







 本文介绍了如何使用Bagging方法和随机森林提高预测准确性。通过在Python中实现Bagging过程及决策树算法,展示了如何通过集成多个弱分类器来创建一个强大的分类模型。
本文介绍了如何使用Bagging方法和随机森林提高预测准确性。通过在Python中实现Bagging过程及决策树算法,展示了如何通过集成多个弱分类器来创建一个强大的分类模型。
概述
把各种model综合起来——让预测更准确、更加稳定(做平均)
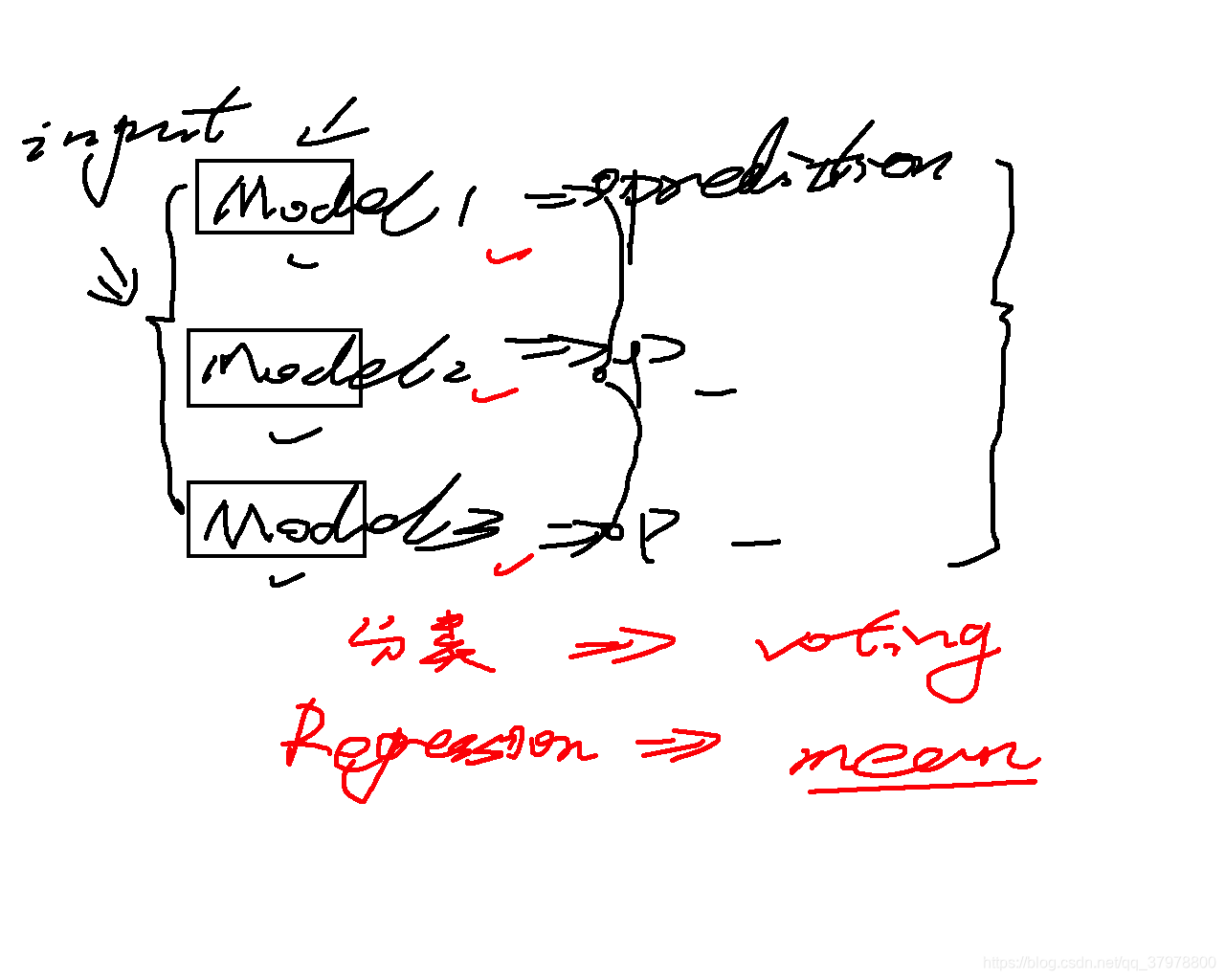
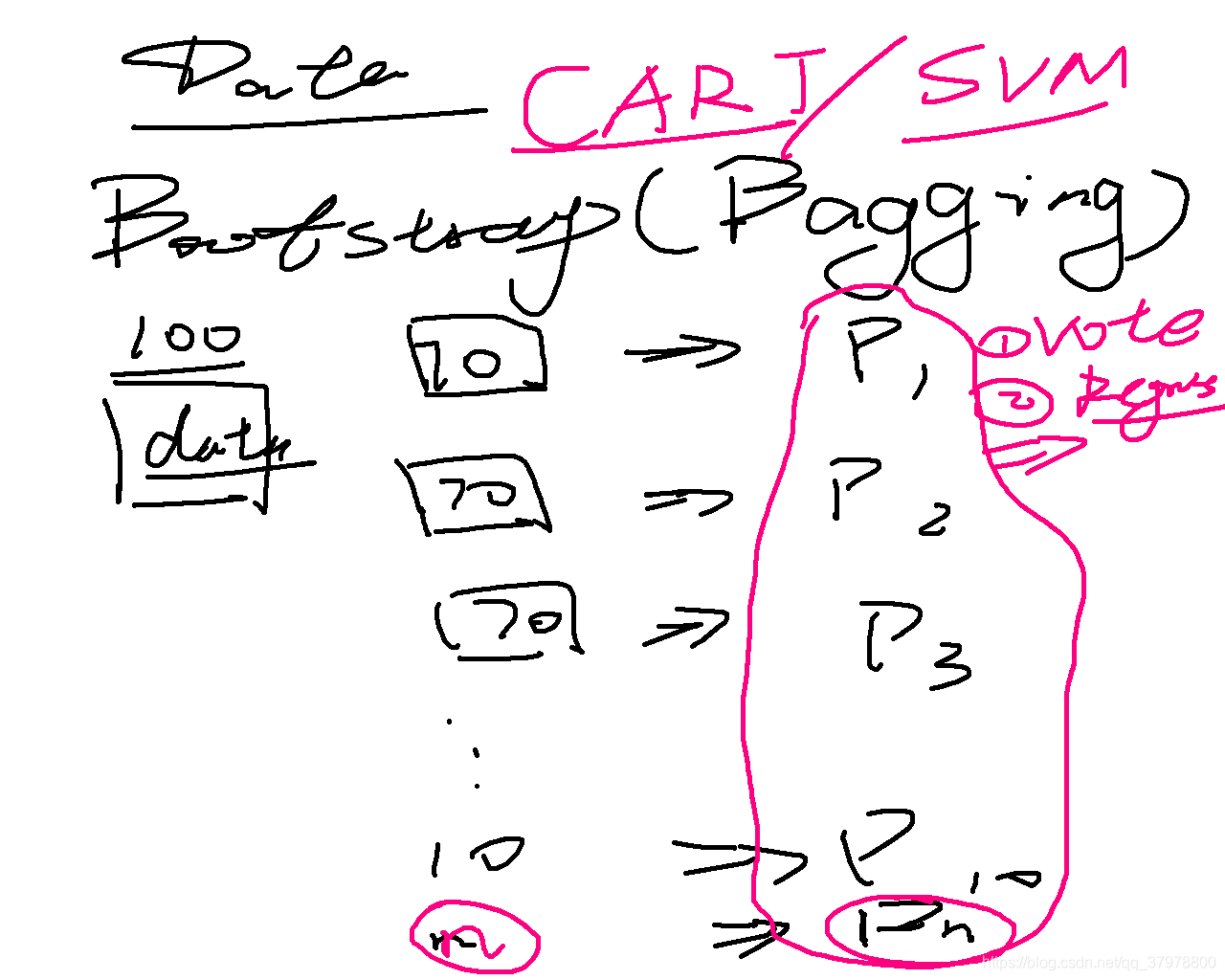

在随机森林里面的超参数(hyper-parameter):
1.对于每一棵树,要选取特性(features),假设总共有n个feature,你需要确定选取个m作为参数
2.每一个node的最低size(每个棵树的每一片叶子的最小值)
3.每一个树的深度(maximum depth of one tree) 4.选择森林里面有多少棵树
一、bagging
from random import seed
from random import randrange
from random import random
def subsample(dataset, ratio=1.0):
sample = list()
n_sample = round(len(dataset) * ratio)
while len(sample) < n_sample:
index = randrange(len(dataset))
sample.append(dataset[index])
return sample
def mean(numbers):
result = sum(numbers) / float(len(numbers))
return result
seed(1)
dataset = [[randrange(10)] for i in range(20)]
# print(dataset)
ratio = 0.10
for size in [1, 10, 100,1000,10000,100000,1000000]:
sample_means = list()
for i in range(size):
sample = subsample(dataset, ratio)
sample_mean = mean([row[0] for row in sample])
sample_means.append(sample_mean)
print("When sample is [%d],the estimated mean is [%.3f]" % (size, mean(sample_means)))
print("The real mean of our dataset is [%.3f]" % mean([row[0] for row in dataset]))

代码

from random import seed
from random import randrange
from random import random
from csv import reader
# 1.load our data
def load_csv(filename):
dataset = list()
with open(filename, 'r') as file:
csv_reader = reader(file)
for row in csv_reader:
if not row:
continue
dataset.append(row)
return dataset
dataset = load_csv('sonar.all-data.csv')
# print(dataset)
# 2.datatype conversion
def str_to_float(dataset, column):
for row in dataset:
row[column] = float(row[column].strip())
def str_to_int(dataset, column):
class_value = [row[column] for row in dataset]
unique = set(class_value)
look_up = dict()
for i, value in enumerate(unique):
look_up[value] = i
for row in dataset:
row[column] = look_up[row[column]]
return look_up
# 3.k_fold cross validation
def cross_validation_split(dataset, n_folds):
dataset_split = list()
dataset_copy = list(dataset)
fold_size = int(len(dataset) / n_folds)
for i in range(n_folds):
fold = list()
while len(fold) < fold_size:
index = randrange(len(dataset_copy))
fold.append(dataset_copy.pop(index))
dataset_split.append(fold)
return dataset_split
# 4.calculate model accuracy
def calculate_accuracy(actual, predicted):
correct = 0
for i in range(len(actual)):
if actual[i] == predicted[i]:
correct += 1
return correct / float(len(actual)) * 100.0
# 5.how good is our algo
def evaluate_our_algo(dataset, algo, n_folds, *args):
folds = cross_validation_split(dataset, n_folds)
scores = list()
for fold in folds:
train_set = list(folds)
train_set.remove(fold)
train_set = sum(train_set, [])
test_set = list()
for row in fold:
row_copy = list(row)
test_set.append(row_copy)
row_copy[-1] = None
predicted = algo(train_set, test_set, *args)
actual = [row[-1] for row in fold]
accuracy = calculate_accuracy(actual, predicted)
scores.append(accuracy)
return scores
# 6.left and right split
def test_split(index, value, dataset):
left, right = list(), list()
for row in dataset:
if row[index] < value:
left.append(row)
else:
right.append(row)
return left, right
# 7.calculate gini index
def gini_index(groups, classes):
n_instances = float(sum([len(group) for group in groups]))
gini = 0.0
for group in groups:
size = float(len(group))
if size == 0:
continue
score = 0.0
for class_val in classes:
p = [row[-1] for row in group].count(class_val) / size
score += p * p
gini += (1 - score) * (size / n_instances)
return gini
# 8.calculate the best split
def get_split(dataset):
class_values = list(set(row[-1] for row in dataset))
posi_index, posi_value, posi_score, posi_groups = 888, 888, 888, None
for index in range(len(dataset[0])- 1):
for row in dataset:
groups = test_split(index, row[index], dataset)
gini = gini_index(groups, class_values)
if gini < posi_score:
posi_index, posi_value, posi_score, posi_groups = index, row[index], gini, groups
return {'index': posi_index, 'value': posi_value, 'groups': posi_groups}
# 9. to terminal
def determine_the_terminal(group):
outcomes = [row[-1] for row in group]
return max(set(outcomes), key=outcomes.count)
# 10.
# 1.split our data into left and right
# 2.delete the original data
# 3.check if the data is none/max depth/min size
# 4.to terminal
def split(node, max_depth, min_size, depth):
left, right = node['groups']
del (node['groups'])
if not left or not right:
node['left'] = node['right'] = determine_the_terminal(left + right)
return
if depth >= max_depth:
node['left'], node['right'] = determine_the_terminal(left), determine_the_terminal(right)
if len(left) <= min_size:
node['left'] = determine_the_terminal(left)
else:
node['left'] = get_split(left)
split(node['left'], max_depth, min_size, depth + 1)
if len(right) <= min_size:
node['right'] = determine_the_terminal(right)
else:
node['right'] = get_split(right)
split(node['right'], max_depth, min_size, depth + 1)
# 11.make our decision tree
def build_tree(train, max_depth, min_zise):
root = get_split(train)
split(root, max_depth, min_zise, 1)
return root
# 12.make prediction
def predict(node, row):
if row[node['index']] < node['value']:
if isinstance(node['left'], dict):
return predict(node['left'], row)
else:
return node['left']
else:
if isinstance(node['right'], dict):
return predict(node['right'], row)
else:
return node['right']
# 13. subsample
def subsample(dataset, ratio):
sample = list()
n_sample = round(len(dataset) * ratio)
while len(sample) < n_sample:
index = randrange(len(dataset))
sample.append(dataset[index])
return sample
# 14.make prediction using bagging
def bagging_predict(trees, row):
predictions = [predict(tree, row) for tree in trees]
return max(set(predictions), key=predictions.count)
# 15.bagging
def bagging(train, test, max_depth, min_size, sample_size, n_trees):
trees = list()
for i in range(n_trees):
sample = subsample(train, sample_size)
tree = build_tree(sample, max_depth, min_size)
trees.append(tree)
predictions = [bagging_predict(trees, row) for row in test]
return (predictions)
seed(1)
dataset = load_csv('sonar.all-data.csv')
for i in range(len(dataset[0]) - 1):
str_to_float(dataset, i)
str_to_int(dataset, len(dataset[0]) - 1)
n_folds = 5
max_depth = 6
min_size = 2
sample_size = 0.5
for n_trees in [1, 5, 10, 50]:
scores = evaluate_our_algo(dataset, bagging, n_folds, max_depth, min_size, sample_size, n_trees)
print('We are using [%d]' % n_trees)
print('The scores are : [%s]' % scores)
print('The mean accuracy is [%.3f]' % (sum(scores) / float(len(scores))))




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









