







 本文详细介绍了数据结构中的堆,包括最大堆和最小堆的概念、性质,以及如何通过shiftUp和shiftDown操作维护堆的特性。此外,还探讨了如何通过heapify快速构建堆,原地堆排序的实现,以及优先队列的应用。堆在优先级队列、排序和查找等场景中具有高效性。
本文详细介绍了数据结构中的堆,包括最大堆和最小堆的概念、性质,以及如何通过shiftUp和shiftDown操作维护堆的特性。此外,还探讨了如何通过heapify快速构建堆,原地堆排序的实现,以及优先队列的应用。堆在优先级队列、排序和查找等场景中具有高效性。
堆简介
一. 概念及其介绍
堆(Heap)是计算机科学中一类特殊的数据结构的统称。
堆通常是一个可以被看做一棵完全二叉树的数组对象。
二. 性质:
- 堆中某个节点的值总是不大于或不小于其父节点的值。
- 堆总是一棵完全二叉树。
三. 最大堆和最小堆
四. 事先说明
- 除特殊说明外,以下代码均以最大堆为例
- 以下实现堆,均通过普通数组存储。
- 假设堆的容积为n,即数组长度为n
- 如果当前结点的索引为i,其中i∈[0, n),则当前结点如果有左右子结点,左子结点的索引为2*i+1,右子结点的索引为2*i+1
- i为Java代码的int类型
- 二叉堆的(完全二叉树的)最后一层为叶子节点,则倒数第二层中(堆中)最后一个非叶子结点的索引为: i = [(n - 1) -1] / 2 <== 2 * i + 1 = n - 1 && 最后一个结点是不是右结点无所谓,经过验证了。
五. 堆的shift up(上浮)
当向一个(最大/最小)堆中添加元素时,为了保持(最大/最小)堆的特性,称为 shift up。
目的:向堆中添加元素。
- 将新添加的元素添加到最后一层的末尾(从左向右添加);
- 通过与父节点进行比较是否进行上浮
/**
* @author wkn
* @create 2021-11-21 17:02
*/
public class HeapStructure {
public static void main(String[] args) {
Heap heap = new Heap(11);
heap.insert(16);
heap.insert(15);
heap.insert(17);
heap.insert(19);
heap.insert(13);
heap.insert(22);
heap.insert(28);
heap.insert(30);
heap.insert(41);
heap.insert(62);
heap.insert(52);
heap.show();
}
}
/**
* 构建最大堆
*/
class Heap{
private int capacity;//堆的容积
private int count;//当前堆中元素的数量 = count + 1
private int[] data;
public Heap(int capacity){ //用于一个一个元素添加去构建堆
this.capacity = capacity;
data = new int[capacity];
count = -1;
}
public Heap(int[] arr){ //用于直接将所有元素一次性构建为堆
data = arr;
}
// 返回堆中的元素个数
public int size(){
return count + 1;
}
// 返回一个布尔值, 表示堆中是否为空
public boolean isEmpty(){
return count == -1;
}
public void show(){
for (int val : data) {
System.out.println(val);
}
}
/**
* 交换堆中索引为i和j的两个元素
* @param i
* @param j
*/
public void swap(int i, int j){
int temp = data[i];
data[i] = data[j];
data[j] = temp;
}
/**
* 用于一个一个插入元素
* @param chiledIndex 最后插入的元素编号, 其父节点编号为[(k-1)/2]
*/
public void shiftUp(int chiledIndex){
//当chiledIntex结点有父节点时,才判断是否满足最大堆的要求,并找到正确的chiledIndex插入位置
int temp = data[chiledIndex];
while(chiledIndex > 0 && data[(chiledIndex - 1) / 2] < temp){
data[chiledIndex] = data[(chiledIndex - 1) / 2];
chiledIndex = (chiledIndex - 1) / 2;
}
data[chiledIndex] = temp;
}
public void insert(int element){
if(count < capacity){ //判断堆是否已经满了
count++;
data[count] = element;
shiftUp(count);
}else{
throw new RuntimeException("最大堆已满!");
}
}
}六. 堆的shift down(下沉)
/**
* @author wkn
* @create 2021-11-21 17:02
*/
public class HeapStructure {
public static void main(String[] args) {
Heap heap = new Heap(11);
heap.insert(16);
heap.insert(15);
heap.insert(17);
heap.insert(19);
heap.insert(13);
heap.insert(22);
heap.insert(28);
heap.insert(30);
heap.insert(41);
heap.insert(62);
heap.insert(52);
heap.show();
System.out.println("***************");
int root = heap.extractRoot();
System.out.println("根节点是:"+ root);
heap.show();
}
}
/**
* 构建最大堆
*/
class Heap{
private int capacity;//堆的容积
private int count;//当前堆中元素的数量 = count + 1
private int[] data;
public Heap(int capacity){ //用于一个一个元素添加去构建堆
this.capacity = capacity;
data = new int[capacity];
count = -1;
}
public Heap(int[] arr){ //用于直接将所有元素一次性构建为堆
data = arr;
}
// 返回堆中的元素个数
public int size(){
return count + 1;
}
// 返回一个布尔值, 表示堆中是否为空
public boolean isEmpty(){
return count == -1;
}
public void show(){
for (int i = 0; i <= count; i++) {
System.out.println(data[i]);
}
}
/**
* 交换堆中索引为i和j的两个元素
* @param i
* @param j
*/
public void swap(int i, int j){
int temp = data[i];
data[i] = data[j];
data[j] = temp;
}
/**
* 用于一个一个插入元素
* @param chiledIndex 最后插入的元素编号, 其父节点编号为[(k-1)/2]
*/
public void shiftUp(int chiledIndex){
//当chiledIntex结点有父节点时,才判断是否满足最大堆的要求,并找到正确的chiledIndex插入位置
int temp = data[chiledIndex];
while(chiledIndex > 0 && data[(chiledIndex - 1) / 2] < temp){
data[chiledIndex] = data[(chiledIndex - 1) / 2];
chiledIndex = (chiledIndex - 1) / 2;
}
data[chiledIndex] = temp;
}
public void insert(int element){
if(count < capacity){ //判断堆是否已经满了
count++;
data[count] = element;
shiftUp(count);
}else{
throw new RuntimeException("最大堆已满!");
}
}
public int extractRoot(){//抽取最大堆的根节点即最大值
if(count >= 0){
int root = data[0];
swap(0, count);
count--;
shiftDown(0);
return root;
}else{
throw new RuntimeException("当前最大堆为空!");
}
}
/**
* 从根节点开始,一共可以下沉(2*rootIndex + 1) <= count层
* @param rootIndex
*/
public void shiftDown(int rootIndex){
int temp = data[rootIndex];
/*System.out.println(temp);
System.out.println(data[count]);
System.out.println(data[count+1]);*/
while((2*rootIndex + 1) <= count){
//找到data[rootIndex]的最大子节点的索引位置
int childIndex = 2*rootIndex + 1;//初始化为data[rootIndex]的左结点索引 <== 插入的位置不能超过count
if(2 * rootIndex + 2 <= count){
childIndex = data[2 * rootIndex + 1] > data[2 * rootIndex + 2] ? 2 * rootIndex + 1 : 2 * rootIndex + 2;
}
if(temp >= data[childIndex]){
break;//找到了插入的位置
}
data[rootIndex] = data[childIndex];
rootIndex = childIndex;
}
data[rootIndex] = temp;
}
}七. 普通数组的heapify(堆化)
完全二叉树有一个重要性质:
假设一共有n个结点,当前结点的编号为i(i∈0, 1, 2.....,n - 1)
- 若当前结点有左右子节点,则左节点的编号为(2 * i + 1),右节点的编号为(2 * i + 2)。
- 最后一个非叶子结点的编号为:[(n-1) - 1] / 2
/**
* @author wukangning
* @create 2021-11-21 17:02
*/
public class HeapStructure {
public static void main(String[] args) {
Heap heap = new Heap(11);
heap.insert(16);
heap.insert(15);
heap.insert(17);
heap.insert(19);
heap.insert(13);
heap.insert(22);
heap.insert(28);
heap.insert(30);
heap.insert(41);
heap.insert(62);
heap.insert(52);
heap.show();
System.out.println("***************");
int root = heap.extractRoot();
System.out.println("根节点是:"+ root);
heap.show();
System.out.println("***************");
Heap heap2 = new Heap(new int[]{1, 2, 3, 4, 5, 6, 7, 8});
heap2.show();
}
}
/**
* 构建最大堆
*/
class Heap{
private int capacity;//堆的容积
private int count;//当前堆中元素的数量 = count + 1
private int[] data;
public Heap(int capacity){ //用于一个一个元素添加去构建堆
this.capacity = capacity;
data = new int[capacity];
count = -1;
}
public Heap(int[] arr){ //用于直接将所有元素一次性构建为堆
data = arr;
this.count = arr.length - 1;
this.capacity = arr.length;
heapify();
}
// 返回堆中的元素个数
public int size(){
return count + 1;
}
// 返回一个布尔值, 表示堆中是否为空
public boolean isEmpty(){
return count == -1;
}
public void show(){
for (int i = 0; i <= count; i++) {
System.out.println(data[i]);
}
}
/**
* 交换堆中索引为i和j的两个元素
* @param i
* @param j
*/
public void swap(int i, int j){
int temp = data[i];
data[i] = data[j];
data[j] = temp;
}
/**
* 用于一个一个插入元素
* @param chiledIndex 最后插入的元素编号, 其父节点编号为[(k-1)/2]
*/
public void shiftUp(int chiledIndex){
//当chiledIntex结点有父节点时,才判断是否满足最大堆的要求,并找到正确的chiledIndex插入位置
int temp = data[chiledIndex];
while(chiledIndex > 0 && data[(chiledIndex - 1) / 2] < temp){
data[chiledIndex] = data[(chiledIndex - 1) / 2];
chiledIndex = (chiledIndex - 1) / 2;
}
data[chiledIndex] = temp;
}
public void insert(int element){
if(count < capacity){ //判断堆是否已经满了
count++;
data[count] = element;
shiftUp(count);
}else{
throw new RuntimeException("最大堆已满!");
}
}
public int extractRoot(){//抽取最大堆的根节点即最大值
if(count >= 0){
int root = data[0];
swap(0, count);
count--;
shiftDown(0);
return root;
}else{
throw new RuntimeException("当前最大堆为空!");
}
}
/**
* 从根节点开始,一共可以下沉(2*rootIndex + 1) <= count层
* @param rootIndex
*/
public void shiftDown(int rootIndex){
int temp = data[rootIndex];
/*System.out.println(temp);
System.out.println(data[count]);
System.out.println(data[count+1]);*/
while((2 * rootIndex + 1) <= count){
//找到data[rootIndex]的最大子节点的索引位置
int childIndex = 2*rootIndex + 1;//初始化为data[rootIndex]的左结点索引 <== 插入的位置不能超过count
if(2 * rootIndex + 2 <= count){
childIndex = data[2 * rootIndex + 1] > data[2 * rootIndex + 2] ? 2 * rootIndex + 1 : 2 * rootIndex + 2;
}
if(temp >= data[childIndex]){
break;
}
data[rootIndex] = data[childIndex];
rootIndex = childIndex;
}
data[rootIndex] = temp;
}
public void heapify(){
for(int i = (count - 1) / 2; i >= 0; i--){
shiftDown(i);
}
}
}通过headify(堆化)可以将普通的数据建成最大堆,从而可以获得数组的最大值。
假设数组的长度为n,则通过n次提取最大堆的根节点可以进行排序(普通堆排序):添加额外的空间存储每次抽取出的根节点,就可以实现降序排序。(就不写代码了,很简单,定义一个额外的数组来存储每次提取的最大值)。
八. 原地堆排序
- 对于最大堆,原地堆排序实现的是升序。
- 对于最小堆,原地排序实现的是降序。
/**
* 原地堆排序(基础堆排序的优化,不需要占用额外的存储空间)
* @author wukangning
* @create 2021-11-21 21:31
*/
public class HeapSort {
public static void main(String[] args){
int[] data = new int[]{5,4,3,2,1,0};
heapAscSort(data);//升序排序
show(data);
System.out.println("*******************");
heapDescSort(data);//降序排序
show(data);
}
public static void show(int[] data){
for (int val : data) {
System.out.print(val + " ");
}
}
/**
* 实现arr数组的升序排序
* @param data
*/
public static void heapAscSort(int[] data){
int length = data.length;
maxHeadify(data, 0, length - 1);
//show(data);
for(int i = length - 1; i > 0; i--){
swap(data, 0, i);
minShiftDown(data, 0, 0, i - 1);
}
}
/**
* 实现arr数组的降序排序
* @param data
*/
public static void heapDescSort(int[] data){
int length = data.length;
minHeadify(data, 0, length - 1);
//show(data);
for(int i = length - 1; i > 0; i--){
swap(data, 0, i);
maxShiftDown(data, 0, 0, i - 1);
}
}
/**
* 建立最大堆
* @param data
*/
public static void maxHeadify(int[] data, int start, int end){
int length = end - start + 1;
int lastNoLeafNodeIndex = (length / 2) -1;
for(int i = lastNoLeafNodeIndex; i >= 0; i--){
minShiftDown(data, i, start, end);
}
}
/**
* 建立最小堆
* @param data
*/
public static void minHeadify(int[] data, int start, int end){
int length = end - start + 1;
int lastNoLeafNodeIndex = (length / 2) -1;
for(int i = lastNoLeafNodeIndex; i >= 0; i--){
maxShiftDown(data, i, start, end);
}
}
/**
* 为了提取根节点后还原正确的最大堆:越小的值越下沉
* @param rootIndex
*/
public static void minShiftDown(int[] data, int rootIndex, int start, int end){
int temp = data[rootIndex];
int length = end - start + 1;
while(2 * rootIndex + 1 <= length - 1){
int childIndex = 2 * rootIndex + 1;
if(2 * rootIndex + 2 <= length - 1){
childIndex = data[childIndex] >= data[2 * rootIndex + 2] ? childIndex : 2 * rootIndex + 2;
}
if(temp >= data[childIndex]){
break;
}
data[rootIndex] = data[childIndex];
rootIndex = childIndex;
}
data[rootIndex] = temp;
}
/**
* 为了提取根节点后还原正确的最小堆:越大的值越下沉
* @param rootIndex
*/
public static void maxShiftDown(int[] data, int rootIndex, int start, int end){
int temp = data[rootIndex];
int length = end - start + 1;
while(2 * rootIndex + 1 <= length - 1){
int childIndex = 2 * rootIndex + 1;
if(2 * rootIndex + 2 <= length - 1){//如果有右节点
childIndex = data[childIndex] <= data[2 * rootIndex + 2] ? childIndex : 2 * rootIndex + 2;
}
if(temp <= data[childIndex]){
break;
}
data[rootIndex] = data[childIndex];
rootIndex = childIndex;
}
data[rootIndex] = temp;
}
public static void swap(int[] data, int i , int j){
int temp = data[i];
data[i] = data[j];
data[j] = temp;
}
}注:
- 实现最大堆和实现最小堆只是在shift down部分让谁下沉变了,最大堆是让小的temp下沉,最小堆是让大的temp下沉。
- 通过代码实现可以看出,没有占用额外的存储空间。
九. 练习题
class Solution {
public int findKthLargest(int[] nums, int k) {
heapDescSort(nums);
return nums[k-1];
}
/**
* 实现arr数组的降序排序
* @param data
*/
public static void heapDescSort(int[] data){
int length = data.length;
minHeadify(data, 0, length - 1);
//show(data);
for(int i = length - 1; i > 0; i--){
swap(data, 0, i);
maxShiftDown(data, 0, 0, i - 1);
}
}
/**
* 建立最小堆
* @param data
*/
public static void minHeadify(int[] data, int start, int end){
int length = end - start + 1;
int lastNoLeafNodeIndex = (length / 2) -1;
for(int i = lastNoLeafNodeIndex; i >= 0; i--){
maxShiftDown(data, i, start, end);
}
}
/**
* 为了提取根节点后还原正确的最小堆:越大的值越下沉
* @param rootIndex
*/
public static void maxShiftDown(int[] data, int rootIndex, int start, int end){
int temp = data[rootIndex];
int length = end - start + 1;
while(2 * rootIndex + 1 <= length - 1){
int childIndex = 2 * rootIndex + 1;
if(2 * rootIndex + 2 <= length - 1){//如果有右节点
childIndex = data[childIndex] <= data[2 * rootIndex + 2] ? childIndex : 2 * rootIndex + 2;
}
if(temp <= data[childIndex]){
break;
}
data[rootIndex] = data[childIndex];
rootIndex = childIndex;
}
data[rootIndex] = temp;
}
public static void swap(int[] data, int i , int j){
int temp = data[i];
data[i] = data[j];
data[j] = temp;
}
}执行用时:3 ms, 在所有 Java 提交中击败了58.59%的用户
内存消耗:38.6 MB, 在所有 Java 提交中击败了81.29%的用户
通过测试用例:32 / 32
十. 优先队列
普通队列的特性:FIFO(先进先出)
优先队列:
-
最大优先队列,无论入队顺序,当前最大的元素优先出队。
-
最小优先队列,无论入队顺序,当前最小的元素优先出队。
比如有一个最大优先队列,它的最大元素是8,那么虽然元素8并不是队首元素,但出队的时候仍然让元素8首先出队:
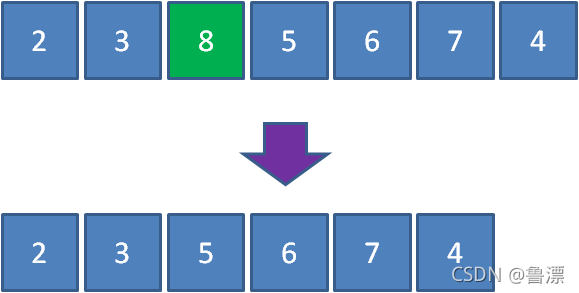
要满足以上需求,利用线性数据结构并非不能实现,但是时间复杂度较高,最坏时间复杂度O(n)查找+移动,并不是最理想的方式。
使用二叉堆:
-
最大堆的堆顶是整个堆中的最大元素
-
最小堆的堆顶是整个堆中的最小元素
因此,我们可以用最大堆来实现最大优先队列,每一次入队操作就是堆的插入操作(shift up操作),每一次出队操作就是删除堆顶节点(shift down操作)。二叉堆结点的上浮和下沉的时间复杂度都是logn,所以优先队列入队和出队的时间复杂度也是logn。
代码中采用数组来存储二叉堆的元素,因此当元素超过数组范围的时候,需要进行resize来扩大数组长度。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









