




 本文深入探讨SparkStreaming的核心概念,包括DStream操作、实时处理原理及与Flume、Kafka的整合实战。涵盖流式批处理、容错机制、实时性分析,以及通过实例演示如何接收Socket数据、实现单词计数、热词统计,整合Flume和Kafka进行实时数据处理。
本文深入探讨SparkStreaming的核心概念,包括DStream操作、实时处理原理及与Flume、Kafka的整合实战。涵盖流式批处理、容错机制、实时性分析,以及通过实例演示如何接收Socket数据、实现单词计数、热词统计,整合Flume和Kafka进行实时数据处理。
SparkStreaming流式处理
1、主要内容
- 1、掌握SparkStreaming底层原理
- 2、掌握Dstream常用操作
- 3、掌握SparkStreaming整合flume
- 4、掌握SparkStreaming整合kafka
2、SparkStreaming概述
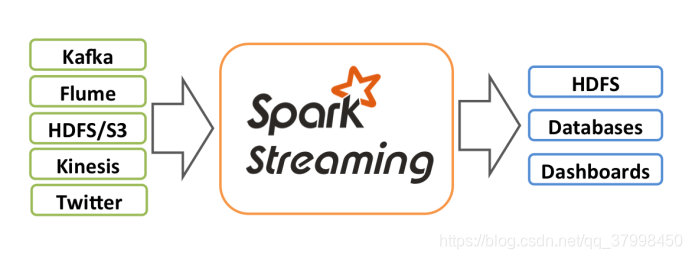
2.1 什么是SparkStreaming
Spark Streaming makes it easy to build scalable fault-tolerant streaming applications.
SparkStreaming是可以非常容易的构建一个可扩展、具有容错机制的流式应用程序。
2.2sparkStreaming特性
- 1、易用性
- 可以像开发离线批处理一样去编写流式处理程序,还可以使用java、scala、Python等不同的语言开发。
- 2、容错性
- sparkStreaming可以实现恰好一次语义(数据被处理且被处理一次)
- sparkStreaming可以实现不需要额外的代码的情况下,来实现丢失的job。
- 3、融合spark生态系统
- sparkStreaming可以和离线批处理和交互式查询相结合
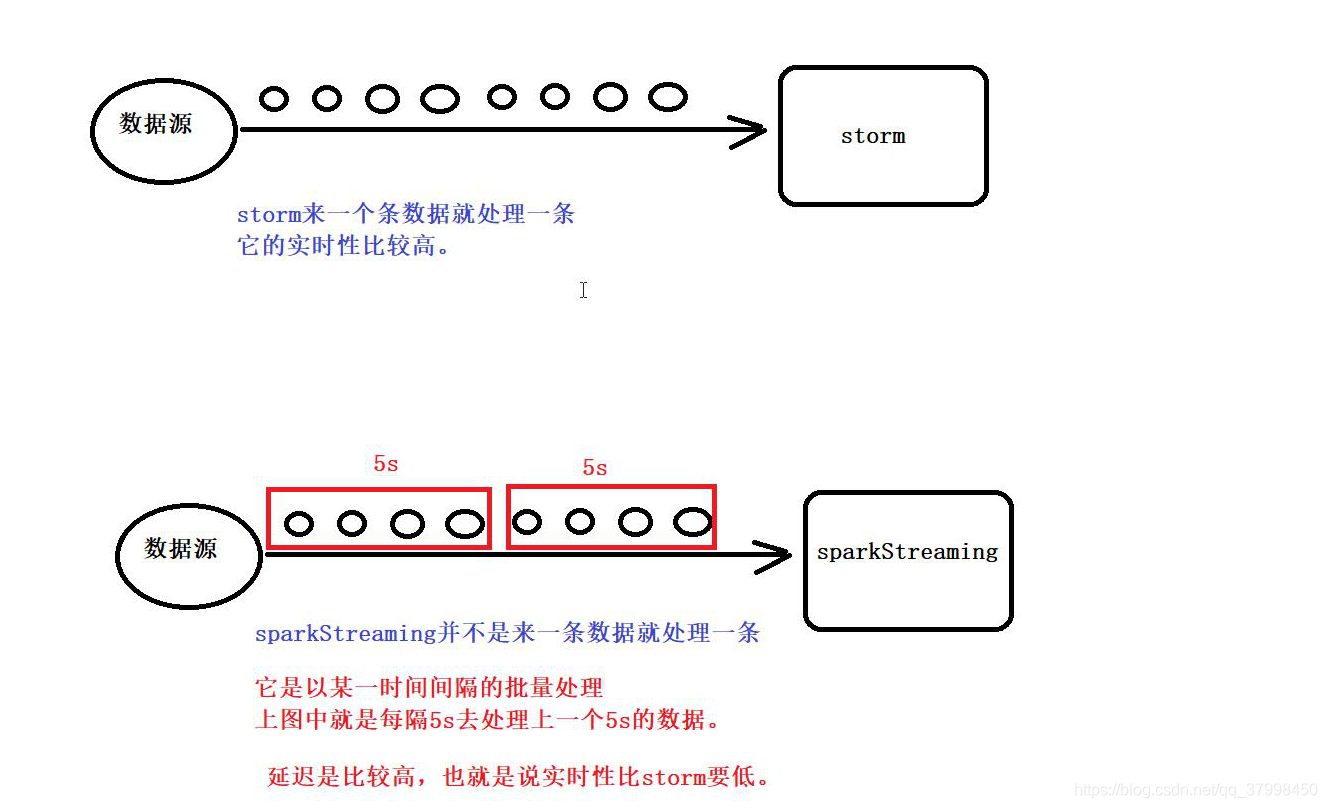
2.3SparkStreaming与Storm的对比
-
SparkStreaming与Storm的区别
- 1.开发语言:
- SparkStreaming :Scala
- Strom:Clojure
- 2.编程模型
- SparkStreaming:DStream
- Strom:Spout/Bolt
- 3.处理数据
- SparkStreaming:它是以某一时间间隔的批量处理。延迟性比较高,也是就说实时性比storm低。
- Storm:来一条数据处理一条数据,实时性比较高。
- 1.开发语言:
3、SparkStreaming原理
3.1SparkStreaming原理
SparkStreaming是基于spark的流式批处理引擎,其基本原理是把输入数据以某一时间间隔批量的处理,当批处理间隔缩短到秒级时,便可以用于处理实时数据流。
3.2SparkStreaming的计算流程
sparkStreaming是以某一时间间隔的批处理,按照批处理的时间间隔进行划分,划分处理很多个短小的批处理作业,每一段数据在这里就是一个Dstream,Dstream内部是由当前该批次的数据,内部的数据是通过rdd进行封装。也就是说Dstream中封装了rdd,rdd里面有很多个分区,分区里面才是真正的数据。
后期Dstream做大量的transformation操作,最终转换成了对他内部的rdd也就是对应的transformation.
3.3sparkStreaming容错性
Dstream中内部封装了rdd,这个时候后期对他做大量操作的时候,如果某个rdd的分区数据丢失了,可以通过rdd的血统进行重新计算恢复得到的。
通过血统在进行重新计算恢复得到丢失的数据的时候需要一定的条件:就是保证数据源端安全性。
sc.textFile("/word.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect
恢复数据:血统+原始的数据
3.4SparkStreaming的实时性
storm是来一条数据处理一条数据,实时性比较高。
sparkstreaming是以某一时间间隔处理,延迟性较高,实时性比较低。
后期处理一些实时的应用的场景:根据具体的业务进行选择是使用storm还是sparkstreaming。高实时的使用storm,要求不是特别的高,可以使用sparkstreaming。
4、DStream
4.1什么是DStream
Discretized Stream是Spark Streaming的基础抽象,代表持续性的数据流和经过各种Spark算子操作后的结果数据流。在内部实现上,DStream是一系列连续的RDD来表示。每个RDD含有一段时间间隔内的数据。
4.2DStream操作分类
- 1、transformation
- 可以把一个Dstream转换生成一个新的Dstream。它是延迟加载,不会立即触发任务的运行。
- 2、outputOperation(输出)
- 它会触发任务的真正运行
- 类似rdd中的action
| Transformation | Meaning |
|---|---|
| map(func) | 对DStream中的各个元素进行func函数操作,然后返回一个新的DStream |
| flatMap(func) | 与map方法类似,只不过各个输入项可以被输出为零个或多个输出项 |
| filter(func) | 过滤出所有函数func返回值为true的DStream元素并返回一个新的DStream |
| repartition(numPartitions) | 增加或减少DStream中的分区数,从而改变DStream的并行度 |
| union(otherStream) | 将源DStream和输入参数为otherDStream的元素合并,并返回一个新的DStream. |
| count() | 通过对DStream中的各个RDD中的元素进行计数,然后返回只有一个元素的RDD构成的DStream |
| reduce(func) | 对源DStream中的各个RDD中的元素利用func进行聚合操作,然后返回只有一个元素的RDD构成的新的DStream. |
| countByValue() | 对于元素类型为K的DStream,返回一个元素为(K,Long)键值对形式的新的DStream,Long对应的值为源DStream中各个RDD的key出现的次数 |
| reduceByKey(func, [numTasks]) | 利用func函数对源DStream中的key进行聚合操作,然后返回新的(K,V)对构成的DStream |
| join(otherStream, [numTasks]) | 输入为(K,V)、(K,W)类型的DStream,返回一个新的(K,(V,W))类型的DStream |
| cogroup(otherStream, [numTasks]) | 输入为(K,V)、(K,W)类型的DStream,返回一个新的 (K, Seq[V], Seq[W]) 元组类型的DStream |
| transform(func) | 通过RDD-to-RDD函数作用于DStream中的各个RDD,可以是任意的RDD操作,从而返回一个新的RDD |
| updateStateByKey(func) | 根据key的之前状态值和key的新值,对key进行更新,返回一个新状态的DStream |
5、DStream实战
5.1SparkStreaming接受socket数据,实现单词wordCount
-
1)安装并启动生产者
在linux服务器上用YU安装nc(即netcat)工具。它是用来设置路由器。我们可以利用它向某个端口发送数据。
yum install -y nc
-
2)通过netcat工具向指定的端口发送数据
nc -lk 9999
-
3)编写Spark Streaming 程序
- 引入依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>2.1.3</version>
</dependency>
- 代码开发(本地运行模式)
package zt.spark.sparkStreaming
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.{SparkConf, SparkContext}
//todo:SparkStreaming接受socket数据,实现单词wordCount
object SparkStreamingScoket {
def main(args: Array[String]): Unit = {
//1.创建sparkConf对象
val sparkConf: SparkConf = new SparkConf().setAppName("SparkStreamingScoket").setMaster("local[2]")
//2.创建sparkContext对象
val sparkContext:SparkContext = new SparkContext(sparkConf)
//设置日志输出级别
sparkContext.setLogLevel("warn")
//3.获取StreamingContext对象,Seconds:表示每批处理的时间间隔
val ssc: StreamingContext = new StreamingContext(sparkContext,Seconds(5))
//4.获取socket数据
val socketText: ReceiverInputDStream[String] = ssc.socketTextStream("node1",9999)
//5.获取每一行的单词
val words: DStream[String] = socketText.flatMap(_.split(" "))
//6.把每一个单词置为1
val wordAndOne: DStream[(String, Int)] = words.map((_,1))
//7.对相同的单词出现的此时进行求和
val result: DStream[(String, Int)] = wordAndOne.reduceByKey(_+_)
//8.打印
result.print()
//9.开启流式处理
ssc.start()
ssc.awaitTermination()
}
}
- 上面的案例中存在的问题:
- 每批次的单词次数都能被正确的统计出来,但是结果不能累加。下面的案例通过updateStateByKey(updatefunc)来更新状态。
5.2sparkStreaming接受socket数据,实现所有批次单词计算结果累加
- 代码开发
package zt.spark.sparkStreaming
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.{SparkConf, SparkContext}
//todo:sparkStreaming接受socket数据,实现所有批次单词计算结果累加
object SparkStreamingSocketTotal {
//这个方法是做统计所有批次的单词统计的计算求和
//currentValues: 表示在当前批次中相同的单词出现的所有的1
//historyValues:表示每一个在之前所有批次中出现的总次数
//Option类型:可以表示可能存在或不存在的值 存在some,不存在none
def updateFunc(currentValues:Seq[Int],historyValues:Option[Int]):Option[Int]={
val newValues= currentValues.sum+historyValues.getOrElse(0)
Some(newValues)
}
def main(args: Array[String]): Unit = {
//1.创建SparkConf对象
val sparkConf: SparkConf = new SparkConf().setAppName("SparkStreamingSocketTotal").setMaster("local[2]")
//2.创建SparkContext对象
val sparkContext: SparkContext = new SparkContext(sparkConf)
//设置日志的输出级别
sparkContext.setLogLevel("warn")
//3.获取StreamingContext对象
val ssc: StreamingContext = new StreamingContext(sparkContext,Seconds(5))
//设置checkpoint的目录 :主要是用于保存之前批次每一个单词出现的次数
ssc.checkpoint("./sockt")
//4.接收socket数据
val socketText: ReceiverInputDStream[String] = ssc.socketTextStream("node1",9999)
//5.获取每一行的单词
val words: DStream[String] = socketText.flatMap(_.split(" "))
//6.为每一个单词置为1
val wordAndOne: DStream[(String, Int)] = words.map((_,1))
//7.统计所有批次的单词的统计值
val result: DStream[(String, Int)] = wordAndOne.updateStateByKey(updateFunc)
//8.打印
result.print()
//9.开启流式处理
ssc.start()
ssc.awaitTermination()
}
}
- 通过函数updateStateByKey实现。根据key的当前值和key的之前批次值,对key进行更新,返回一个新状态的DStream
5.3SparkStreaming开窗函reduceByKeyAndWindow,实现单词计数
- 代码开发
package zt.spark.sparkStreaming
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.{SparkConf, SparkContext}
//todo:SparkStreaming开窗函reduceByKeyAndWindow,实现单词计数
object SparkStreamingScoketWindow {
def main(args: Array[String]): Unit = {
//1.创建SparkConf对象
val sparkConf: SparkConf = new SparkConf().setAppName("SparkStreamingScoketWindow").setMaster("local[2]")
//2.创建SparkContex对象
val sparkContext = new SparkContext(sparkConf)
//设置日志级别
sparkContext.setLogLevel("warn")
//3.获取StreamingContext对象
val ssc = new StreamingContext(sparkContext,Seconds(10))
//4.接收socket的数据
val textStream: ReceiverInputDStream[String] = ssc.socketTextStream("node1",9999)
//5.获取每一行的单词
val words: DStream[String] = textStream.flatMap(_.split(" "))
//6.为每一个单词置为1
val wordAndOne: DStream[(String, Int)] = words.map((_,1))
//7.累加
//reduceByKeyAndWindow:函数参数意义:
//windowDuration:表示window框架的时间长度,
//slidDuration:表示windows滑动的时间长度,即每隔多久执行本计算
val result: DStream[(String, Int)] = wordAndOne.reduceByKeyAndWindow((x:Int,y:Int)=>x+y,Seconds(10),Seconds(10))
//8.打印
result.print()
//9.开启流式处理
ssc.start()
ssc.awaitTermination()
}
}
- reduceByKeyAndWindow(开窗函数)

-
结论:
- 需要保证窗口的长度和窗口的滑动时间间隔相同。
- 需要保证窗口的长度和窗口的滑动时间间隔必须是最小批次时间间隔的整数倍。
5.4SparkStreaming开窗函数统计一定时间内的热门词汇
package zt.spark.sparkStreaming
import org.apache.spark.rdd.RDD
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.{SparkConf, SparkContext}
//todo:SparkStreaming开窗函数统计一定时间内的热门词汇
object SparkStreamingScoketWindowHotWords {
def main(args: Array[String]): Unit = {
//1.创建SparkConf对象
val sparkConf: SparkConf = new SparkConf().setAppName("SparkStreamingScoketWindowHotWords").setMaster("local[2]")
//2.创建SparkContext对象
val sparkContext: SparkContext = new SparkContext(sparkConf)
//设置日志的输出级别
sparkContext.setLogLevel("warn")
//3.获取StreamingContext对象
val ssc: StreamingContext = new StreamingContext(sparkContext,Seconds(5))
//4.获取socket的数据
val socketTextStream: ReceiverInputDStream[String] = ssc.socketTextStream("node1",9999)
//5.获取每一行单词
val words: DStream[String] = socketTextStream.flatMap(_.split(" "))
//6.把每一个单词置为1
val wordAndOne: DStream[(String, Int)] = words.map((_,1))
//7.累加
val result: DStream[(String, Int)] = wordAndOne.reduceByKeyAndWindow((x:Int,y:Int)=>x+y,Seconds(10),Seconds(10))
//8.对上面的结果进行排序
val sortResult: DStream[(String, Int)] = result.transform(rdd => {
val sortByResult: RDD[(String, Int)] = rdd.sortBy(_._2, false)
//获取前3名
val top3: Array[(String, Int)] = sortByResult.take(3)
top3.foreach(println)
sortByResult
})
//9.打印
sortResult.print()
//10.开启流式处理
ssc.start()
ssc.awaitTermination()
}
}
- transform(func)
- 通过RDD-to-RDD函数作用域DStream中的各个RDD,可以是任意的RDD操作,从而返回一个新的RDD。
6、 Spark Streaming整合flume实战
flume作为日志实时采集框架,可以与SparkStreaming实时处理框架进行对接,flume实时采集数据,sparkStreaming做实时处理。
6.1 poll方式
-
准备工作
-
1)安装flume1.6以上
-
2)下载安装包spark-streaming-flume-sink_2.11-2.1.3.jar放入到flume的lib目录下
-
3)修改flume/lib下的scala依赖包版本,从spark安装目录的jars文件夹下找到scala-library-2.11.8.jar 包,替换掉flume的lib目录下自带的scala-library-2.10.1.jar。
-
4)写flume的agent,注意既然是拉取的方式,那么flume向自己所在的机器上产数据就行
-
5)编写flume-poll.conf配置文件(放在flume/conf下即可)
a1.sources = r1 a1.sinks = k1 a1.channels = c1 #source a1.sources.r1.channels = c1 a1.sources.r1.type = spooldir a1.sources.r1.spoolDir = /root/data a1.sources.r1.fileHeader = true #channel a1.channels.c1.type =memory a1.channels.c1.capacity = 20000 a1.channels.c1.transactionCapacity=5000 #sinks a1.sinks.k1.channel = c1 a1.sinks.k1.type = org.apache.spark.streaming.flume.sink.SparkSink a1.sinks.k1.hostname=node1 a1.sinks.k1.port = 8888 a1.sinks.k1.batchSize= 2000 -
6)启动flume
flume-ng agent -n a1 -c /opt/bigdata/flume/conf -f /opt/bigdata/flume/conf/flume-poll.conf -Dflume.root.logger=INFO,console -
7)准备数据
a1.sources.r1.spoolDir = /root/data 在这个文件的准备数据data.txt data.txt //数据 data hive hadoop hive sqoop hadoop hive sqoop kafka flume -
-
代码开发
- 引入依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-flume_2.11</artifactId>
<version>2.1.3</version>
</dependency>
- 代码编写
package zt.spark.flume
import java.net.InetSocketAddress
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.flume.{FlumeUtils, SparkFlumeEvent}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.{SparkConf, SparkContext}
//todo:Spark Streaming整合flume实战 (poll方式)
object SparkStreamingFlumePoll {
def updateFunc(currentValues:Seq[Int],historyValues:Option[Int]):Option[Int]={
val newValues= currentValues.sum+historyValues.getOrElse(0)
Some(newValues)
}
def main(args: Array[String]): Unit = {
//1.创建SparkConf对象
val sparkConf: SparkConf = new SparkConf().setAppName("SparkStreamingFlumePoll").setMaster("local[2]")
//2.创建SparkContext对象
val sparkContext = new SparkContext(sparkConf)
//设置日志级别
sparkContext.setLogLevel("warn")
//3.获取StreamingContext对象
val ssc = new StreamingContext(sparkContext,Seconds(5))
//保存数据
ssc.checkpoint("./flume_poll")
//4.从flume中拉取数据
val pollingStream: ReceiverInputDStream[SparkFlumeEvent] = FlumeUtils.createPollingStream(ssc,"node1",8888)
/**
* 这里是接收多台flume上面的数据
val addresses = List(new InetSocketAddress("node1",8888),new InetSocketAddress("node2",8888),new InetSocketAddress("node3",8888))
val pollingStream1: ReceiverInputDStream[SparkFlumeEvent] = FlumeUtils.createPollingStream(ssc,addresses,StorageLevel.MEMORY_AND_DISK_SER)
*/
//5.获取flume中的body
//flume中数据传输的最小单元是event
val data: DStream[String] = pollingStream.map(x=>new String(x.event.getBody.array()))
//6.获取每一行单词
val words: DStream[String] = data.flatMap(_.split(" "))
//7.为每一个单词置为1
val wordsAndOne: DStream[(String, Int)] = words.map((_,1))
//8.累加
val result: DStream[(String, Int)] = wordsAndOne.updateStateByKey(updateFunc)
//9.打印
result.print()
//10.开启流式处理
ssc.start()
ssc.awaitTermination()
}
}
6.2 push模式
- flume的conf配置文件
#push mode
a1.sources = r1
a1.sinks = k1
a1.channels = c1
#source
a1.sources.r1.channels = c1
a1.sources.r1.type = spooldir
a1.sources.r1.spoolDir = /root/data
a1.sources.r1.fileHeader = true
#channel
a1.channels.c1.type =memory
a1.channels.c1.capacity = 20000
a1.channels.c1.transactionCapacity=5000
#sinks
a1.sinks.k1.channel = c1
a1.sinks.k1.type = avro
#Streaming应用程序所在的主机和端口号
a1.sinks.k1.hostname=192.168.25.33
a1.sinks.k1.port = 8888
a1.sinks.k1.batchSize= 2000
- 代码开发
package zt.spark.flume
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.flume.{FlumeUtils, SparkFlumeEvent}
import zt.spark.flume.SparkStreamingFlumePoll.updateFunc
//todo:Spark Streaming整合flume实战(push方式)
object SparkStreamingFlumePush {
def updateFunc(currentValues:Seq[Int],historyValues:Option[Int]):Option[Int]={
val newValues= currentValues.sum+historyValues.getOrElse(0)
Some(newValues)
}
def main(args: Array[String]): Unit = {
//1.创建SparkConf对象
val sparkConf: SparkConf = new SparkConf().setAppName("SparkStreamingFlumePoll").setMaster("local[2]")
//2.创建SparkContext对象
val sparkContext = new SparkContext(sparkConf)
//设置日志级别
sparkContext.setLogLevel("warn")
//3.获取StreamingContext对象
val ssc = new StreamingContext(sparkContext,Seconds(5))
//保存数据
ssc.checkpoint("./flume_push")
//4.从flume中拉取数据
val pushStream: ReceiverInputDStream[SparkFlumeEvent] = FlumeUtils.createStream(ssc,"192.168.25.33",8888)
//5.获取flume中的body
//flume中数据传输的最小单元是event
val data: DStream[String] = pushStream.map(x=>new String(x.event.getBody.array()))
//6.获取每一行单词
val words: DStream[String] = data.flatMap(_.split(" "))
//7.为每一个单词置为1
val wordsAndOne: DStream[(String, Int)] = words.map((_,1))
//8.累加
val result: DStream[(String, Int)] = wordsAndOne.updateStateByKey(updateFunc)
//9.打印
result.print()
//10.开启流式处理
ssc.start()
ssc.awaitTermination()
}
}
- 启动测试
flume-ng agent -n a1 -c /export/servers/apache-flume-1.6.0-cdh5.14.0-bin/conf/ -f /export/servers/apache-flume-1.6.0-cdh5.14.0-bin/conf/flume-poll.conf -Dflume
注意这里测试时,需要先开启程序的运行,再启动flume。
7、SparkStreaming整合kafka(重点)
kafka作为一个实时的分布式消息队列,实时的生产和消费消息。SparkStreaming实时地读取kafka中的数据,然后进行整合计算。
- 添加依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-8_2.11</artifactId>
<version>2.1.3</version>
</dependency>
7.1 KafkaUtils.createDstream方式
-
准备工作
-
1)启动zookeeper集群
zkServer.sh start -
2)启动kafka集群
kafka-server-start.sh /export/servers/kafka_2.11-1.0.0/config/server.properties -
3)创建topic
kafka-topics.sh --create -zookeeper node1:2181,node2:2181,node3:2181 --replication-factor 1 --partitions 3 --topic kafka_spark -
4)向topic中生产数据
kafka-console-producer.sh --broker-list node1:9092,node2:9092,node3:9092 --topic kafka_spark
-
-
代码开发
package zt.spark.kafka
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.{SparkConf, SparkContext}
import scala.collection.immutable
//todo:7.Spark Streaming整合kafka(基于receiver接收器,使用了kafka高层次消费者api(消息的偏移量由zk去维护))
object SparkStreamingKafkaReceiver {
def main(args: Array[String]): Unit = {
//1.创建SparkConf对象
val sparkConf: SparkConf = new SparkConf().setAppName("SparkStreamingKafkaReceiver").setMaster("local[4]")
.set("spark.streaming.receiver.writeAheadLog.enable","true")
//开启WAL日志:作用:保证数据源端的安全性,后期某些rdd的分区数据丢失了,是可以通过 血统+原始数据 来进行恢复。set("spark.streaming.receiver.writeAheadLog.enable","true")
//2.创建SparkContext对象
val sparkContext = new SparkContext(sparkConf)
//设置日志级别
sparkContext.setLogLevel("warn")
//3.获取StreamingContext对象
val ssc: StreamingContext = new StreamingContext(sparkContext,Seconds(5))
//设置checkpoint目录,用于保存接收到的数据,实际工作中是指向hdfs目录
ssc.checkpoint("./kafka_receiver")
//4.从kafka中获取数据
//指定zk服务地址
val zkQuorum="node1:2181,node2:2181,node3:2181"
//指定消费者组id
val groudId="kafka_receiver"
//指定topic相关信息, key:topic 名称, value:表示一个receiver接收器使用多少个线程消费topic数据
val topics=Map("kafka_spark"->1)
//(String,String):第一个String是消息的key,第二个String就是消息的vlaue
//构建了3个receiver接收器去接收数据,加快数据的接收速度
val kafkaDstreamList: immutable.IndexedSeq[ReceiverInputDStream[(String, String)]] = (1 to 3).map(x => {
val kafkaStream: ReceiverInputDStream[(String, String)] = KafkaUtils.createStream(ssc, zkQuorum, groudId, topics)
kafkaStream
})
//ssc.union方法,把把多个receiver接收器产生的DStream汇总成为一个Dstream
val totalkafkaDstream: DStream[(String, String)] = ssc.union(kafkaDstreamList)
//5.获取真正的数据 即totalkafkaDstream中的消息的value
val data: DStream[String] = totalkafkaDstream.map(_._2)
//6.获取每一行的单词
val words: DStream[String] = data.flatMap(_.split(" "))
//7.为每一个单词置为1
val wordAndOne: DStream[(String, Int)] = words.map((_,1))
//8.累计求和
val result: DStream[(String, Int)] = wordAndOne.reduceByKey(_+_)
//9.打印
result.print()
//10.开启流式处理
ssc.start()
ssc.awaitTermination()
}
}
- 总结
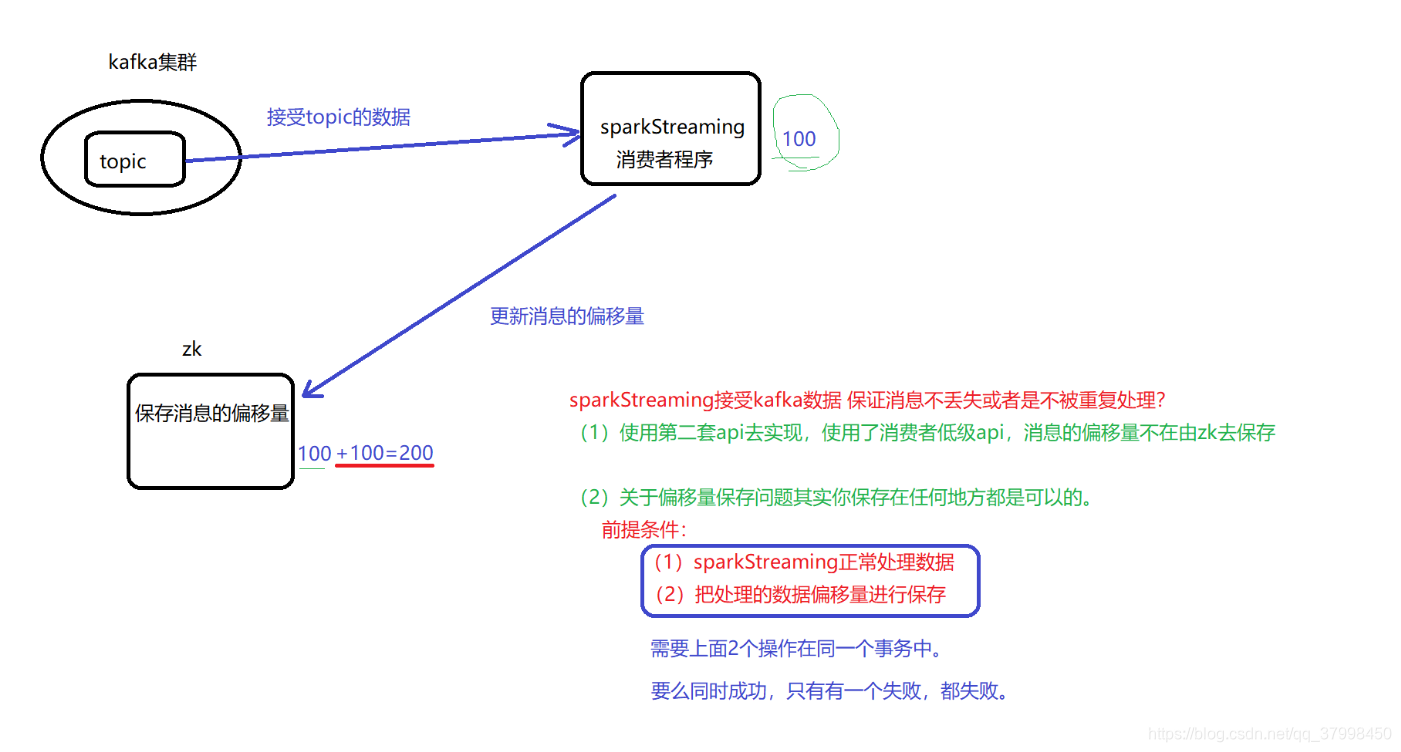
第一种方式是使用了receiver接受器去接受数据,后期可以使用多个receiver接受器来加快接受数据的速度,使用了kafka高层次的消费者api,就是消息的偏移量是有zk去维护的。
默认会出现数据的丢失,可以启动WAL日志将接受到的数据同步写到分布式文件系统hdfs上,保证数据源端它的安全性,后面就是可以使用血统+原始数据,来重新计算恢复得到丢失的数据。
开启WAL日志:
set("spark.streaming.receiver.writeAheadLog.enable","true")
需要设置数据保存目录:
ssc.checkpoint("目录")
这种方式可以解决数据不丢失的问题,但是它解决不了数据被处理且只被处理一次。在这里由于更新偏移量offSet到zk没有成功,导致数据正常消费成功了,没有把这个消费的表示记录下来,最后导致数据的重复消费。因此建议使用第二种方式kafkaUtis的createDirectStream()方式。
- kafka重复消费&解决办法
7.2 KafkaUtils.createDirectStream方式
- 代码开发
package zt.spark.kafka
import kafka.serializer.StringDecoder
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.dstream.{DStream, InputDStream, ReceiverInputDStream}
import org.apache.spark.streaming.kafka.KafkaUtils
//todo:sparkStreaming整合kafka :使用消费者低级api(消息的偏移量不在由zk去维护,由客户端程序自己去维护)
object SparkStreamingKafkaDirect {
def main(args: Array[String]): Unit = {
//1.创建SparkConf对象
val sparkConf: SparkConf = new SparkConf().setAppName("SparkStreamingKafkaDirect").setMaster("local[4]")
//2.创建SparkContext对象
val sparkContext = new SparkContext(sparkConf)
//设置日志级别
sparkContext.setLogLevel("warn")
//3.获取StreamingContext对象
val ssc: StreamingContext = new StreamingContext(sparkContext,Seconds(5))
//设置checkpoint目录,用于保存接收到的数据,实际工作中是指向hdfs目录
ssc.checkpoint("./kafka_direct")
//4.接受kafka中的数据
val kafkaParams=Map("bootstrap.servers"->"node1:9092,node2:9092,node3:9092","group.id"->"spark-direct")
val topics=Set("kafka_spark")
//通过下面这种方式获取得到Dstream它内部的rdd分区数跟kafka中的topic的分区数相等
val directStream: InputDStream[(String, String)] = KafkaUtils.createDirectStream[String,String,StringDecoder,StringDecoder](ssc,kafkaParams,topics)
//5.获取真正的数据 即totalkafkaDstream中的消息的value
val data: DStream[String] = directStream.map(_._2)
//6.获取每一行的单词
val words: DStream[String] = data.flatMap(_.split(" "))
//7.为每一个单词置为1
val wordAndOne: DStream[(String, Int)] = words.map((_,1))
//8.累计求和
val result: DStream[(String, Int)] = wordAndOne.reduceByKey(_+_)
//9.打印
result.print()
//10.开启流式处理
ssc.start()
ssc.awaitTermination()
}
}
7.3 把第二种方式打成jar包放在集群上去运行
spark-submit --master spark://node1:7077 --class cn.itcast.kafka.SparkStreamingKafkaDirect --executor-memory 1g --total-executor-cores 2 spark_class12-1.0-SNAPSHOT.jar
对于实时处理来说什么情况下是比较理想的状态? 在当前批次时间内就把上一个批次的数据处理完成。
每隔10s去处理上一个10s的数据
第一个10s的数据 -------------------------------------> 1分钟
第二个10s的数据 -------------------------------------> 1分钟
第三个10s的数据 -------------------------------------> 1分钟
.....
后面来的批次数据,一直会等待,会出现数据积压。
在企业中,我们正常通过本地开发代码程序,可以通过指定master为local,先本地测试,测试后数据没问题,可以把程序打成jar提交到集群中运行。
访问:master主机名:8080
可以先来一些资源参数进行测试:
--executor-memory 5g --total-executor-cores 10
--executor-memory 5g --total-executor-cores 20
--executor-memory 10g --total-executor-cores 20
--executor-memory 10g --total-executor-cores 30

















 1784
1784

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









