







目录
1.导入pandas
import pandas as pd
print(pd.__version__)
2.加载数据集
#read_csv()方法默认被加载数据集文件中的数据是以逗号分隔的,通过sep参数可以指定数据集实际所用的分隔符
df = pd.read_csv('csv文件路径',sep = '\t')
print(f'数据集加载后生成对象类型为:\n{type(df)}\n')
run:
数据集加载后生成对象类型为:
<class 'pandas.core.frame.DataFrame'>
3.查看当前数据集行、列数
#调用DataFrame的shape属性,获取指明该对象的行数和列数的元组
print('当前加载了csv文件的DataFrame对象的行列数为:\n{df.shape}')
?为什么要用大括号呢
run:
当前加载了csv文件的DataFrame对象的行列数为:
(1704,6)
4.查看数据集信息首\尾n行信息
#调用DF的head(n方法),输出数据集的前n行内容(若不设置n,则默认为5行)
print('当前数据前5行内容为:\n{df.head(n)}\n')
#调用DF的tail(n方法),输出数据集的末尾n行内容(若不设置n,则默认为5行)
print('当前数据末尾5行内容为:\n{df.head(2)}\n')
5.查看当前数据集所有列名
#调用DF的columns属性,获取包含当前加载数据集所有的列名的Index对象
print('当前的数据集中,所有列的列名为:\n{df.columns}\n')
print(type(df.columns))
run:

6.获取当前数据集索引信息
#调用DF的index属性,获取包含当前加载数据集的索引信息的RangeIndex对象
Print(df.index)
Print(type(df.index))

#调用DF的values属性,获取包含当前加载数据集的numpy的ndarray对象
Print(df.values)
Print(type(df.values))

7.获取当前数据集列元素类型
pandas的DF对象和Julia以及R中的DF对象类似,同一列中的元素类型必须相同,而每一行则可以由不同类型的列元素组成。
#调用DF的dtypes属性,获取一个展示了每个列的元素类型的series对象
print(df.dtypes)
print(type(df.dtypes)) 
#使用DF的info()方法可以查看更为详细的信息
print(df.info())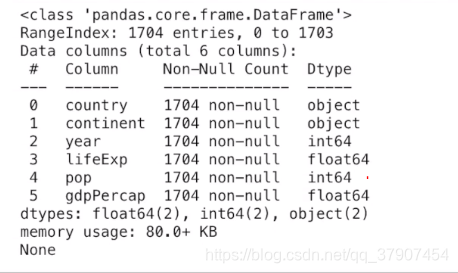
#补充:pandas的类型包括:
pandas中的object代替Python中的string,int64代替int,float64代替float,datetime64代替datetime8.查看特定列、行和单元格
获取单列组成的列子集(series对象)
#类似Python字典的取值,将列名看做字典的key,放入方括号中追加在变量后,来获取对应列
country_df = df['country']#获取country列的series对象
print(type(country_df))
#输出该列的前五行和末尾五行
print(country_df.head())
print(country_df.tail())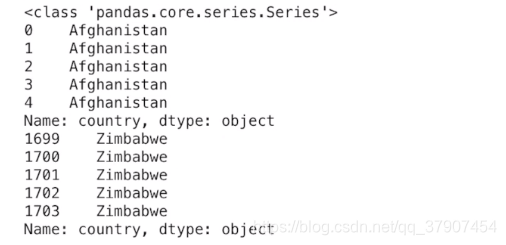
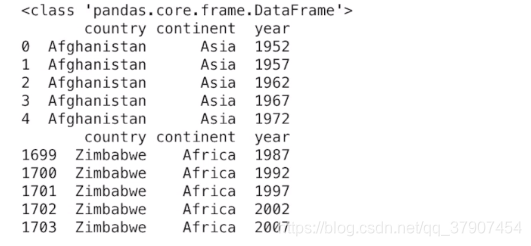
获取多列组成的列子集(DF对象)
#通过列名获取指定的多列时,需传入一个列名构成的Python列表
subset = df[['country','continent','year']]
print(type(subset))
print(subset.head())
print(subset.tail())
获取行子集
如上所示,左侧的行号为DF的索引标签,可以将其看作是这一行的行名。
默认下pandas会使用行号填充索引标签(0-based)。
但行号与索引标签是不同的东西,例如处理时间序列的数据时,索引标签将是某种时间戳
使用DF的loc属性,基于索引标签获取行子集
获取单行的行子集
print(df.loc[0])
print(type(df.loc[0]))
获取最后一行的行子集
#报错,无法直接通过-1进行最后一行的获取,因为在当前的DF对象中并未定义名为-1的索引标签
print(df.loc[-1])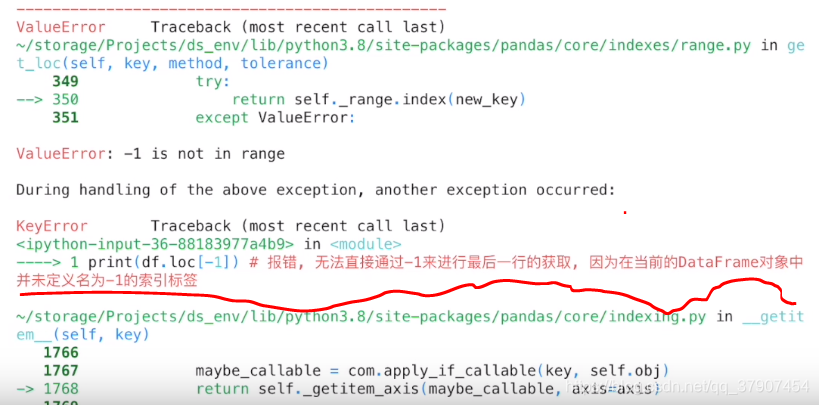
#在使用loc时,可以通过shape获取所有的行数,然后计算最后一行的默认索引标签
row_count = df.shape[0]
last_index = row_count - 1
print(df.loc[last_index ])#此处获取的是series对象
print(type(df.loc[last_index ]))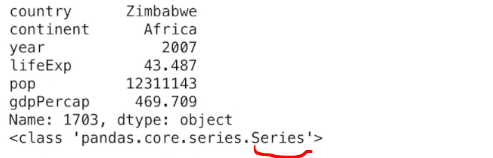
#通过shape配合切片来获取最后一行
print(df.loc[df.shape[0]-1:df.shape[0]])#获取最后一行的DF对象
print(type(df.loc[df.shape[0]-1:df.shape[0]])) 
#可使用tail(1)指定获取最后一行的DF对象
print(df.tail(1))
print(type(df.tail(1))) 
获取多行组成的行子集
通过索引标签名获取指定的多行时,需传入一个索引标签名构成的Python列表
得到的行子集是dataframe对象
print(df.loc[[0,99,199]])
print(type(df.loc[[0,99,199]]))
使用dataframe的iloc属性,基于索引号获取行子集
获取单行的行子集
获取包含第一行数据的series对象
print(df.iloc[0])
print(type(df.iloc[0]))
可直接通过-1来获取包含最后一行数据的series对象
print(df.iloc[-1])
print(type(df.iloc[-1]))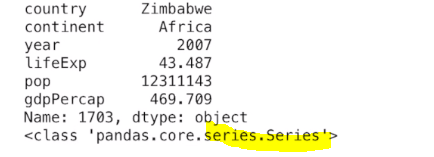
获取多行组成的行子集
通过索引号获取指定的多行时,需传入一个索引号构成的Python列表
print(df.iloc[[0,99,199]])
print(type(df.iloc[[0,99,199]]))

使用切片语法获取行子集
通过切片配合loc、iloc属性,获取连续范围内的指定行
不同的是,local返回的结果为前三条数据组成的dataframe对象,iloc返回的结果为前两条数据组成的dataframe对象
print(df.loc[0:2])
print(type(df.loc[0:2]))
print(df.iloc[0:2])
print(type(df.iloc[0:2]))

获取第15行到第11行组成的倒叙dataframe对象,使用-1完成的倒叙
ps:这里15和10的顺序颠倒一下会怎样呢?
print(df.loc[15:10:-1])
print(type(df.loc[15:10:-1]))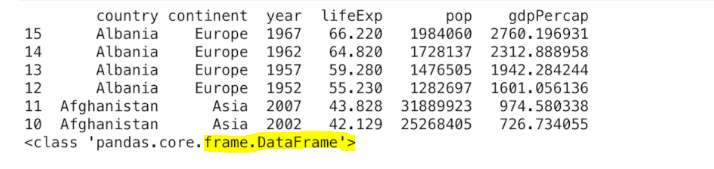
print(df.iloc[15:10:-1])
print(type(df.iloc[15:10:-1]))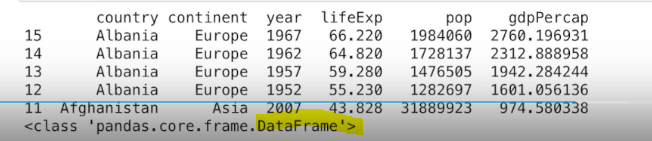
获取特定行及特定列
使用loc或iloc属性获取特定的行及列
df.loc[[行],[列]]:行是索引标签名,列是列名
df.iloc[[行],[列]]:行是索引号,列是索引号
#前三行的year和pop列组成的dataframe对象
subset = df.loc[0:2,['year','pop']]
print(subset)
# 前两行的第3、5和最后一列组成的dataframe对象
subset = df.iloc[0:2,[2,4,-1]]
print(subset)
print(type(subset))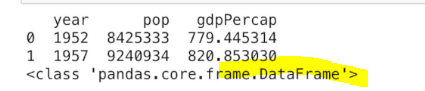
iloc属性支持使用切片获取指定列
#前两行的第3、4列组成的dataframe对象
subset = df.iloc[0:2,2:4]
print(subset)
print(type(subset))
补充:借助范围对象获取行或列子集
实质还是传入列表
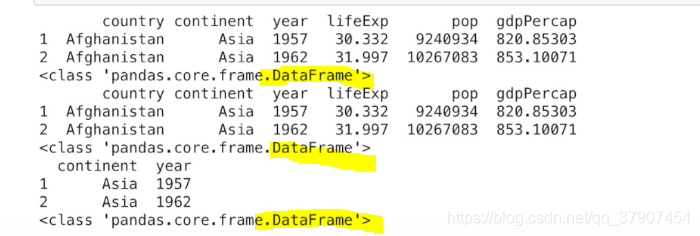
# 第二行第三行的dataframe对象
a = range(1,3)#1,2
subset = df.loc[list(a)]
print(subset)
print(type(subset))
# 第二行第三行的dataframe对象
a = range(1,3)#1,2
subset = df.iloc[list(a)]
print(subset)
print(type(subset))
# 第二行第三行的第二第三列组成的dataframe对象
a = range(1,3)#1,2
subset = df.iloc[list(a),list(a)]
print(subset)
print(type(subset))
9.分组聚合计算
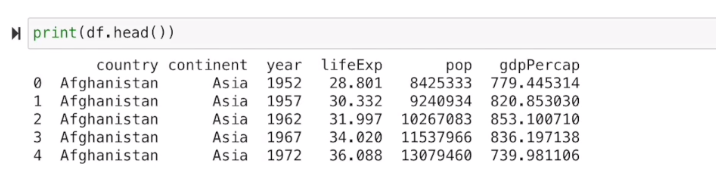
print(df.head(20))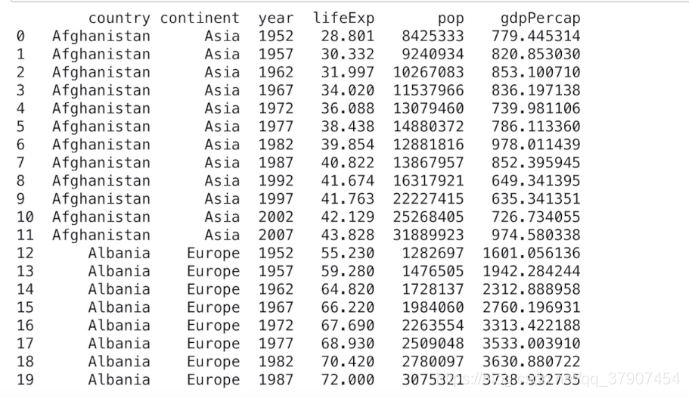
假设我们需要计算不同年份全人类的平均寿命,我们可以使用dataframe的groupby()方法要对数据线按照年份进行分组,然后获取lifeExp列进行计算,最后将各个独立计算组合成一个dataframe
根据某个列进行分组
根据我们设置的分组条件创建一个dataframeGroupBy对象
从中我们抽取需要的列返回一个SeriesGroupBy对象(因为是单列,多列是DataFrameGroupBy对象)
计算该seriesGroupBy对象中数据的平均值,返回一个包含结果的series对象
dgb = df.grouby('year')
print(type(dgb))
sgb = dgb['lifeExp']
print(type(sgb))
result = sgb.mean()
print(result)
print(type(result))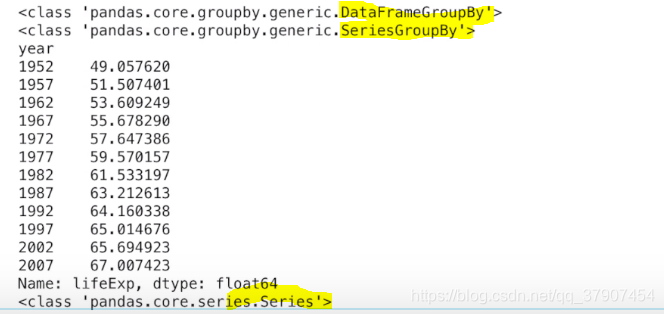

















 1809
1809

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









