







什么是事务
事务,就是把多个数据库操作打包成一个不可分割的整体进行执行。同时到这些操作执行后,需要保证数据的一致且可靠。
在 mysql 中可以通过下面的 SQL 开启一个事务:
-- 开启事务
START TRANSACTION;
-- 关闭默认提交,默认开启提交:0
SET autocommit = 1;
-- 业务 SQL
UPDATE users SET name = '张三-upd' WHERE name = '张三';
-- 提交事务
COMMIT;
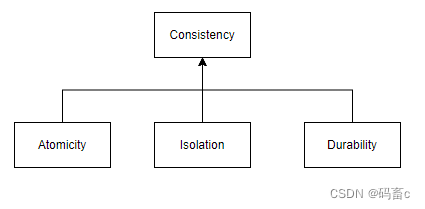
InnoDB 解决事务的一致且可靠问题的完整方案
InnoDB 存储引擎是基于 ACID 模型解决的事务一致且可靠问题。
- Atomicity:原子性
- Consistency:一致性
- Isolation:隔离性
- Durability:持久性
一致性是最终的目标。原子、隔离、持久性都是服务、实现一致性。
原子性
指事务中的所有操作都需要像原子一样不可分割,要么事务中的多个全部成功,要么全部失败。
隔离性
指不同事务在执行期间互相隔离、不能互相干扰、不能查看彼此为提交的数据。
在没有实现隔离性前,多个事务同时执行时,会有三大明显问题:
脏读、写
一个事务读取或更新了另一个事务并没有进行事务提交的数据,当另一个事务回滚时而产生的读写问题。
例:假设有两个事务:A、B
- 脏写:A将一行数据的某个字段值写为C,B写为D,由于A进行了事务回滚,导致B的写入失效。(并发 写-写)
- 脏读:A将一行数据的某个字段值写为C,B读取C,由于A进行了事务回滚,导致B读取了脏数据C。(并发 写-读)
不可重复读
在事务执行过程中,对于同一条数据的多次读取,每次读取的数据都是不同的。对比脏读,多出了一种情况:读取的数据是其他事务修改后且提交数据。
例:假设有两个事务:A、B
- A将一行数据的某个字段值写为C,B读取C,由于A进行了事务回滚,导致B读取了脏数据C。
- B先读取C,A将其改为D并提交事务,导致B再次读取了D。
幻读
相比脏读、不可重复读,侧重点为读取到了在之前的查询时未曾被查询到的>=1条数据。
例:假设有两个事务:A、B。A查询用户表年龄大于20的人员数据有10条。B插入并提交了5条年龄大于20的人员数据。A再次查询时发现年龄大于20的数据变为了15条。
隔离性小结
- 本质是并发读写、读取了错误的可读版本引发的问题
- 脏读:读取了未提交版本的数据
- 幻读、不可重复读:读取了未提交、已提交版本的数据
正确的隔性实现,应当满足每次读取的数据,都是开启当前事务时的数据版本。不能读取到未提交的版本,或超前的版本。
SQL标准中的四种隔离级别
为了解决以上的问题,Mysql 实现了 SQL 标准中的四种隔离级别来实现隔离性。开发者可以根据需求进行选择:
- read uncommitted(读未提交:可以读取其他事务未提交的数据,但不能写即修改这些数据。并发性最高,但存有脏读的问题、不可重复读、幻读问题)
- read committed(读已提交:可以读取其他事务已提交的数据,避免了脏读、写。但存有不可重复读、幻读的问题)
- repeatable read(可重复读:避免了脏读脏写、不可重复读的问题。但存有幻读的问题)
- serializable(串行化:多个事务操作同份数据时,串行化执行。避免了所有的并发读写引发的隔离性问题,但并发性最低)
| Level | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| Read uncommitted | ✓ | ✓ | ✓ |
| Read committed | ✖ | ✓ | ✓ |
| Repeatable read | ✖ | ✖ | ✓ |
| Serializable | ✖ | ✖ | ✖ |
MySQL默认的事务隔离级别为RR,但MySQL实现的RR级别与SQL标准的RR级别不同:MySQL实现的RR级别可以避免幻读发生,即可以避免脏读脏写、不可重复读、幻读的问题。
可见四种级别的特点都是不同的,需要在隔离力度与并发性之间做出选择。
Mysql 中可以通过下面的 SQL 查看并设置隔离级别:
-- 查看隔离级别
SHOW VARIABLES LIKE 'transaction_isolation';
-- 设置隔离级别
SET transaction_isolation = '';
持久性
指事务一旦提交,那事务中所有的修改就不会因为电源故障、系统崩溃等意外条件而丢失。
一致性
当保证了原子、隔离、持久性后,最核心的一致性也就达成了。即无论有多少事务在执行,无论事务中有什么样的操作,执行之前、执行过程中、执行以后的任意时刻,数据库的状态都是一致且稳定的。都可以精准的判断数据的变化,而不是数据随机混合的。
InnoDB 实现 ACID 模型的具体机制
-
原子性:undo log,当对数据进行增删修时,都需要先将对应的 uodo log 记录下来。
一般来说每个操作都会对应一个 undo log,有些操作可能会对应多条。根据 undo log,当事务中的操作发生异常时,反向执行每次记录的 undo log 就可以进行数据的回滚,恢复到操作之前。 -
隔离性:锁机制 + MVCC 机制
-
持久性:redo log + double write
- 内存缓冲区 BufferPool 中的数据在写入磁盘前,系统发生了崩溃,导致内存中的刷盘数据丢失:InnoDB 通过双写 redo log buffer & redo log 的机制来保证发生故障后可以从磁盘中的 redo log 文件重新获取还没有刷到 ibd 文件中的数据
- 将内存缓冲区 BufferPool 中的数据页刷盘到磁盘 ibd 文件过程中,若发生了系统崩溃,导致数据丢失:InnoDB 通过 double write buffer 的 双写机制来保证整个数据页的完整传输。
原子性原理
InnoDB 存储引擎中,是通过 Undo log 机制实现的事务中的原子性,回滚操作的一种机制。
每个事务在进行数据操作的时候,都会在磁盘中创建与之对应的 undo log。当事务异常时,会根据 undo log 逐一对操作的数据进行回滚,保证事务的原子性。
那么是在什么时候写入 undo log 的呢?在事务中,每个影响数据的 SQL 通过执行器执行后,首先:会在回滚段 undo log segment 中申请一个 undo log 页。然后根据 SQL 信息构造 undo log 内容,然后将其写入 undo log buffer,在刷盘到磁盘中的 undo log 文件,以保证每次操作真正数据之前,undo log 都是完整记录的。这样即使发生了异常也可以保证完整的撤销。
undo log 的页结构
那么申请的 undo log 页具体的格式是什么样的呢?
基础格式:
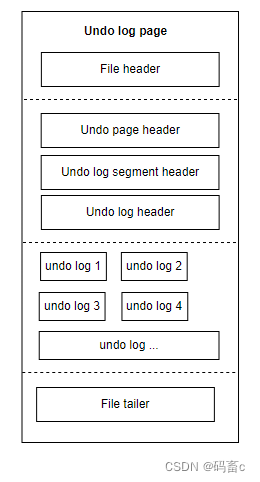
undo log 页和其他的页一样,都会包含页头与页尾行。除此之外,还包含以下部分:
- undo page header:记录了 undo 页类型、log 偏移位置、下一页链表引用等信息的 undo page header
- undo log segment header:记录了回滚段信息
- undo log header:记录了事务相关信息、重用 undo 页信息
- undo log:剩余的所有空间,都会存储 undo log 日志本身了
undo log 页中 undo log 的结构
大体可以分为两部分:基本信息、根据不同操作而不同的操作信息
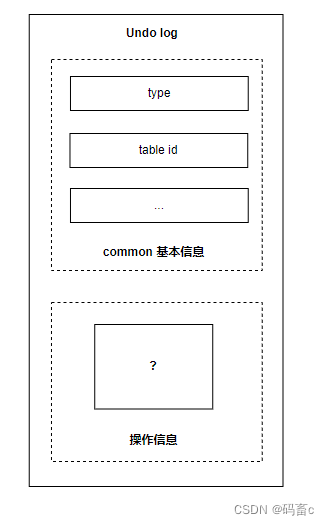
根据 undo log 的 type 类型,最常见的可分为以下几种页:
-
增:TRX_UNDO_INSERT_REC
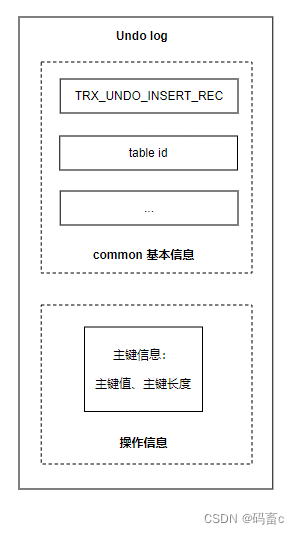
新增时的 undo log 操作信息相对简单,只记录了主键信息:主键值、主键长度 -
删:TRX_UNDO_DEL_MARK_REC
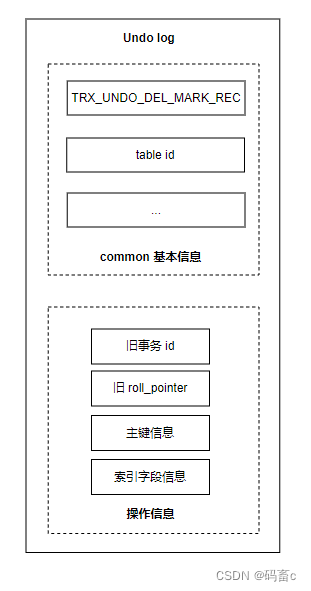
删除的 undo log 除了记录主键信息外,还记录了旧的事物 id,旧的回滚指针,以便可以找到前继版本,用来构建有序的 undo log 版本链。除此之外,还有索引字段信息。 -
改:TRX_UNDO_UPD_EXIST_REC
修改分为两种情况:
- 如果不更新主键:在删除页的基础之上加上被更新的信息
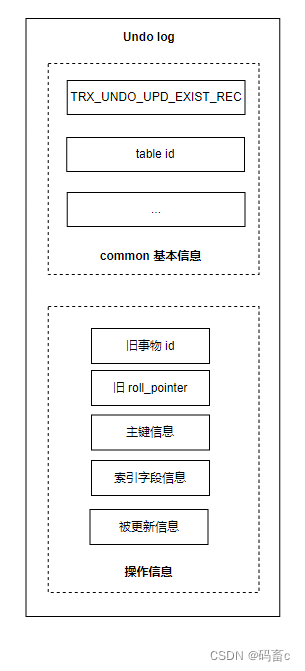
- 如果更新了主键:则会记录两条 undo log,一条删除的,一条新增的。
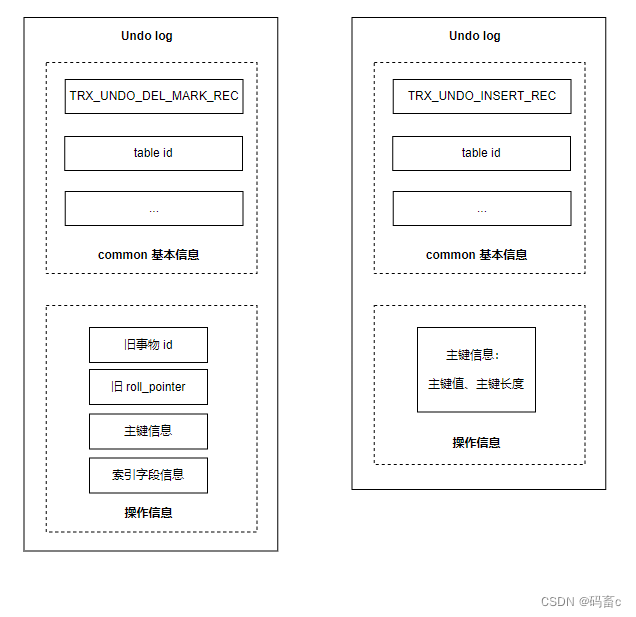
- 如果不更新主键:在删除页的基础之上加上被更新的信息
若某个事务中的内容很大,一个 undo log 页没有办法完整记录,就需要申请新的 undo log 页。然后通过 undo page header 中的下一页链表引用进行关联。并且,后面的 undo log 页就不需要记录其他的行信息了:
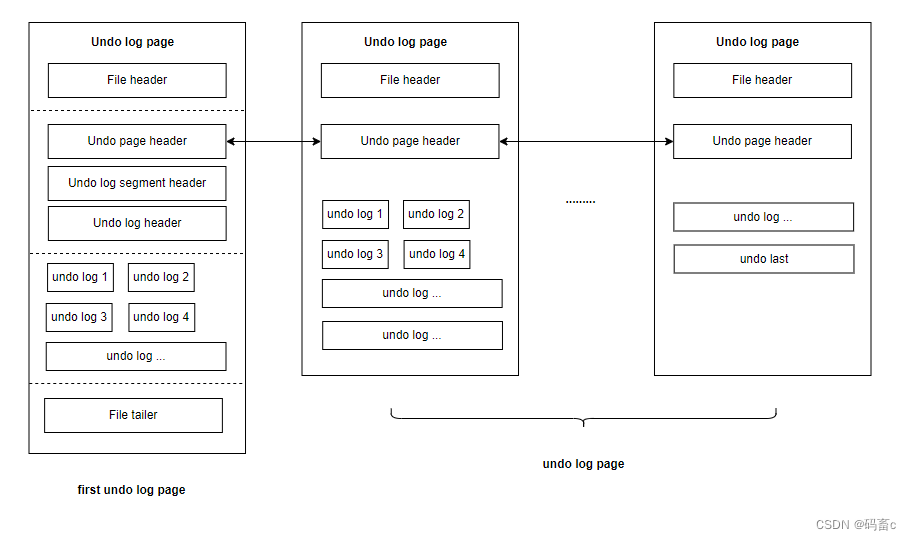
以上由 undo log 页构成的链表就叫做 undo 链。
特别说明一点,由于新增产生的 undo log 在事务提交之后,就可以直接删除了。而删除和更新的 undo log 还需要服务我们之后提到的 MVCC,并不能直接删除。
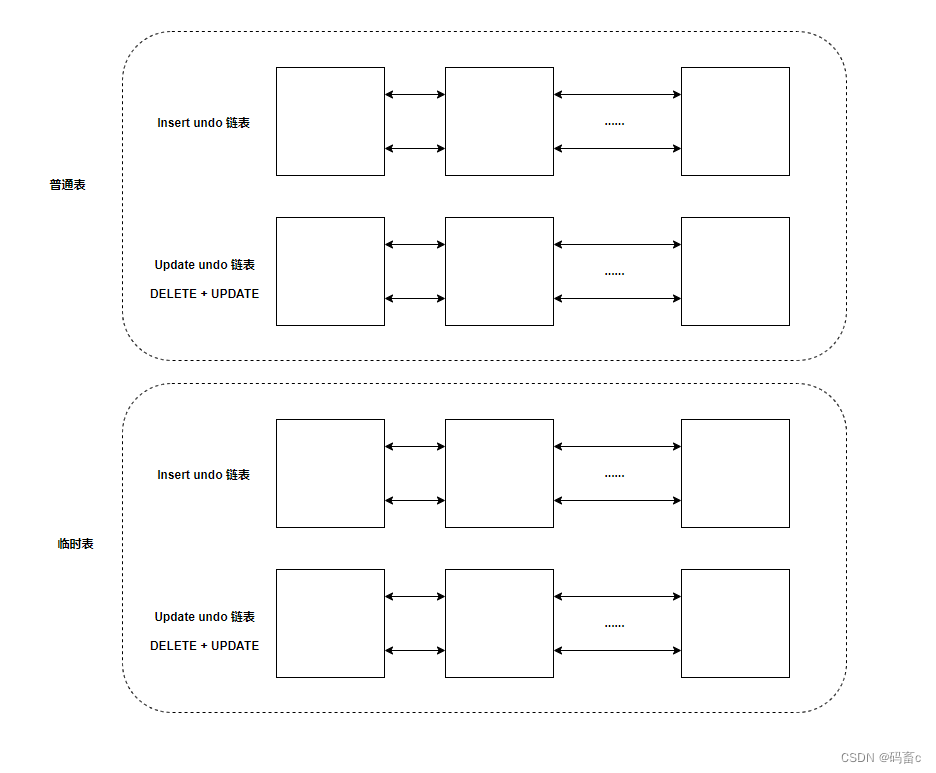
为了最大程度节省空间,提升效率,对 undo log 页分为两大类:
- insert undo 链表:只记录新增操作,事务提交后可以直接清除
- update undo 链表:记录删除、更新操作
很多时候,在一个事务中不仅有对于普通表的新增、修改操作,还可能生成临时表。所以,又需要对于临时表,在创建两个 undo log 链,如下图(undo log 的完整存储格式):
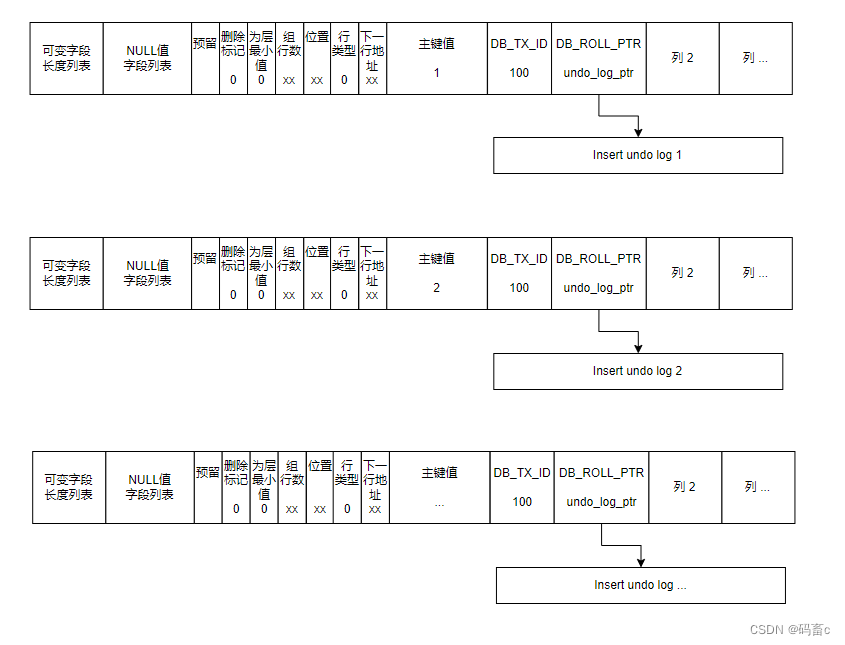
从数据角度出发查看 undo log
undo log 是如何体现在数据页中的 Dynamic row 行记录上的呢?
新增数据的 undo log 很简单,Insert undo 链表中每个节点都会对应一条数据行。在数据行中的 roll_ptr 字段记录 undo log 结点的指针即可,回滚时就可以通过它找到需要回滚的 undo log 了。
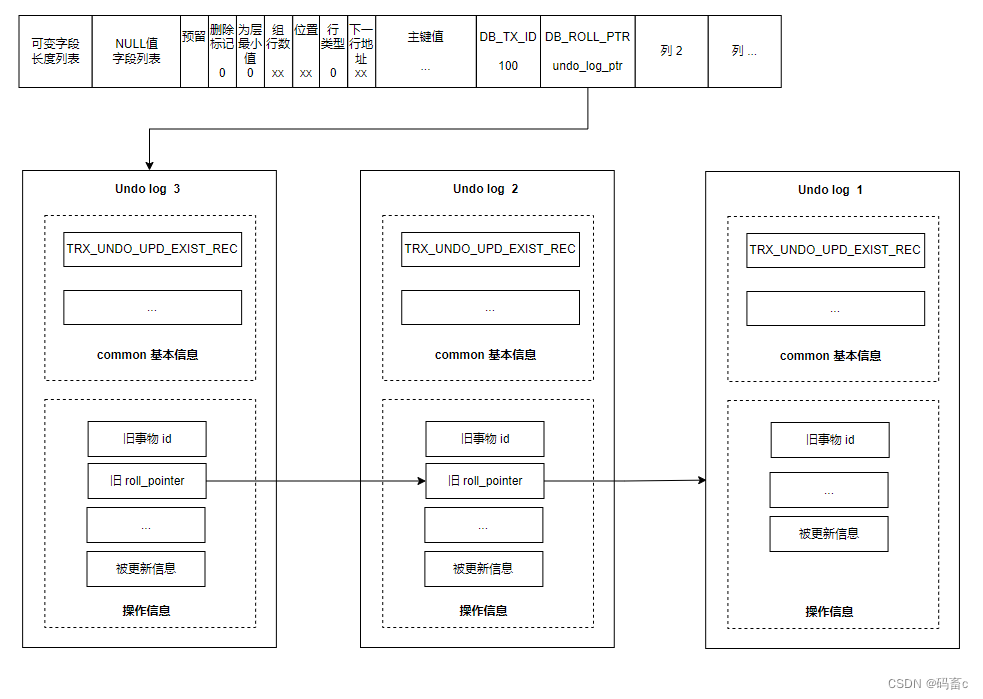
对于修改数据,Update undo log 版本链表中的每个节点都会对应一条数据行的历史版本。
每次更新,都会先将修改前的数据作为一个 update undo log 追加到数据行的版本链中,将在修改后把数据同步到数据行。并通过数据行中的 DB_RPOLL_PTR 关联刚刚新增到版本链中的 undo log 节点。回滚时找到数据行关联的 undo log 的最新节点,就可以找到整个历史修改记录了。
undo log 版本链在隔离性的实现机制 MVCC 中起到了至关重要的作用。
隔离性原理
指不同事务在执行期间互相隔离、不能互相干扰、不能查看彼此为提交的数据。分为:读写隔离、写写隔离。在 InnoDB 的 Repeatable Read 隔离级别中,通过锁机制 + MVCC 实现了完整的事务隔离性。
实现原理一:锁机制
锁的作用是使得多个事务之间的操作相互不影响。在事务操作一些数据之前,就会先对数据进行加锁,防止其他事务进行操作。在操作完之后,就会对锁进行释放,此时其他事务就可以上锁进行操作。
锁结构
回忆一下前面的 blog :Mysql 运行原理 (2) - SQL执行原理与InnoDB读写原理 中 InnoDB 读写原理图,在 BufferPool 中专门的一块区域,记录了锁的信息。下面我们将锁的具体信息单独拿出来进行分析。
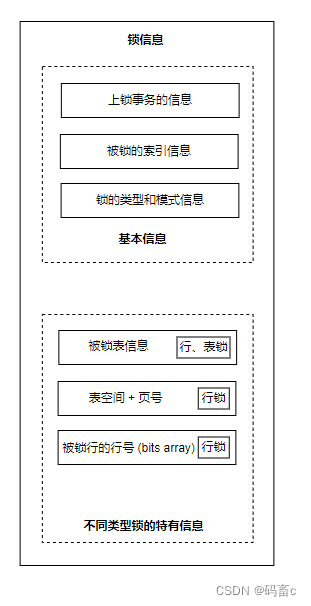
- 上锁事务的信息:记录了所属事务的 id
- 被锁的索引信息:锁加到了哪个索引上。聚簇索引,非聚簇索引(即二级索引)都可以被加锁
- 锁的类型和模式:使用一个 32 位的 BIT 数来表示。分为:
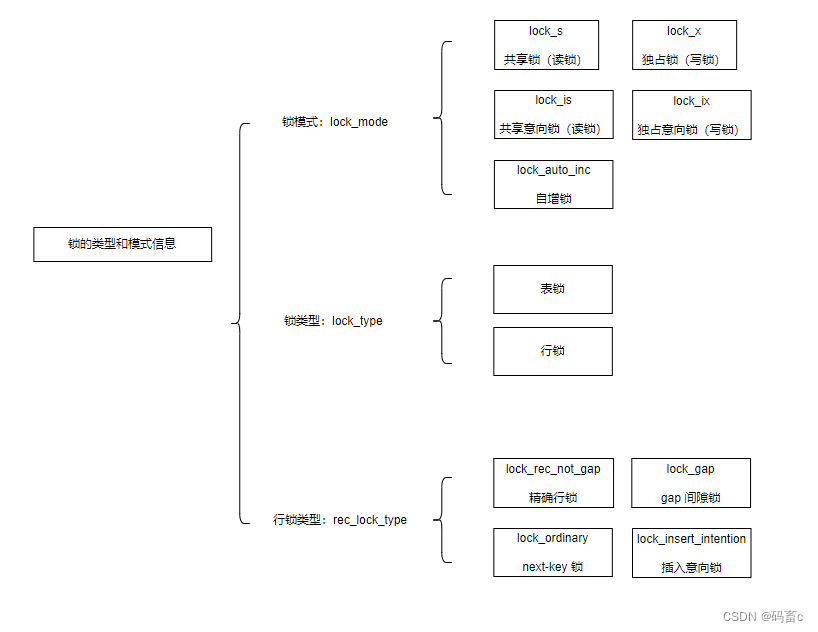
共享锁、独占锁
共享锁与独占所就是读写锁,遵循读写锁的特性:
- 读读不互斥
- 读写互斥
- 写写互斥
因为读取数据不涉及修改数据,不应该是互斥的操作,所以并发读是不需要进行并发控制的。
反之,只要涉及写操作,无论其他线程是读还是写,都需要互斥。互斥读可以防止读取到未更新的历史数据。互斥写可以防止写数据丢失。
这样,根据读写锁,就可以防止数据被其他事务修改了。
可以根据下面的 SQL 开启读锁与写锁:
-- 加读锁
SELECT u.* FROM users u WHERE u.id = 1 LOCK IN SHARE MODE;
-- 加写锁
SELECT u.* FROM users u WHERE u.id = 1 FOR UPDATE;
下面我们进行互斥测试(如果通过终端工具进行测试,需要开启两个执行窗口分别执行):
-- 开启事务 1
START TRANSACTION;
-- 加读锁
SELECT u.* FROM users u WHERE u.id = 1 LOCK IN SHARE MODE;
-- 暂不提交事务 1
-- COMMIT;
-- 开启事务 2
START TRANSACTION;
-- 加读锁
SELECT u.* FROM users u WHERE u.id = 1 LOCK IN SHARE MODE;
-- 加写锁
-- UPDATE users SET `name` = "张三-upd" WHERE id = 1;
SELECT u.* FROM users u WHERE u.id = 1 FOR UPDATE;
-- 提交事务 2
COMMIT;
先执行第一个 SQL 片段,在执行第二个 SQL 片段:
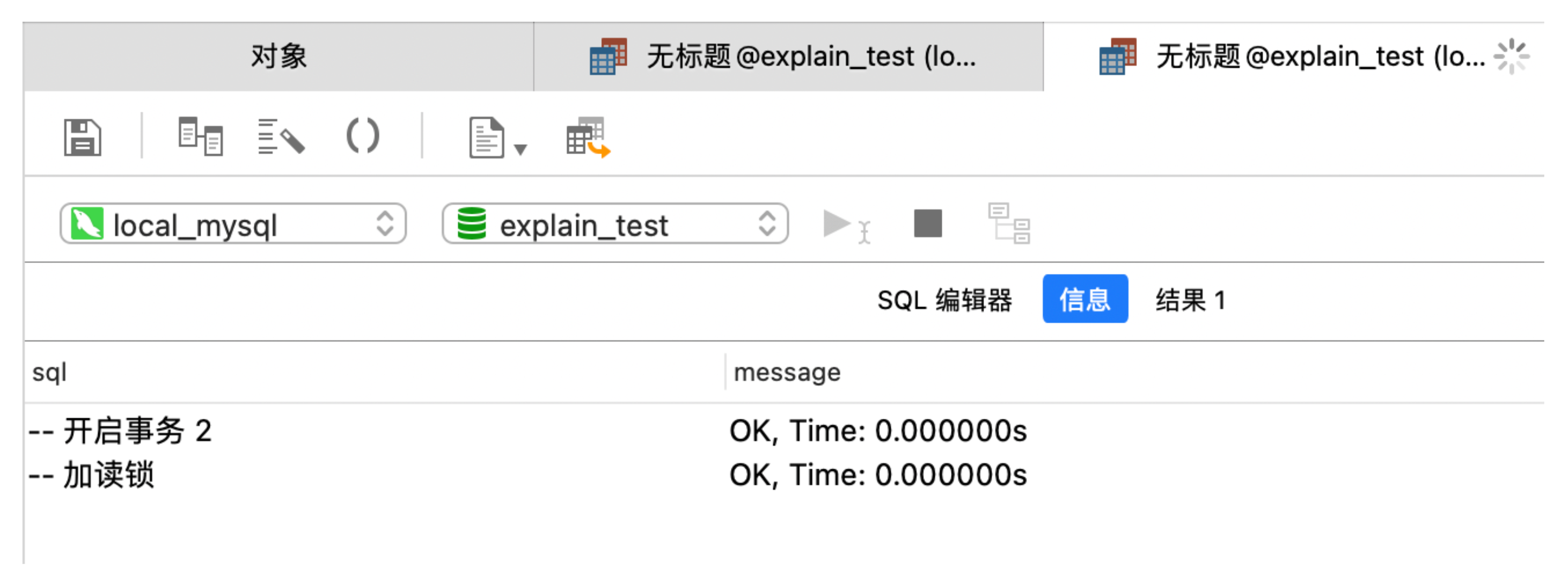
可以发现,事务 2 阻塞在了加写锁语句,终端上一直处于 watting 状态。当在窗口 1 执行事务 1 的 commit 操作后,窗口 2 的 SQL 就可以全部执行完毕了。可以发现一个问题:默认的,事务提交后就会释放数据上的锁资源。
合理的使用读、写锁可以解决事务间因写入而导致的脏读、不可重复读问题。
因为两种锁是互斥的,无论是先读取还是先写入,都必须等到先执行者的事务提交后释放了锁资源才能继续操作。
如果事务 A 先读取,则事务 B 就不能写入,事务 A 就不会读取到事务 B 已提交的数据,或读取到事务 B 修改但又回滚的数据。
如果事务 B 先写入,则事务 A 就必须等到事务 B 提交后才能正常读取数据。
总结下来就是读写锁会使得事务串行执行,但可以控制锁的粒度减少等待成本。这是访问冲突数据的情况,对于没有冲突访问数据情况,不同事务间不存在串行化。
但是幻读的情况还是存在的,因为新增且提交的数据,是没有进行加锁控制的,还是可以查询出来。
共享意向锁、独占意向锁
意向锁的功能简单许多,在上锁时会在表上做一个标记,表示这个表已经被加锁了。这样做的好处是,不需要遍历每一条数据是否有锁,提升了锁判断的效率。
自增锁
自增锁是一个表锁,为配置了 AUTO_INCREMENT 的自增列服务。在插入数据时,会增加自增锁然后生成自增值,并阻塞其他的插入操作,以保证自增值的唯一。
如果自增值已经生成,但是事务已经回滚了,自增值也不会回退,意味着自增值可能不连续。
自增锁的机制可以通过下面的 SQL 进行查看:
-- 查看自增锁机制
SHOW VARIABLES LIKE 'innodb_autoinc_lock_mode';
有三种取值(0/1/2):
-
simple insert(可以预先知道插入数据的数量): insert into … value(…) / insert into … values(…),(…)
-
bulk insert(无法知道插入数据的数量): insert into … select …
-
0:自增场景都添加自增锁到 SQL 执行完成,无论是 simple insert 还是 bulk insert,可以保证自增值的连续性。
-
1:对 0 的优化,simple insert 只会使用一个轻量的 mutex 锁获取一段连续的自增值,而不是增加自增表锁,无需等待 SQL 完全执行完毕才释放自增锁。
对于 bulk insert 依旧是使用自增表锁来保证主键的连续性,即必须等到 SQL 完全执行完后才能释放自增锁。 -
2:完全无锁,并发度最高,但是主键可能是不连续的。
表锁、行锁
- 表锁:在释放锁之前,拒绝其他事务操作这张表的任何数据,在特有信息中会记录被锁表的信息
- 行锁:对表内某些行进行加锁。在特有信息中会记录被锁表的信息、所属表空间、页号,以及最重要的一个 bits 数组,记录了哪些行被锁了。
行锁都是添加到数据行或索引行上,也就是聚簇索引树的行、非聚簇索引树的行上(非聚簇索引也叫做二级索引)。
行锁类型
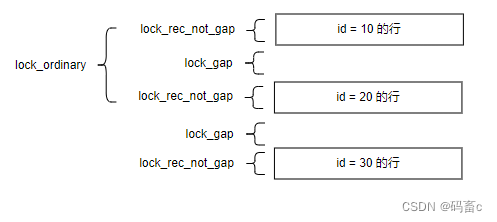
根据不同的条件会选择不同功能的行锁。
-
lock_rec_not_gap:精准行锁,锁住精准行。
-
lock_gap:间隙锁,锁住行与行之间的间隙,防止在行间隙中插入数据。
-
lock_ordinary:精准行锁与间隙锁的结合。
总结:这三个行锁的范围根据不同的 where 范围条件进行选择。
间隙锁锁的是个范围(x, y),搭配上行锁就会变成(x, y],即 next key lock。 -
插入意向锁:一个特殊的间隙锁,也是共享锁。如果一个行间隙添加了间隙锁,这时如果其他事务要在这个行间隙插入数据,就会加插入意向锁。由于是共享的,所以多个事务都可以加这个锁。当间隙锁释放时,允许多个阻塞在插入意向锁的事务同时进行,不需要串行执行提高效率。
实现原理二:MVCC
multi-version concurrency control 多版本并发控制机制。该机制不仅可以更高效的解决读写锁机制解决的脏读、不可重复读问题,还可以解决幻读。
MVCC 机制在某些场景下可以替代效率更低的锁机制,在保证隔离性的基础上,提升了读取的效率和并发性。
那么 MVCC 机制是如何实现的呢?MVCC 是基于前面讲到的 Undo log 版本链和 Read View 读视图来达成的。
下面我们有一条数据行的 undo log 版本链,那么当我们想要读取数据时,该选择哪一个版本的数据呢?
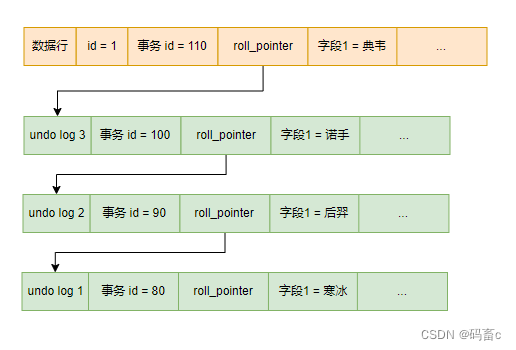
这里我们就需要使用 Read View 来实现了。Read View 是一个视图的内存结构,在事务中通过 select 查询数据时,就会构造一个 Read View。里面记录了该数据版本链的一些统计值。这样在后续查询处理时,就不需要在遍历所有版本链了。这些统计值具体包括:
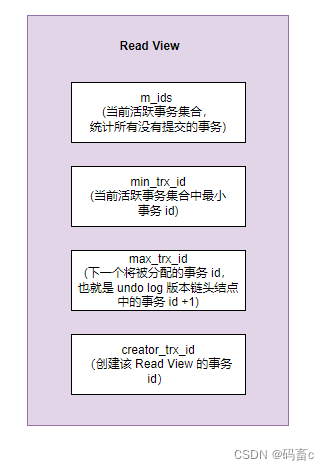
MVCC 解决脏读问题
构建好 Read View 后,需要根据特定的查询规则,才能找到唯一的可用版本,解决脏读问题
以下面的 id 为 1 的数据行的 undo log 版本链为例(注意 undo log 版本链中是包含了数据行的),我们在最新事务 id 为 120 的事务中执行查询该数据的 select 语句并构建 Read View(m_ids 不包含 80 是因为该事务已提交,不是一个活跃事务):

从链表头节点开始遍历所有版本,根据下面的三步查找规则,判断每一个版本:
- 当前事务的版本:该版本的 trx_id = creator_trx_id,满足则意味着读取自己修改的数据,可以直接访问。
- 超前版本:该版本的 trx_id > max_trx_id,意味着该版本在当前事务生成 Read View 之后才生成,不可访问。
- 不超前的已提交版本:该版本的 trx_id < min_trx_id & not in m_ids,满足则意味着该版本不是超前版本,且事务不是一个未提交的活跃事务,可以直接访问。比如 undo log 1。
这样从链头遍历到链尾,找到首个符合要求的版本即可。就可以查询到其他事务已经提交的数据,或在当前事务中修改后的数据。最终查询到字段1为寒冰的版本。
MVCC 解决不可重复读问题
其实已经通过上面的 Read View 解决了。因为即使数据行的 undo log 版本链新增了节点,即其他事务再次进行了修改。但 Read View 是不变的,里面的各种统计信息不会发生变化,依旧为当前事务执行 select 语句时构建的那个 Read View,后续查询依旧使用这个 Read View。这样,根据 Read View 的 max_trx_id 就可以过滤掉新增的 undo log 版本节点,所以每次都查询结果都是一样的。Repeatable Read 隔离级别就是使用的这种方式
相反,如何事务中的每次查询都创建一个 Read View,就会出现不可重复读问题。Read Committed 隔离级别就是使用的这种方式。
快照读与当前读
根据前面 MVCC 的应用我们可以发现:MVCC 之所以解决脏读、不可重复读,重点都是在于事务中 select 执行时构建的 Read View。如:select … / select … where …
Read View 就如一个快照一样,记录了 select 时数据行的各版本的事务信息,间接的达到了记录数据行的历史版本的快照。所以,Read View 也称为 快照,通过 Read View 搜索唯一可用的版本也称为快照读。
当前读,可以通过下面的语句触发:
- insert、update、delete
- select … for update
- select … lock in share mode
二者的区别是什么呢?
- 当前读:读取的是记录的最新已提交版本,并且当前读返回的记录,都会加上锁,保证其他事务不会再并发修改这条记录。即不会搜索历史版本。
- 快照读:根据 Read View,可以读取数据行的历史版本,且是无锁操作。
可能会发生这情况,一个事务中,同时出现快照读与当前读,导致对于某一行数据的查询结果是不同的,如下例:

-- 事务 1
START TRANSACTION;
-- 快照读
SELECT * FROM users u WHERE u.id = 1;
-- 当前读
SELECT * FROM users u WHERE u.id = 1 FOR UPDATE;
-- 快照读
SELECT * FROM users u WHERE u.id = 1;
COMMIT;
-- 事务 2
START TRANSACTION;
UPDATE users SET NAME = '张三-upd' WHERE id = 1;
COMMIT;
执行顺序:
- 事务1 -> 快照读 (张三)
- 事务2 -> 修改并提交
- 事务1 -> 当前读 (张三-upd)
- 事务1 -> 快照读 (张三)
当前读与快照读分别读取不同的数据。并且, 当前读不会修改 Read View 中的事务数据,使得后继的快照读能读取到数据行最新的已提交 undo log 版本。假设当前读会修改 Read View,那么就会产生不可重复读的问题。
MVCC + next key 锁 解决快照读、当前读查询的幻读问题
1. MVCC 机制解决快照读下的幻读问题:如果仅是快照读,根据 undo log 版本链 + Read View 就可以解决幻读的问题。
- 其他事务对数据的修改会产生新版本的 undolog,那么事务id必定大于当前事务的 ReadView 中的 max_trx_id,所以不会查询到最新修改的数据。
- 其他事务新增的数据行上的事务id字段必定大于当前为提交的事务,所以事务id也必定大于当前事务的 ReadView 中的 max_trx_id,所以不会查询到最新新增的数据。
防止幻读的例子:
-- 事务 1
START TRANSACTION;
-- 当前读,添加 next key 锁,锁住:[2, +∞]
SELECT * FROM users u WHERE u.id >= 2 FOR UPDATE;
COMMIT;
-- 事务 2
START TRANSACTION;
INSERT INTO `users`(`name`, `email`, `password`) VALUES ('孙七-2', 'qianqi@example.com', 'password123')
COMMIT;
执行循序:
- 事务 1 执行当前读,加 next key 锁但不提交
- 事务 2 执行新增,被阻塞
也就是说,通过 next key 锁的互斥性,阻塞其他事务新增数据。使得事务 1 中的所有查询都不会出现幻读的情况,但缺点显而易见,降低了并发度。
防止幻读失败的例子:
-- 事务 1
START TRANSACTION;
-- 快照读
SELECT * FROM users u WHERE u.id >= 2;
-- 当前读,添加 next key 锁,锁住:[2, +∞]
SELECT * FROM users u WHERE u.id >= 2 FOR UPDATE;
-- 快照读
SELECT * FROM users u WHERE u.id >= 2;
COMMIT;
-- 事务 2
START TRANSACTION;
INSERT INTO `users`(`name`, `email`, `password`) VALUES ('孙七-2', 'qianqi@example.com', 'password123')
COMMIT;
执行循序:
-
事务 1 执行快照读

-
事务 2 执行新增并提交
-
事务 1 执行当前读

-
事务 1 执行快照读
其实思考一下,问题的根源就是一个事务中同时出现了快照读与当前读,并且快照读中是没有幻读的问题。将二者查询的结果进行比较,则出现了幻读。
总结一下预防幻读的方法:
- 一个事务中最好全部都是快照读
- 一个事务中若同时存在快照读与当前读,则必须保证当前读最先执行,锁住 select where 条件匹配的数据行空间,来防止其他事务新增数据导致的幻读。当锁住后,快照读也是一定不会出现问题的,因为不会有新的 undo log 追加到数据行的版本链中。
InnoDB 实现四种隔离级别原理
| Level | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| Read uncommitted | ✓ | ✓ | ✓ |
| Read committed | ✖ | ✓ | ✓ |
| Repeatable read | ✖ | ✖ | ✓ |
| Serializable | ✖ | ✖ | ✖ |
回顾一下 SQl 标准中的四种隔离级别,以及每种级别可以解决的问题。
对于脏读、不可重复读、幻读这些隔离性问题,解决方式不仅一种。
最简单直接的,使用锁机制实现:
- 读、写锁:解决脏读、不可重复度
- next key 锁、排它锁:解决幻读
不过使用锁的缺点很明显:频繁的加锁与解锁会严重影响性能。
InnoDB 采用了锁 + MVCC相接合的机制,通过一种更高效的方式解决了以上的问题。
- Read uncommitted
- 读:不加锁,直接读取数据版本链中最新的版本,即当前读。会出现脏读、不可重复读、幻读问题。
- 写:增加共享行锁,事务结束时释放。使得事务提交前,其他事务不能修改数据,但可以被读取。
- Read committed
- 读:不加锁,使用快照读,根据 MVCC 机制读取可读的数据版本。但每次查询都会构建一个 Read View,所以可以避免脏读问题,会出现不可重复读、幻读问题。
- 写:增加独占行锁,事务结束时释放。使得事务提交前,其他事务不能修改数据,也不能被当前读查询。
- Repeatable read
- 读:不加锁,使用快照读,根据 MVCC 机制读取可读的数据版本。但无论少次查询,都会只构建一个 Read View,所以可以避免脏读、不可重复读问题。配合 next key 锁,可以解决当前读下的部分场景下的幻读问题,具体可以查看。
- 写:增加 next key 范围行锁,事务结束时释放。使得事务提交前,其他事务不能修改、插入、删除该区间内的数据,同时也不能被当前读查询。
- Serializable:
- 读:直接添加共享表锁,同时均读取版本链中最新的版本。因为读写互斥,所以可以解决所有的隔离性问题,但并发度最低。
- 写:增加独占表锁,事务结束时释放,读写操作完全串行执行。但读读操作可以同时执行。
持久性原理
redo log 与 double write 的详细说明可以查看 blog: Mysql 运行原理 (2) - SQL执行原理与InnoDB读写原理 中的名词解释。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









