









根据之前两篇博客:mmpose系列(三):中的hrnet_w48+deeppose的方法
和mmpose系列 (一):hrnet 基于mmpose 训练body+foot 23点关键点。方法结合 生成
数据集为coco数据集
hrnet_w48_deeppose_body23.py文件,再6块3090上训练得到模型后计算mAP值的对比,后续公布结果,代码前面都有,动动小手就行了,我懒得copy了,后续上结果。
经过几天的训练,来填坑了,我发现hrnet_regression_base的方法训练了110个迭代(服务器挂了)没法训练120个epoce,但是也差不多了来看下对比把,这里截取是body17个关键点的
hrnet_heatmap:
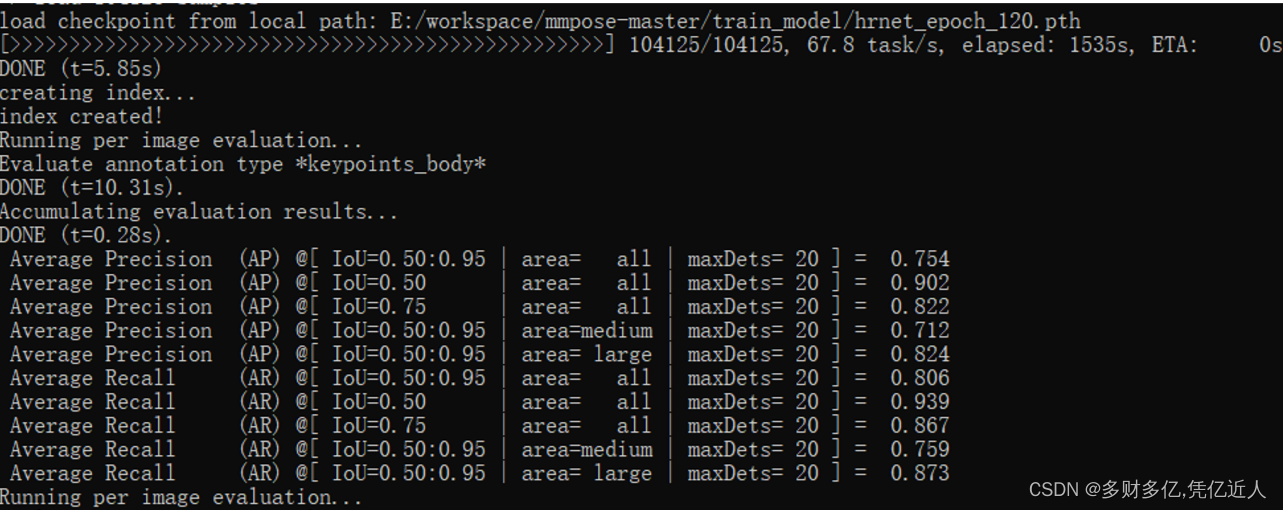
hrnet_regression_base:
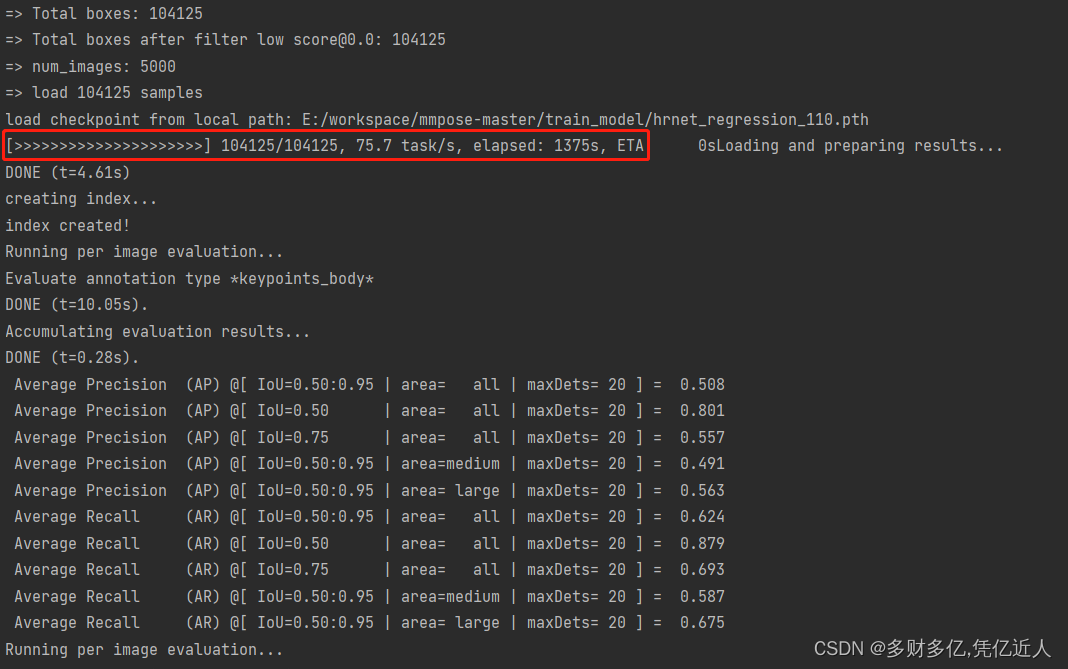
差距有点大,不知道是不是因为regression收敛慢,还没有训练到好的点的地方
训练的hrnet_regression+RLE: 之前时间原因只训练了10个epoch,但是效果和镜子大佬说的一样 已经达到了人家不加rle的100个迭代的效果,上图。
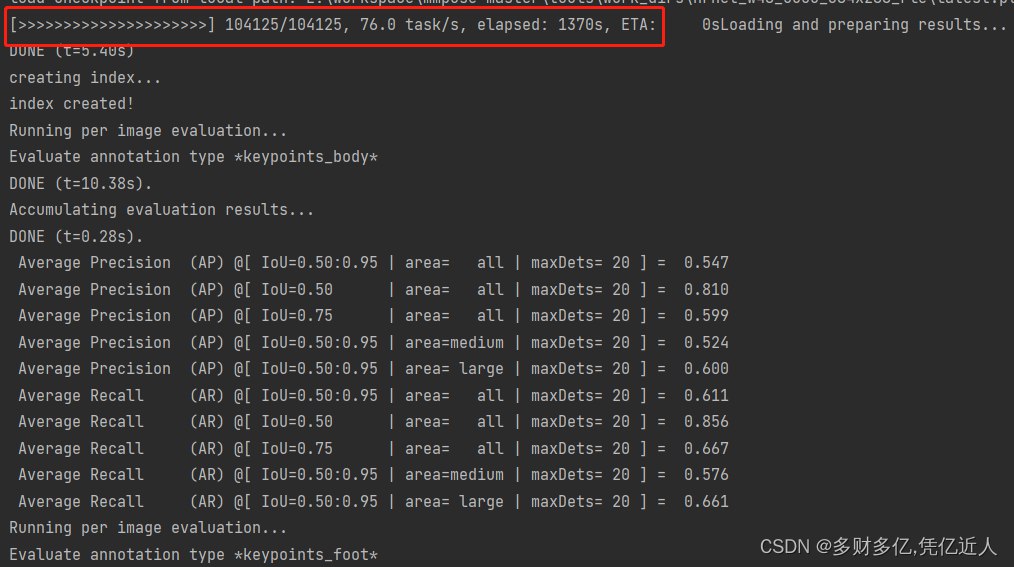
目前时间空出来了,正在训练这个模型。
先放下 shufflenetV2_regression+RLE的200个epoch 效果:
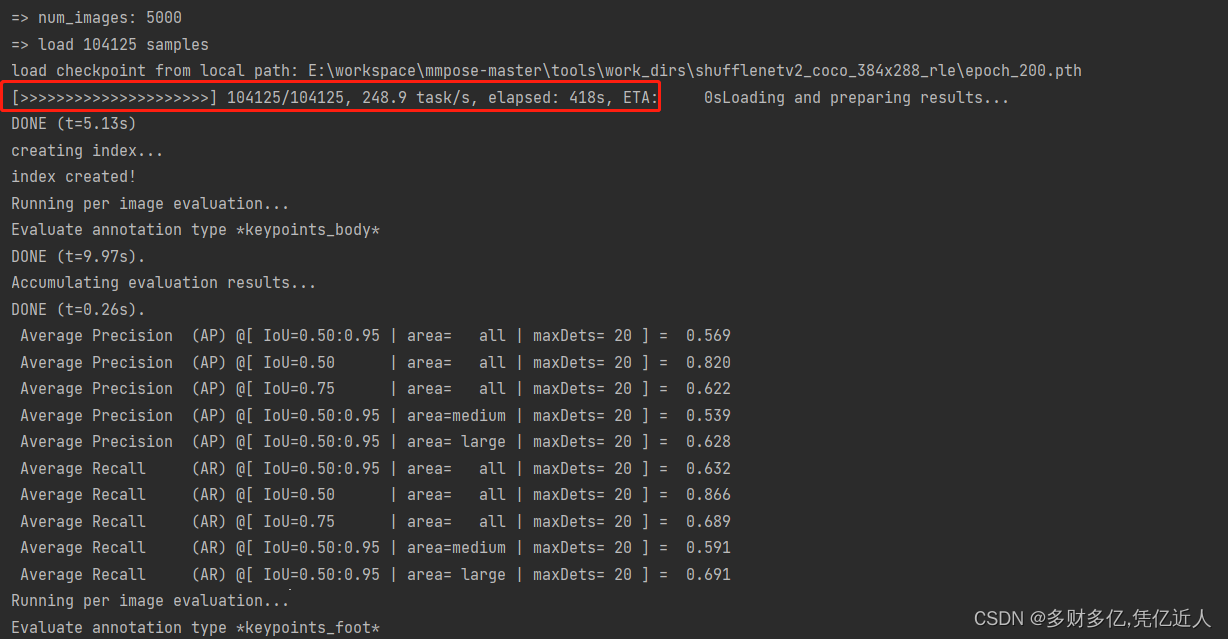
我虽然在coco 数据集上训练的,但是看着镜子大佬训练出来的数据,感觉我没达到他的效果。

















 3492
3492

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









