




 该文展示了如何使用Python的pandas库创建DataFrame对象,包括初始化、数据查询以及Series的使用。通过示例代码,演示了DataFrame的索引选择,行遍历,以及如何将数据转置。同时,文章还提到了DataFrame与Series之间的转换操作。
该文展示了如何使用Python的pandas库创建DataFrame对象,包括初始化、数据查询以及Series的使用。通过示例代码,演示了DataFrame的索引选择,行遍历,以及如何将数据转置。同时,文章还提到了DataFrame与Series之间的转换操作。
import numpy as np
import pandas as pd
from pandas import Series, DataFrame
data = {
'Country':['China','India','Brazil'],
'Capital':['Beijing','New Delhi','Brasilia'],
'Population':['123456','6543321','2012223587'],
}
DataFrame初始化
df = DataFrame(data,index=['a','b','C'])
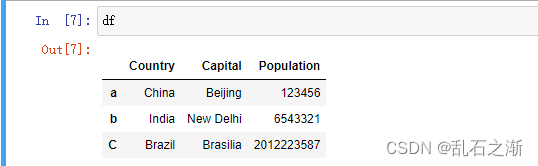
查询df[0:2]
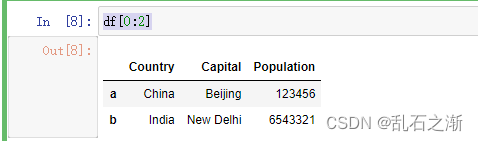
查询df.iloc[0:2,1:2]
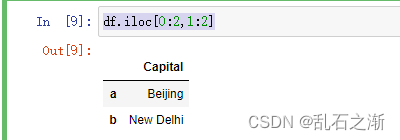
查询df.loc[['a','b']]
循环遍历
for row in df.iterrows():
print(row[0],row[1])
a Country China
Capital Beijing
Population 123456
Name: a, dtype: object
b Country India
Capital New Delhi
Population 6543321
Name: b, dtype: object
C Country Brazil
Capital Brasilia
Population 2012223587
Name: C, dtype: object
Series初始化
s1 = Series(data['Capital'])
s2 = Series(data['Country'])
s3 = Series(data['Population'])
df_new = DataFrame([s1,s2,s3],index= ['Capital','Country','Population'])
df_new = df_new.T # T含义是即为对数据 行列进行转置
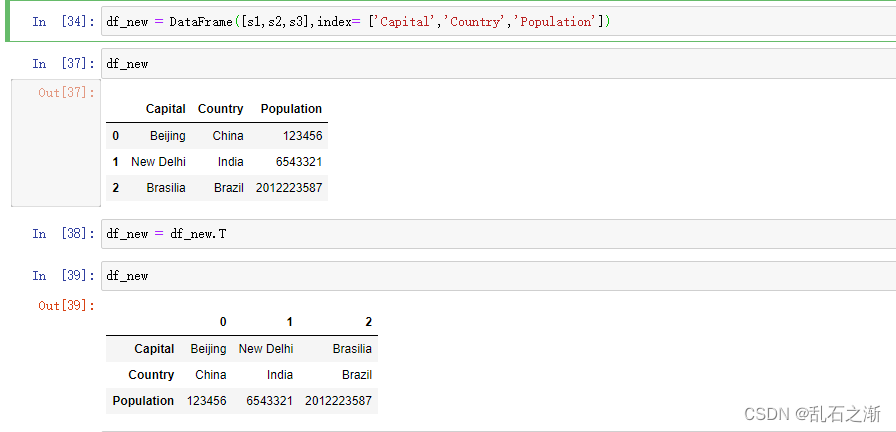
df_new.index = ['A','B','C']



















 841
841

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









