









 本文探讨了在DenseNet模型中应用dropout、调整学习率、数据集增强等方法对模型性能的影响。通过实验,作者发现dropout比例、样本不平衡和学习率设置对模型的准确率和损失有显著作用。使用Focal Loss解决了类别不平衡问题,验证集准确率提升至98.2%。此外,针对难例样本的处理也对模型稳定性和准确性起到了关键作用。
本文探讨了在DenseNet模型中应用dropout、调整学习率、数据集增强等方法对模型性能的影响。通过实验,作者发现dropout比例、样本不平衡和学习率设置对模型的准确率和损失有显著作用。使用Focal Loss解决了类别不平衡问题,验证集准确率提升至98.2%。此外,针对难例样本的处理也对模型稳定性和准确性起到了关键作用。
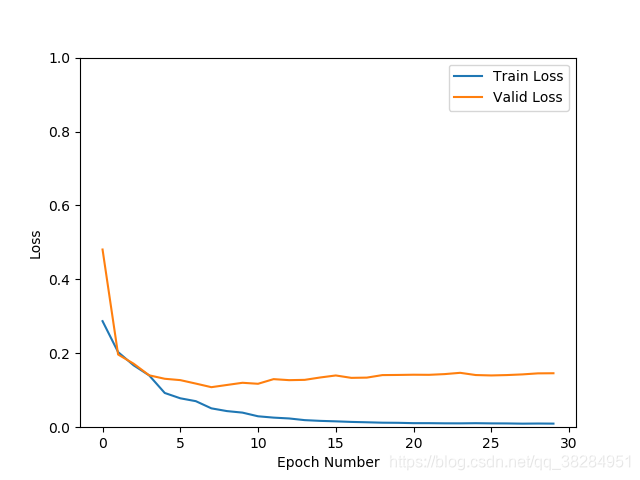
densenet 加入drop out p=0.4
sgd优化器 验证集准确率96.2% 损失0.16
optimizer = torch.optim.SGD(classify_model.parameters(), lr=params["lr"], momentum=0.9, weight_decay=1e-5)
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='min', factor=0.7, patience=2)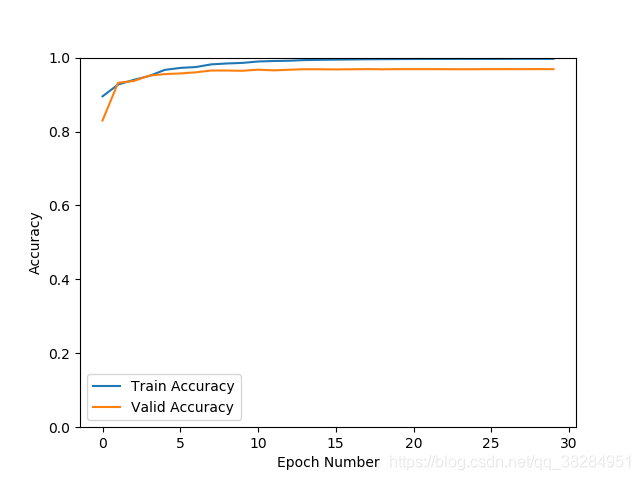
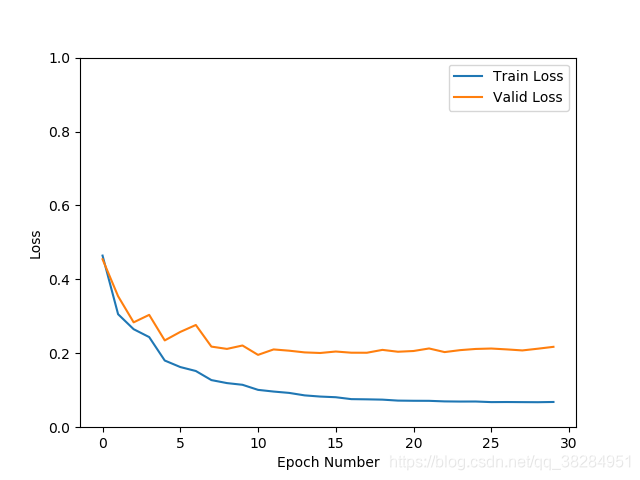
densenst 直接在网络中加入drop_rate = 0.4,batchsize = 32
SGD优化 验证集准确率94.8% 损失0.22
optimizer = torch.optim.SGD(classify_model.parameters(), lr=params["lr"], momentum=0.9, weight_decay=1e-5)
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='min', factor=0.5, patience=2)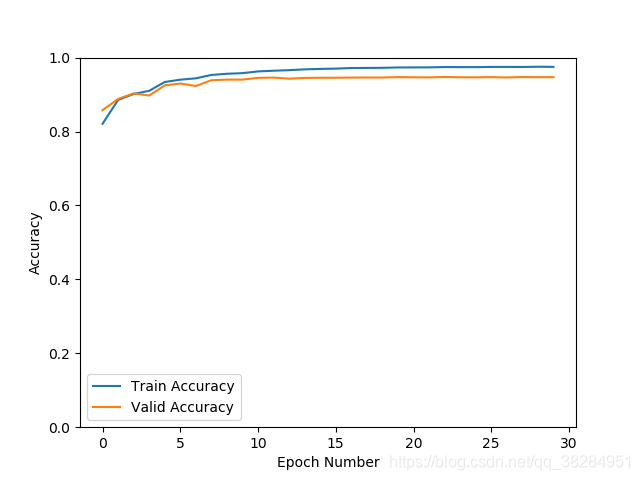
添加数据集,相同类别不同特征
drop_rate = 0.2 batchsize=64
sgd优化器同上 验证集准确率96.9% 损失0.14
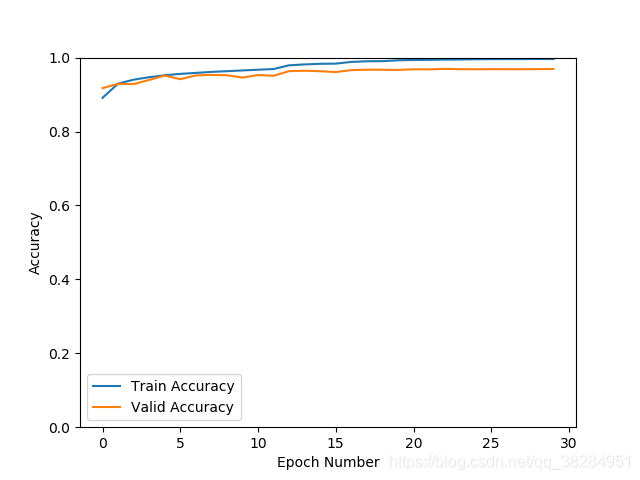
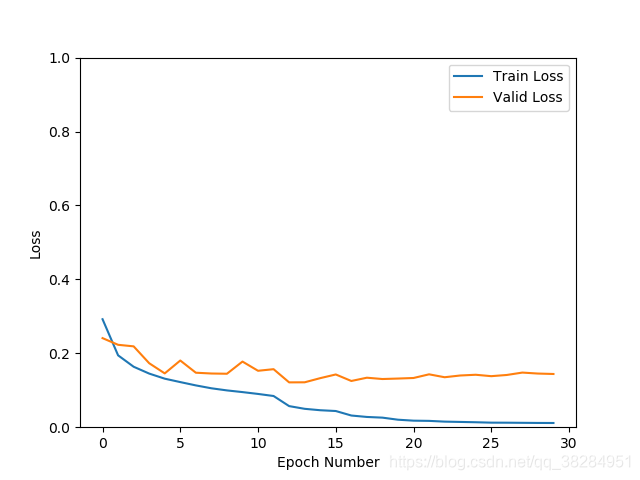
根据上一个模型,将推理错误的数据添加进数据集,设置图像增强的方式,加transforms.ColorJitter(brightness=0.5, contrast=0.5, saturation=0.5, hue=0.5)
并直接randomresizecrop为224 去除Resize224训练
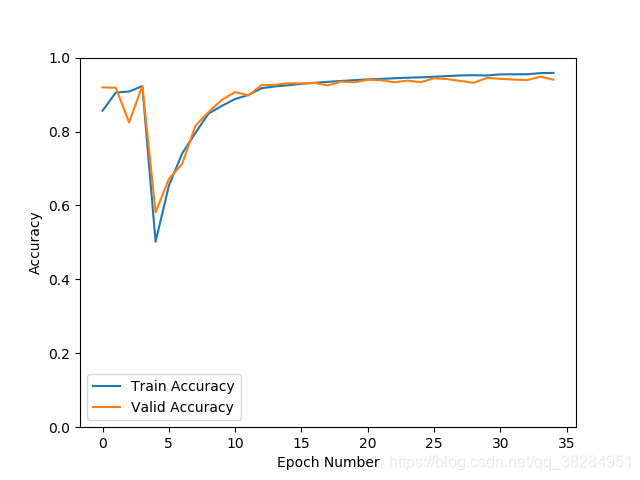
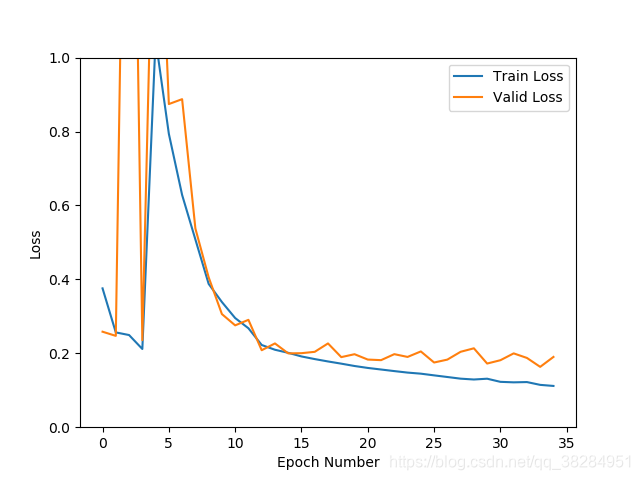
模型出现较大幅度震荡。跟学习率设置为0.01高了有关,也和样本之间的相似度低有关,先设置0.001的学习率试试看。如果依然震荡,说明样本之间的可能存在较大差异。
更新了0.001的学习率依然出现震荡,查看数据增强transforms的方法,发现亮度饱和度等的比例都为0.5,去掉其他,只保留亮度比列为0.2再测试,发现震荡明显减少。准确率97%,loss 0.11
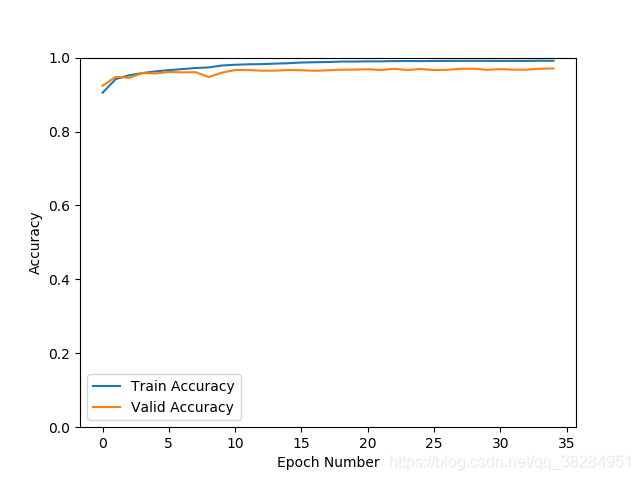
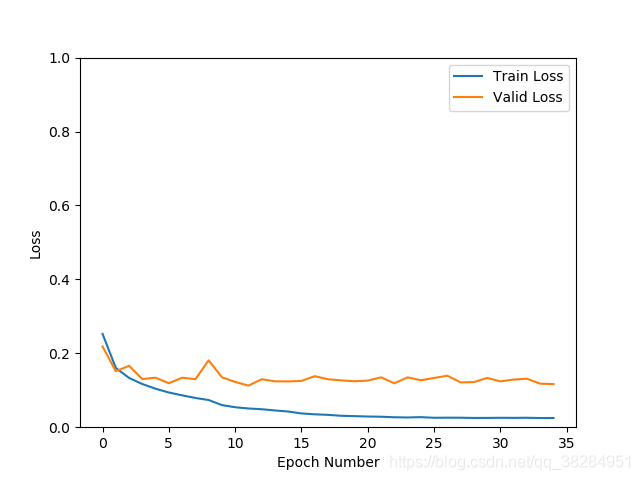
但是验证集的准去率还是上不去,loss也不再下降,查看日志发现
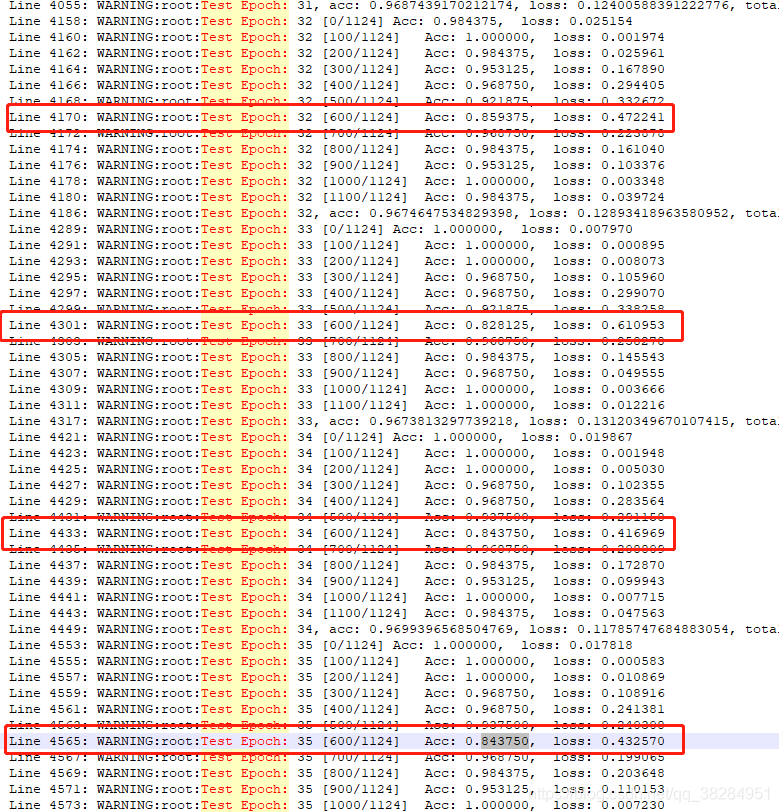
问题1.验证集每到5,6百个batch的时候准确率在80左右,验证集的数据没有打乱,于是拿出这批数据,放到此模型上预测,发现准确率都在0.9以上。不知道是什么问题,怀疑是hard samples。于是在验证的时候将验证集的结果输出日志看看。
问题2:3类别的分类,有一批新数据大概在22w张图片都为类别1,加入数据集中整个数据集的类别数量为,类别1:30w张 ,类别2:9w张,类别3:8w张,不知道类别间数量的不均衡,会不会影响模型的性能,查看了一些大佬的建议:一般情况下,如果不同分类间的样本量差异达到超过10倍就需要引起警觉并考虑处理该问题,超过20倍就要一定要解决该问题。
目前问题1和问题2都在进行中。
问题1是由于hard samples 引起的取出来后,准确率正常
类别不均衡问题,采用了focal loss的方案,继续之前的模型训练验证集loss在0.03 验证集的准确率在98.2%
class FocalLoss(nn.Module):
"""
This is a implementation of Focal Loss with smooth label cross entropy supported which is proposed in
'Focal Loss for Dense Object Detection. (https://arxiv.org/abs/1708.02002)'
Focal_Loss= -1*alpha*(1-pt)^gamma*log(pt)
:param num_class:
:param alpha: (tensor) 3D or 4D the scalar factor for this criterion
:param gamma: (float,double) gamma > 0 reduces the relative loss for well-classified examples (p>0.5) putting more
focus on hard misclassified example
:param smooth: (float,double) smooth value when cross entropy
:param balance_index: (int) balance class index, should be specific when alpha is float
:param size_average: (bool, optional) By default, the losses are averaged over each loss element in the batch.
"""
def __init__(self, num_class, alpha=None, gamma=2, balance_index=-1, smooth=None, size_average=True):
super(FocalLoss, self).__init__()
self.num_class = num_class
self.alpha = alpha
self.gamma = gamma
self.smooth = smooth
self.size_average = size_average
if self.alpha is None:
self.alpha = torch.ones(self.num_class, 1)
elif isinstance(self.alpha, (list, np.ndarray)):
assert len(self.alpha) == self.num_class
self.alpha = torch.FloatTensor(alpha).view(self.num_class, 1)
self.alpha = self.alpha / self.alpha.sum()
elif isinstance(self.alpha, float):
alpha = torch.ones(self.num_class, 1)
alpha = alpha * (1 - self.alpha)
alpha[balance_index] = self.alpha
self.alpha = alpha
else:
raise TypeError('Not support alpha type')
if self.smooth is not None:
if self.smooth < 0 or self.smooth > 1.0:
raise ValueError('smooth value should be in [0,1]')
def forward(self, input, target):
logit = F.softmax(input, dim=1)
if logit.dim() > 2:
# N,C,d1,d2 -> N,C,m (m=d1*d2*...)
logit = logit.view(logit.size(0), logit.size(1), -1)
logit = logit.permute(0, 2, 1).contiguous()
logit = logit.view(-1, logit.size(-1))
target = target.view(-1, 1)
# N = input.size(0)
# alpha = torch.ones(N, self.num_class)
# alpha = alpha * (1 - self.alpha)
# alpha = alpha.scatter_(1, target.long(), self.alpha)
epsilon = 1e-10
alpha = self.alpha
if alpha.device != input.device:
alpha = alpha.to(input.device)
idx = target.cpu().long()
one_hot_key = torch.FloatTensor(target.size(0), self.num_class).zero_()
one_hot_key = one_hot_key.scatter_(1, idx, 1)
if one_hot_key.device != logit.device:
one_hot_key = one_hot_key.to(logit.device)
if self.smooth:
one_hot_key = torch.clamp(
one_hot_key, self.smooth, 1.0 - self.smooth)
pt = (one_hot_key * logit).sum(1) + epsilon
logpt = pt.log()
gamma = self.gamma
alpha = alpha[idx]
loss = -1 * alpha * torch.pow((1 - pt), gamma) * logpt
if self.size_average:
loss = loss.mean()
else:
loss = loss.sum()
return loss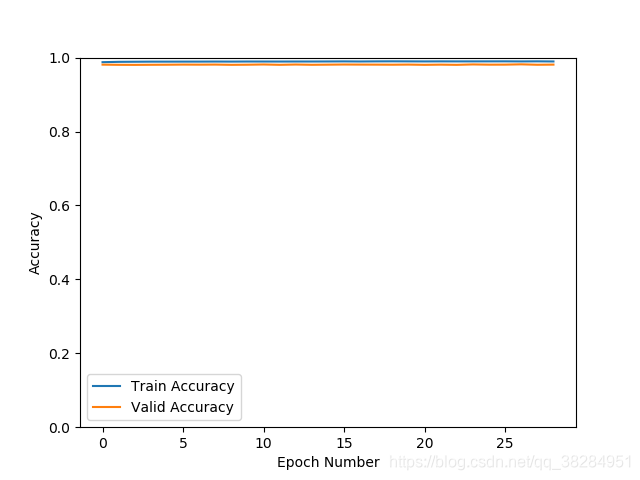
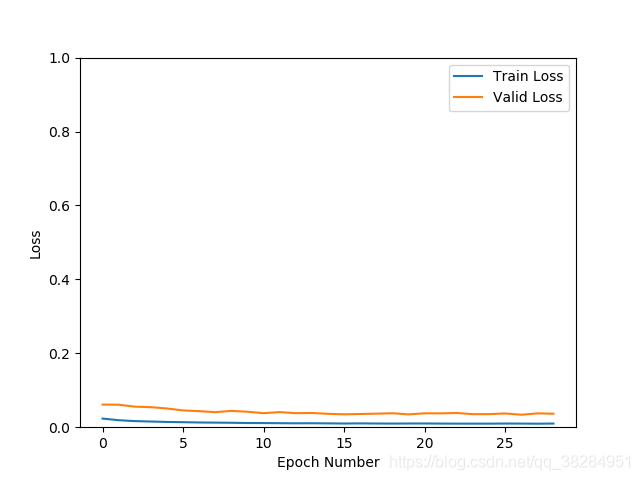
继续加入数据集训练。
更新中。。。。

















 4679
4679

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









