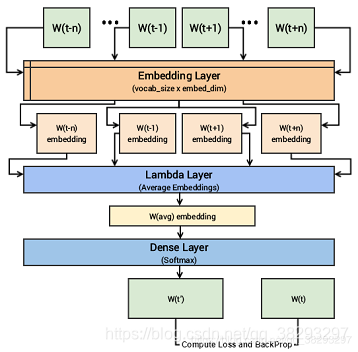
实现步骤:
- 构建语料库词汇表:vocab
- 建立一个CBOW(上下文,目标)生成器:generate_context_word_pairs(构建目标中心词 (长度为
1)和及其上下文词(长度为window_size*2[2指的是上、下文])组成的词对) - 构建CBOW模型架构:输入上下文单词,送入随机初始化的嵌入层,再到
λ层,做词嵌入的平均 ,把平均后的向量送到一个dense的softmax层去预测目标词。损失函数:categorical_crossentropy,并对每个epoch执行反向传播来更新嵌入层。 - 训练模型
- 获取Word Embeddings
Skip-gram 模型:用目标词预测上下文
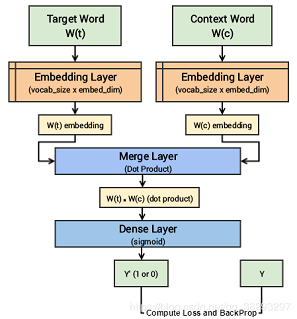
实现步骤:
- 构建语料库词汇表
- 构建skip-gram
[(target, context), relevancy]生成器:负样本relevancy=0,context是词汇表中的random word。 - 构建skip-gram模型结构:输入是 目标单词和上下文或随机单词对。送入随机初始化的嵌入层,得到词向量,将其送入一个合并层,计算两个向量的点积;再将点积值传递给一个dense的sigmoid层,该层根据这对单词是上下文相关的还是随机的单词来预测是1还是0。我们将其与实际的关联标签(Y)匹配,通过
mean_squared_error计算损失,并对每个epoch反向传播来更新嵌入层。 - 训练模型
- 得到词嵌入
fastText 模型
- 与CBOW类似,CBOW 通过上下文预测中间词[Unsupervised],而fastText则是通过上下文预测类别标签[Supervised]。
- 另外,CBOW 输入的是除中心词以外的窗口词的Embeddings,而FastText输入整个句子全部词的Embeddings。
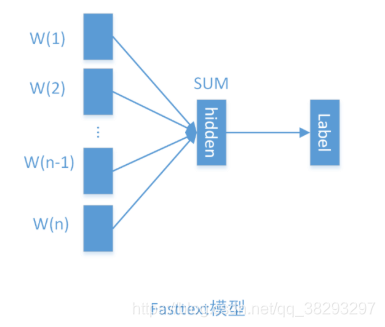
- FastTtext 本质上是一个浅层NN,前向传播过程如下:
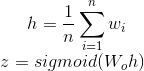
- 要预测文章属于某个类别的概率,使用softmax函数激活很合适,loss 采用CE loss
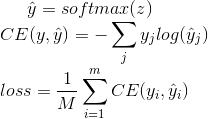
- 当类别数很多时,softmax层的计算就比较费时。
fastText 优化:层次softmax
回顾一下 Softmax 实际上是一个归一化函数,如下所示,其实
i
i
i 指的是数组
V
V
V 中的一个元素:
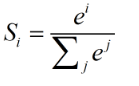
但是当类别数很大的时候,这个计算过程非常耗时。使用层次softmax可以将复杂度从
N
N
N 降到
l
o
g
N
logN
logN
不多说了,详见我的博客:2.文本分类——fastText模型
…………
textCNN 模型
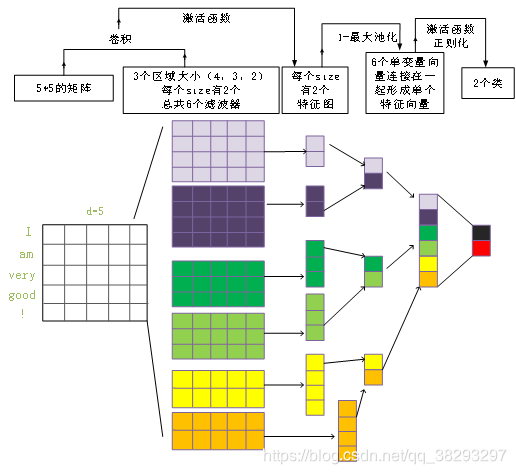
- 嵌入层:word2vec 训练好的词向量。
- 卷积层:卷积核宽度和Embedding size 是一致的;
- 池化层:最大池化
- 全连接层:连接至类别……
- softmax层:将全连接层的输出使用softmax函数,获取文本分到不同类别的概率。
DPCNN 模型
Deep Pyramid Convolutional Neural Networks for Text Categorization(DPCNN)
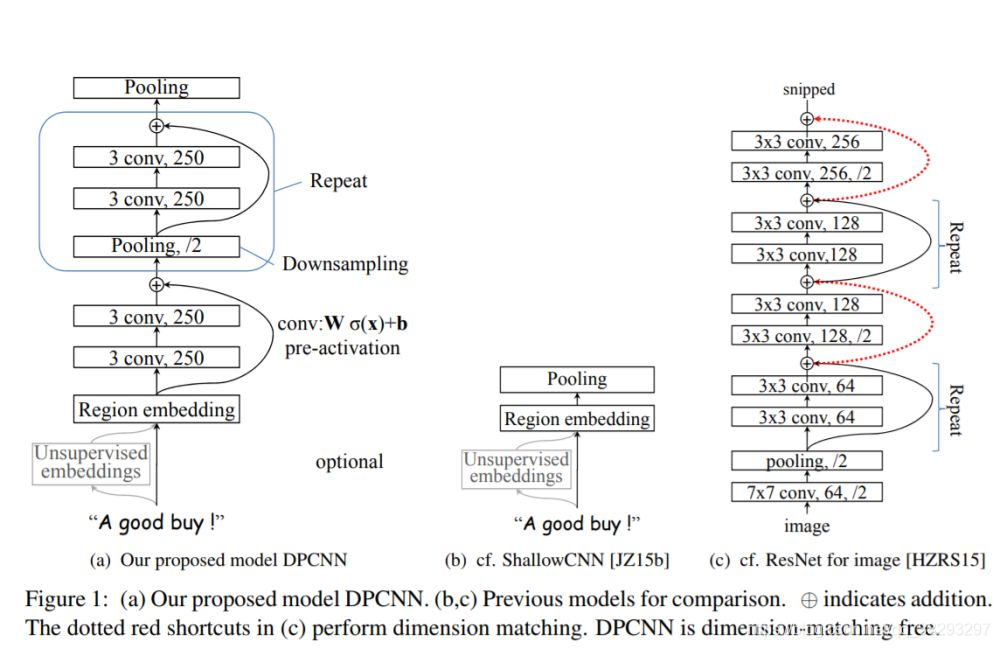
(1)Region Embedding
将TextCNN的包含多尺寸卷积滤波器的卷积层的卷积结果称之为Region embedding;
意思就是对一个文本区域/片段(比如3gram)进行一组卷积操作后生成的embedding。
(2)等长卷积
首先,选择了适当的两层等长卷积来提高词位 embedding 的表示的丰富性。
输入输出序列的位置数一样多,我们将输入输出序列的第 n 个embedding称为第 n 个词位,那么这时size为 n 的卷积核产生的等长卷积的意义就很明显了,那就是将输入序列的每个词位及其左右((n-1)/2)个词的上下文信息压缩为该词位的embedding,也就是说,产生了每个词位的被上下文信息修饰过的更高level更加准确的语义。
(3)固定Feature Map的数量
在DPCNN中固定死了feature map的数量,也就是固定住了embedding space的维度
(4)1/2池化层
每经过一个size=3, stride=2(大小为3,步长为2)的池化层(以下简称1/2池化层),序列的长度就被压缩成了原来的一半(请自行脑补)。这样同样是size=3的卷积核,每经过一个1/2池化层后,其能感知到的文本片段就比之前长了一倍。
重复部分是:等长卷积 + 等长卷积 + 使用一个 size=3 和 stride=2 进行 maxpooling 进行池化
(5)残差连接
由于深度网络中仿射矩阵(每两层间的连接边)近似连乘,训练过程中网络也非常容易发生梯度爆炸或弥散问题;
既然每个block的输入在初始阶段容易是0而无法激活,那么直接用一条线把region embedding层连接(将其直接与当前block的输入做加和)到每个block的输入乃至最终的池化层/输出层不就可以啦!
为了匹配输入维度,要事先经过对应次数的1/2池化操作;

textRNN 模型
-
naiveRNN
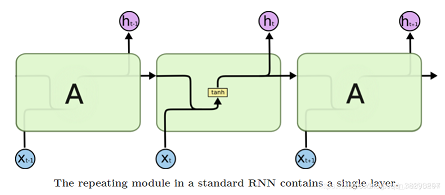

随着时间步骤长度的增大,它无法从差得很远的时间步骤中获得上下文环境。 -
LSTM
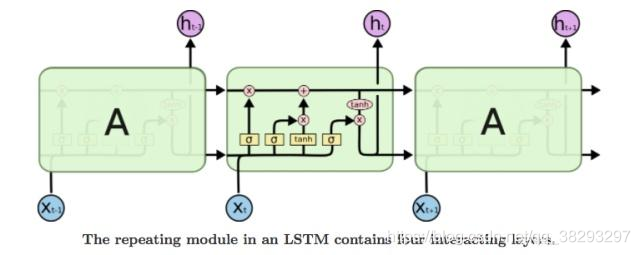
这就要涉及到 LSTM 中的门控了。门是一种可选择通过信息的节点。 它们由 σ \sigma σ,即 S i g m o i d Sigmoid Sigmoid 神经网络层和逐点乘法运算组成。 S i g m o i d Sigmoid Sigmoid 层输出 0 到 1 之间的数字,描述每个信息向量应该通过多少。
下面是三个门:
(1) 遗忘门:将细胞状态中的信息选择性的遗忘
(2) 输入门:将新的信息选择性的记录到细胞状态中
(3) 输出门 -
GRU

从结构上来说,GRU只有两个门(update和reset),LSTM有三个门(forget,input,output)
它将遗忘门和输入门合成了一个单一的 更新门。同样还混合了细胞状态和隐藏状态,和其他一些改动。
更新门:用于控制前一时刻的状态信息被带入到当前状态中的程度,更新门的值越大说明前一时刻的状态信息带入越多。
重置门:用于控制忽略前一时刻的状态信息的程度,重置门的值越小说明忽略得越多。
GRU 参数更少因此更容易收敛; -
双向LSTM
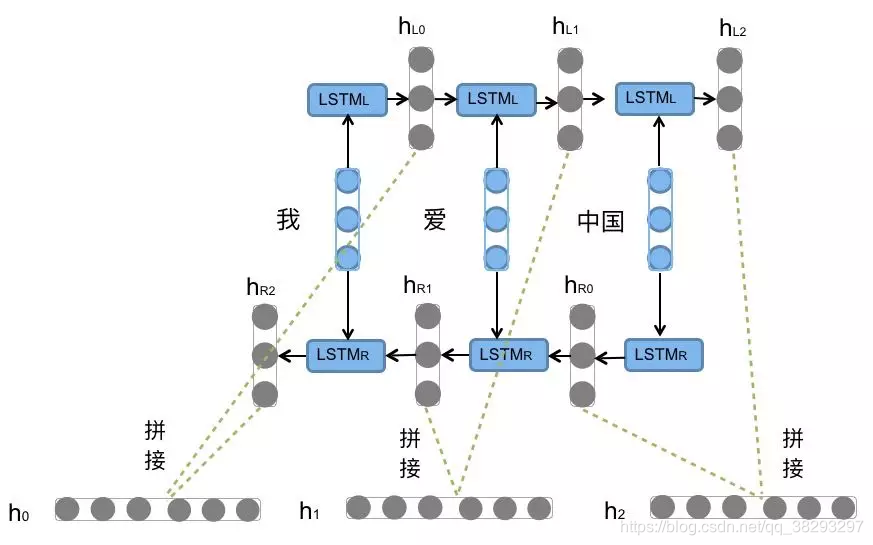

textRNN模型结构1
1.embeddding layer 2.Bi-LSTM layer 3.concat output 4.FC layer 5.softmax
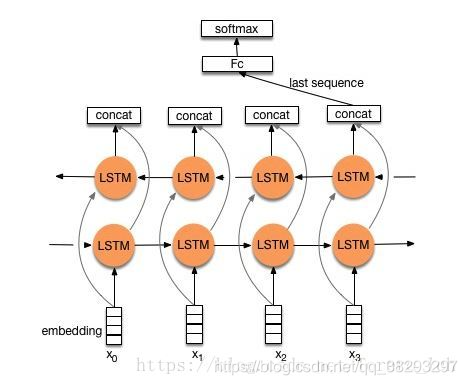
一般取前向/反向LSTM在最后一个时间步长上隐藏状态,然后进行拼接,在经过一个softmax层(输出层使用softmax激活函数)进行一个多分类;或者取前向/反向LSTM在每一个时间步长上的隐藏状态,对每一个时间步长上的两个隐藏状态进行拼接,然后对所有时间步长上拼接后的隐藏状态取均值,再经过一个softmax层(输出层使用softmax激活函数)进行一个多分类(2分类的话使用sigmoid激活函数)。
上述结构也可以添加dropout/L2正则化或BatchNormalization 来防止过拟合以及加速模型训练。
textRNN模型结构2
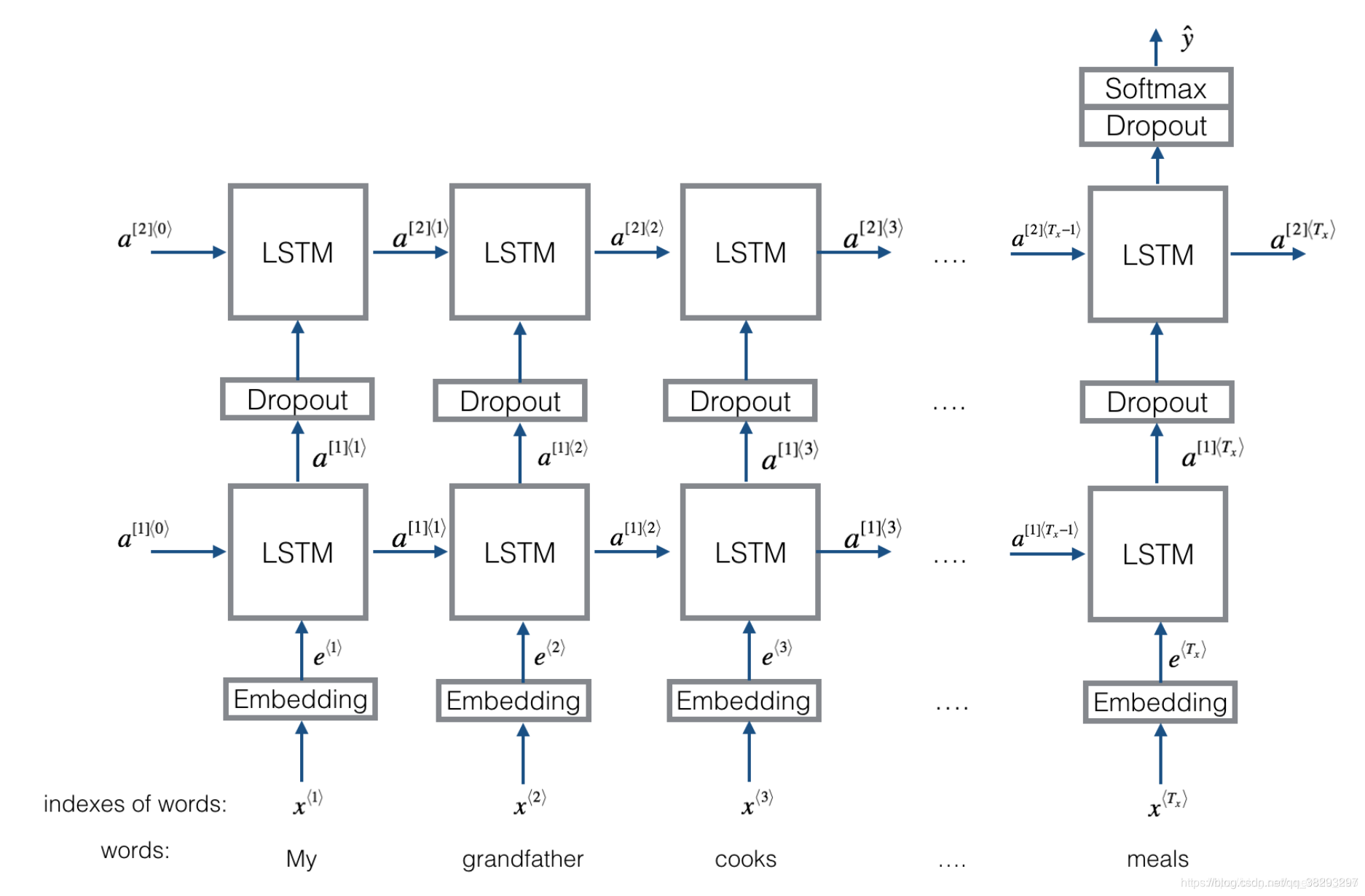
与之前结构不同的是,在双向LSTM(上图不太准确,底层应该是一个双向LSTM)的基础上又堆叠了一个单向的LSTM。把双向LSTM在每一个时间步长上的两个隐藏状态进行拼接,作为上层单向LSTM每一个时间步长上的一个输入,最后取上层单向LSTM最后一个时间步长上的隐藏状态,再经过一个softmax层(输出层使用softamx激活函数,2分类的话则使用sigmoid)进行一个多分类。
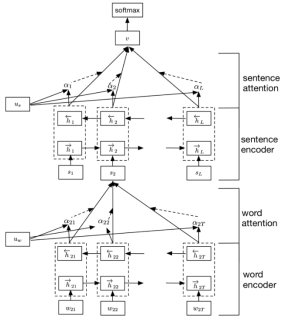
HAN:Hierarchical Attention Network
Bi-GRU+Attention


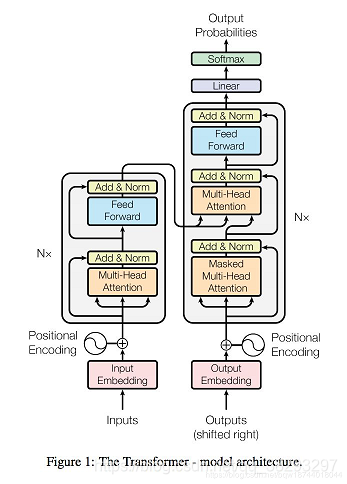
Transformer
(1). Transformer文本分类
-
embedding layer(嵌入层):获得词的分布式表示
-
positional encoding(位置编码):将位置信息加入到embedding中。
-
Scaled dot-product attention(缩放的点乘注意力机制):
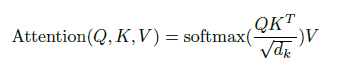
-
Multi-head attention(多头注意力)

-
Position-wise Feed-Forward network

BERT
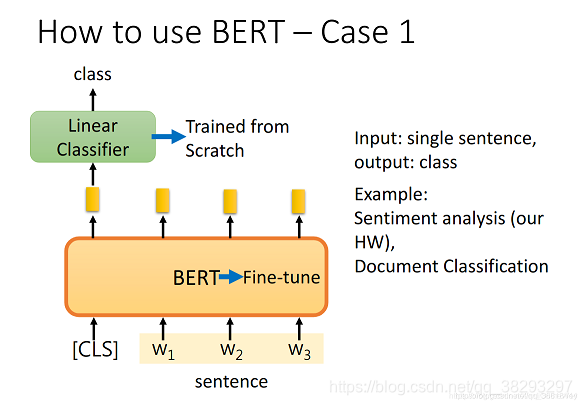
基于医疗知识图谱的问答系统
https://blog.youkuaiyun.com/vivian_ll/article/details/89840281
构建知识图谱:
- 首先,爬取寻医问药网的数据,存储成 json格式;
- 逐行读取json,将内容存储到:手动建立的实体、关系列表中;得到实体和关系
- 构建知识图谱:
- 使用已有实体列表创建 “结点”(
g.create()),有两类结点,①中心疾病[带属性]、②普通结点; - 关系列表创建 “边”(
g.run( match语句 ));
- 使用已有实体列表创建 “结点”(
问答模块—— 完全基于规则匹配实现,通过关键词匹配,对问句进行分类,医疗问题本身属于封闭域类场景,对领域问题进行穷举并分类,然后使用cypher的match去匹配查找neo4j,根据返回数据组装问句回答,最后返回结果。
问句分类:
- 输入问句,通过ahocorasick库的iter()函数匹配领域词,其中领域词是由 7类实体+1类否定词 组成;接着,去除重复的短的领域词;最后返回的是 {问句中的领域词:词所对应的实体类型} 。
- 手工构造问句疑问词,比如
症状疑问词,可以有:['症状', '表征', '现象', '症候', '表现', '会引起'] - 手工构造规则,匹配问句类型:比如:如果问句中包含症状疑问词 并且 领域词实体类型包含disease,则问句分类到
disease_symptom中;此处问句类型也是穷举的。特别的几个小点:食物相关的问题需要检查否定词self.deny_words来判断是do_eat还是not_eat。
问句解析:
- 上面的问句分类结果,如:
{'args': {'头痛': ['disease', 'symptom']}, 'question_types': ['disease_cureprob']},获取问句中领域词及其实体类型,以及问句类型; - 将每个问句类型依次转为neo4j的Cypher语言,最后组合转换后的sql查询语句。
举个例子:如果问句类型为:disease_symptom,则:sql = ["MATCH (m:Disease)-[r:has_symptom]->(n:Symptom) where m.name = '{0}' return m.name, r.name, n.name".format(i) for i in entities]
查询结果:
- 传入问题解析的结果sqls,将保存在queries里的
[‘question_type’]和[‘sql’]分别取出。 - 首先调用
self.g.run(query).data()函数执行[‘sql’]中的查询语句得到查询结果, - 再根据
[‘question_type’]的不同调用 answer_prettify 函数将查询结果和答案话术结合起来。最后返回最终的答案。
中文命名实体识别:bi-LSTM+CRF
大总结
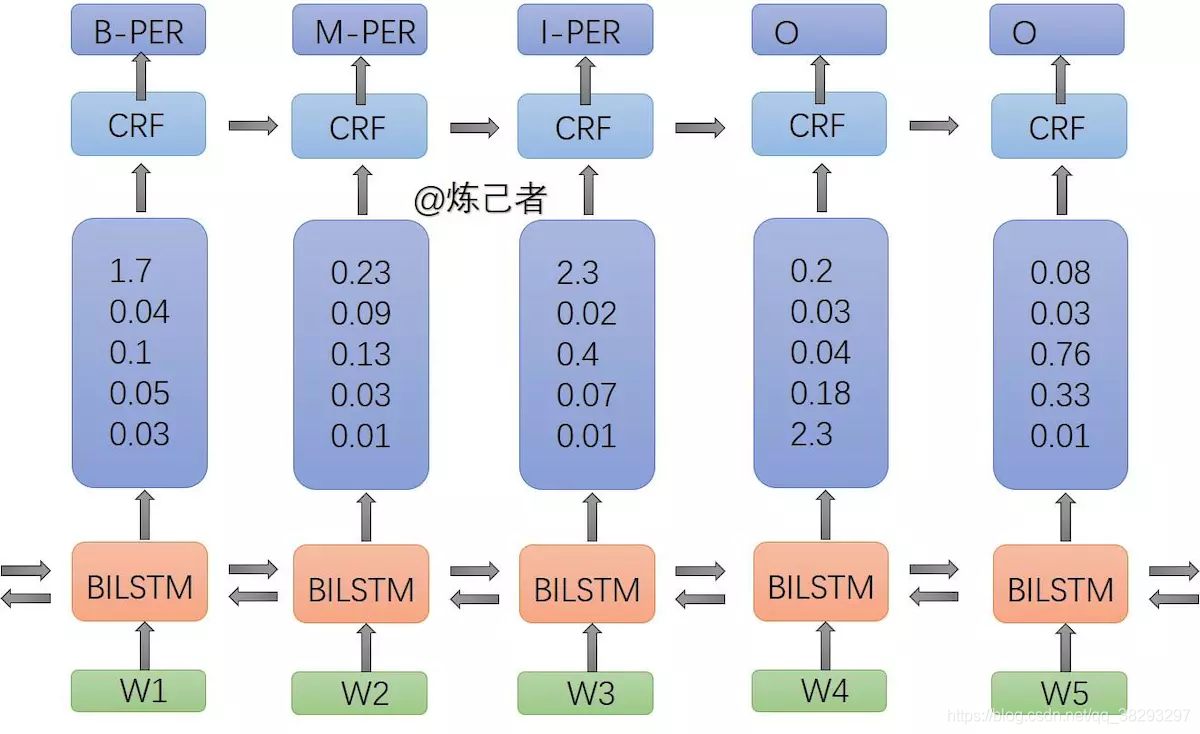
-
数据处理
(1)标注转换:语料为标准的BIO标注方式:开始(begin)、延续(inside),或是非语义槽(outside);;将其 转为:BIOE(B,即Begin,表示开始;I,即Intermediate,表示中间;E,即End,表示结尾;O,即Other,表示其他,用于标记无关字符)
因为有论文证明了BIOES标注方式的模型效果要比BIO好。(2)数据准备:
数据准备成:[[汉字序列],[汉字对应的id序列],[标记对应的id序列],[分词特征]] 举例来说: [['海','钓','比','赛','地','点','在','厦','门',……], [226,1565,144,143,29,227,9,1491,229,……], [1,3,1,3,1,3,0,1,3,……], [1,2,2,3,0,0,0,2,3,……]]分词特征指的是:对句子进行分词后,提取的词长度特征,作为字向量特征的补充;(提供更丰富的文本信息)
对句子分词,构造词的长度特征,为BIES格式,[对]对应的特征为[0], [句子]对应的特征为[1,3], [中华人民]对应的特征为[1,2,2,3]每个字的长度特征为 0 ∼ 3 0 \sim 3 0∼3 的一个id,后面我们把这个id处理为 20 维 20维 20维 的向量,和100维的字向量进行拼接,得到120维的向量。
(3)batch 分桶:把所有样本先按长度排序,生成batch的时候,长度相近的样本在一个batch内,batch内部按最长的样本长度进行zero pad。而batch之间的长度不同,最大程度减少了zero pad 的数量,从而加快训练速度。
(3)bi-LSTM层 和 Linear层 :使用维基语料预训练的字Embedding,将句子中的字序列映射为字向量,连接上额外的分词特征(上述的120维)作为bi-LSTM的输入,输出是前后向LSTM的输出的拼接;接着把LSTM的输出送入Linear层,得到发射矩阵,也就是观测序列(句子)到标签序列(实体标签)的发射矩阵;
(4)输出:挂了一层条件随机场模型作为模型的解码层,在条件随机场模型里面考虑预测结果之间的合理性。
!!! !!! !!! !!! !!! !!! !!! !!! !!! !!! !!! !!! !!! !!! !!! !!! !!! !!! !!! !!! !!! !!! !!! !!! !!! !!! !!! !!! !!!
后面是详细的说明文件
模型说明
-
这个模型是 带有CRF层的bi-LSTM神经网络。句子中的字序列被映射为字向量,连接上额外的特征作为bi-LSTM的输入,输出是前后向LSTM的输出的拼接,然后被映射为每个标签的得分。最后, 挂了一层条件随机场模型作为模型的解码层,在条件随机场模型里面考虑预测结果之间的合理性。
-
如果将lstm接全连接层的结果作为发射概率,CRF的作用就是通过统计label直接的转移概率对结果lstm的结果加以限制;比如I这个标签后面不能接O,B后面不能接B,如果没有CRF,光靠lstm就做不到这点,最后的score的计算就将发射概率和转移概率相加就ok了。
-
在LSTM+CRF模型下,输出的将不再是相互独立的标签,而是最佳的标签序列 。
项目实现过程
- 数据处理
-
读取数据集:数据集共三个文件,训练集,开发集和测试集,文件中每一行包含两个元素,字和标识。每一句话间由一个空格隔开。例如:
北 B-ORG 京 I-ORG 大 I-ORG 学 I-ORG 迎 O 来 O -
处理数据集 :
(1). 更新数据集中的标签,如: 单独的
B-LOC → S-LOC,B-LOC,I-LOC→B-LOC,E-LOC,B-LOC,I-LOC,I-LOC→B-LOC, I-LOC, E-LOC(2). 创建包含所有字的字典
dict,给每个char和tag分配一个id,从而得到char_to_id,id_to_char,tag_to_id,id_to_tag, 将其存在map.pkl中 -
准备训练集 :
特征提取:将训练集中的每句话变成4个list
- 第一个list是字,如[今,天,去,北,京]
- 第二个list是char_to_id [3,5,6,8,9]
- 第三个list是通过jieba分词得到的分词信息特征,如[1,3,0,1,3] (1,词的开始,2,词的中间,3,词的结尾,0,单个词)
- 第四个list是target,如0,0,0,2,3
-
batch 分桶:
BatchManager 将训练集划分成若干个batch,每个batch有20个句子,划分时,把所有样本先按长度排序,生成batch的时候,长度相近的样本在一个batch内,batch内部按最长的样本长度进行zero pad。
- 模型处理
-
配置model的参数 :
见文件
config.yaml -
构建模型 :
-
embedding layer: 预先训练好了100维wiki词向量模型,通过查询将得到每个字的100维向量,加上分词特征向量,组成120维向量
-
bi-lstm layer: 上述120维向量作为bi-LSTM的输入,输出是前后向LSTM的输出的拼接
-
project layer:即神经网络最后一层的输出,包含两层的Wx+b,是特征提取并全连接后的输出;
-
loss layer:内嵌了CRF;使用bi-LSTM处理之后输出转换为要求的形状作为CRF层的输入;对输出序列加以约束,得到更准确的预测。
-

















 2810
2810

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









