







原文:https://dzone.com/articles/how-much-testing-is-enough
bncov的核心是一个代码覆盖率分析工具。虽然有几个众所周知的工具可以提供对代码覆盖率的可见性,但我们希望构建一个解决方案,以增强和/或扩展以下领域的功能:
易于编写脚本。可编写脚本性是与大型分析工作保持一致并与其他工具结合使用的关键功能。
强大的数据呈现。良好的可视化可以加快并增强理解。
兼容模糊测试/测试工作流程。完全符合您需求的工具可提高生产率和速度。
支持二进制目标。有时你没有原始源代码。
虽然现有的代码覆盖率工具确实擅长其中一些,但由于我们对灵活性的要求,我们的主要重点是脚本可编写性。驱动目的是能够回答软件测试中的常见问题,这些问题通常需要来自静态和动态分析的信息的组合,因此灵活性对于回答各种潜在问题非常重要。我们发现Binary Ninja的插件非常适合此,因为它允许用户在python脚本环境中轻松利用Binary Ninja中的信息。
使用 bncov 的工作流程分为三个步骤。虽然第一步取决于您,但我们已使其他步骤易于管道化:
生成测试用例。测试用例可以通过任何方法生成,从模糊测试解决方案到手动测试用例开发。
从这些测试用例生成覆盖率数据。
使用 bncov 运行分析并显示输出。
运行二进制 Ninja 插件的正常安装过程(此处提供说明)后,第一步是收集覆盖范围信息。这是通过使用输入(也称为输入文件或种子)运行目标程序,并以 drcov 格式(来自 DynamoRIO 的内置 drcov 工具)收集覆盖范围来完成的。我们已经打包了一个脚本来简化此操作,但这不是一个简单的 bash 循环无法完成的。重要的是要注意收集的数据,因为这是最终进入插件并构成我们分析基础的数据。drcov 生成的覆盖文件包括执行的基本块,但不包括执行块的顺序或次数。
利用覆盖文件中的信息,我们现在可以使用 bncov 可视化区块覆盖。导入覆盖文件的整个目录,您将看到以热图方式着色的块,块从蓝色到紫色再到红色。较红的色调表示块被较小百分比的输入文件覆盖(即该块在输入中是“罕见的”),而较蓝的色调显示的块百分比较高,表示更常见的代码路径。根本没有被覆盖的方块不会被重新着色。此配色方案允许用户在查看函数时立即可视化哪些块已经过测试以及通用代码路径是什么。
覆盖范围可视化对于手动分析非常有用。 bncov的独特之处在于其脚本灵活性和自动分析能力。用于提供可视化的代码覆盖率数据可以在Binary Ninja的内置脚本控制台或普通python环境(仅通过Binary Ninja商业许可证提供)中使用,从而允许使用其现有的二进制知识进行其他分析。使用一组输入文件以编程方式推理代码覆盖率的能力非常强大,我们提供了一些内置示例作为起点,例如 GUI 命令“突出显示稀有块”和“突出显示覆盖率边界”。这些示例分别突出显示和记录仅由单个覆盖文件覆盖的块,以及具有向未覆盖块的传出边缘的块。用户可以在这些构建块之上构建各种有趣的分析来回答具有挑战性的问题,例如我们开始的问题:“我们应该做更多的测试吗?
作为演示,让我们演练一个具有内置测试资源的开源项目。开源XML库“TinyXML-2”(https://github.com/leethomason/tinyxml2)就是一个很好的例子,因为它是一个紧凑的库,包括一个测试程序、测试输入和一个Google OSS模糊工具。如果用户选择执行其他测试(如模糊测试),了解内置测试用例涵盖的代码并比较模糊测试产生的覆盖率是很有帮助的。通过使用 bncov 脚本来比较模糊测试之前和之后的覆盖文件集之间的覆盖率,简化了此过程。下面的代码是脚本中覆盖率比较过程的核心:
# bv is Binary Ninja’s BinaryView object of the target file
# CoverageDBs are bncov’s class that represents coverage information
first_covdb = coverage.CoverageDB(bv, first_coverage_dir)
second_covdb = coverage.CoverageDB(bv, second_coverage_dir)
unique_to_first = first_covdb.total_coverage - second_covdb.total_coverage
function_mapping = first_covdb.get_functions_from_blocks(unique_to_first)
for function, blocks in function_mapping.iteritems():
print " %s: %s" % (function, [hex(b) for b in blocks])
我们将从三组起始输入开始分析:
资源目录中包含的测试 XML 文件
从TinyXML-2的测试二进制文件中提取的XML输入。
从互联网上的多个测试套件收集的一组 XML 文件
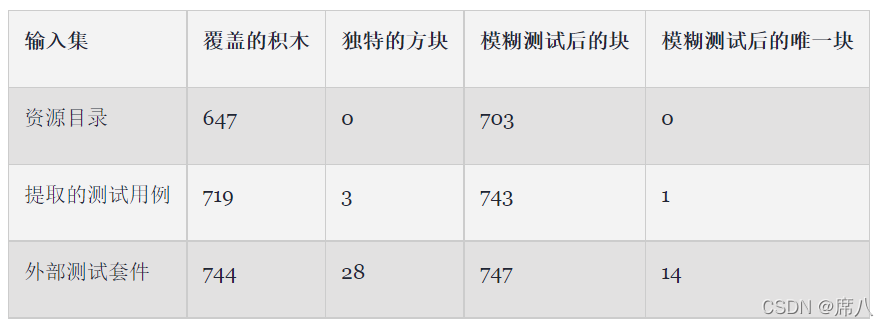
首先,我们使用 bncov 的 drcov 自动化脚本在每个输入集上收集覆盖率,以了解我们从不同输入获得的覆盖率的基线水平。我们编写了一个简单的程序,它使用TinyXML-2来解析和打印输入文件,我们将其用作收集覆盖范围的目标(以及稍后的模糊测试)。收集基线的结果表明,提取的测试用例提供的覆盖范围明显高于资源目录中的测试用例,这是有道理的,因为测试二进制文件包含资源中的所有测试。此外,正如您所料,多个外部测试套件的组合在初始输入集中的覆盖率最高。
通过使用每个输入集对目标程序进行模糊测试,我们将通过生成涵盖初始集没有的新基本块的测试用例来探索TinyXML-2中的新代码路径。模糊测试的结果将因多种因素而有很大差异:模糊测试器运行的时间和目标程序的速度、目标执行的输入处理类型、起始输入集的质量、模糊测试器的功能等。但是,在我们的例子中,我们希望比较覆盖率,并寻找输入集的块覆盖率的相对增加,因此我们只是使用AFL对同一时间段的每个输入集进行模糊处理。模糊测试完成后,我们使用 bncov 附带的脚本之一进行了一些比较。
正如预期的那样,在短暂的模糊测试运行后,我们看到每个输入集的覆盖范围增加。尽管模糊测试后,每个输入集之间覆盖的块数的差距会缩小,但某些块仅由外部套件找到。这个结果是有道理的,因为某些输入结构对于像AFL这样的模糊器来说更难合成。这就是一种称为符号执行的技术,即我们Mayhem解决方案中的一种技术,通常可以通过求解不太可能被模糊器的随机排列发现的输入来提供帮助。
[Figure 5]
使用脚本输出,我们现在可以开始回答 “多少是足够的测试?” 使用bncov,用户现在有了数据点,显示哪些功能已经被锻炼过,哪些基本块没有被现有的测试用例覆盖。通过包含的覆盖前沿分析,我们还可以看到现有测试输入和未触及的代码之间的边界,允许用户自动识别可以从进一步探索中受益的功能。这种类型的分析迅速增加了用户对目标代码的了解,而这正是回答 "多少是足够的 "所需要的信息。
import bncov
frontier = bncov.covdb.get_frontier()
function_mapping = bncov.covdb.get_functions_from_blocks(frontier)
for function_name, blocks in function_mapping.iteritems():
print "%s has %d frontier blocks" % (function_name, len(blocks))
[图 6:枚举每个函数的边界块。
覆盖率分析和使用覆盖率信息来增强模糊测试是一个活跃且发展中的研究领域。使用bncov来推理覆盖率是向前迈出的一步,因为它可以实现分析自动化,以及有针对性的应用技术以增强模糊测试(例如定向符号执行)所需的灵活推理。我们将在以后的部分中分享更多关于这些高级主题的信息,但与此同时,您可以在GitHub上分叉bncov并亲自尝试!我们希望它能帮助你更好地了解你的测试范围,并发现你可能错过的代码路径。

















 1060
1060

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









