







Hashmap是我们经常使用的,它的实现原理也不难,只不过在java1.7和java1.8中的实现有所不同,还有一些比较细节的问题,我们来一起看看。
java1.7中的实现
hashmap的底层数据结构非常简单,实际上就是一个数组,数组的每个位置存储了每条链表的头节点,链表的每个节点存储有每个对象的key和value,如下图:
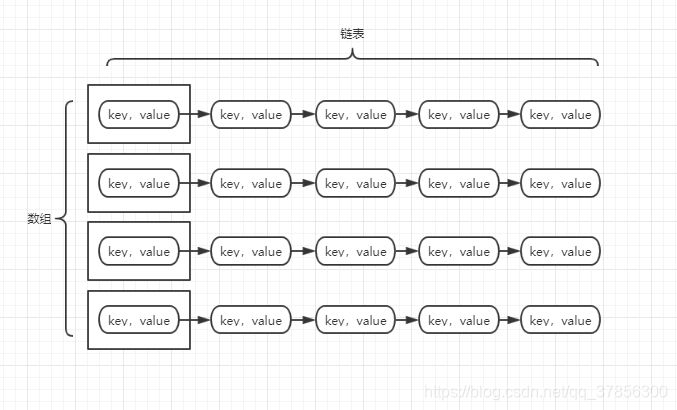
这里左边的虽然是个数组,但是通常我们把这个数组的每一个位置称作是一个“桶”。
那么,如果我们把一个对象放入hashmap中,过程是怎么样的呢?
首先,我们需要先对对象的hashcode进行hash运算,以此来确定它将要散列到哪个“桶”里,假如我们要自己手写一个hashmap的话,通常我们对hashcode进行取余操作就可以达到散列的目的了。例如:此时有4个桶,我们的对象的hashcode分别是:6,7,8,那么我们就使用6,7,8对4取余,结果是:2,3,0,所以我们就依次把它们分配到第3,4,1个桶中,这就实现了一个简单的hashmap。
但是,真正的hashmap中,进行hash的算法是使用对象的hashcode对 桶的个数-1 进行与运算,因为取余的运算消耗的性能还比较大,而与运算就好多了。
当一个对象进行hash操作之后,如果将要进入的桶中已经有了链表了,那么就要理所应当地插入到链表当中,这样的操作称为“碰撞”
这里就会引出了hashmap在设计上的一个优点:当桶的个数是2的n次幂的时候,hashmap的效率最高;当桶的个数不是2的n次幂的时候,hashmap会默认选择最接近的2的n次幂来当作桶的个数。这是为什么呢?
举个例子,当我们的桶个数是15的时候,换算成2进制就是:1111,按照hashmap的hash规则,我们需要用对象的hashcode对15-1进行与运算,也就是对1110进行与运算,这时我们发现,与的结果的最后一位必然是0,而不可能是1,也就是说,0001,0011,0101,1001,1011,0111,1101这几个位置都不能存放元素了,浪费的空间何其巨大!
其次,在桶个数是2的n次幂的时候,hash操作完成后放入同一个桶中的概率比不是2的n次幂的时候要小,也就减小了“碰撞”的概率,对hashmap的性能也是一种提升。
还有一点就是,当我们的桶的个数比较少,数据比较多,就会造成每个桶中装的链表非常的长,这样会加大碰撞的性能消耗,而且也不利于我们进行查找操作的,这时,hashmap会进行自动扩容,扩容的条件是当hashmap中的元素个数超过桶个数 * loadfactor时,就会进行数组扩容。例如,默认情况下,桶的个数是16,loadfactor是0.75,那么当元素个数超过16 * 0.75 = 12的时候,hashmap就会进行扩容了,会扩容到原来的两倍。
hashmap扩容是非常损耗性能的一种操作,hashmap会重新为各个元素分配位置,并进行hash运算,听起来就知道这是非常浩大的工程,尤其是在数据已经非常多的情况下。因此,为了避免hashmap经常扩容(resize),我们可以为它设置合适的桶的个数。例如,我们预计要装入1000个元素,这个时候你可能会说,我们应该设置最接近的2的n次幂作为桶的个数,也就是设置1024,但是考虑到我们应该尽量减少扩容操作,所以我们应该保证 桶个数 * 0.75 > 1000 ,因此实际上我们应该设置的桶个数是2048。
java1.8中的实现
在java1.8中,hashmap的实现变成了数组+链表+红黑树,在1.7中,单纯使用数组+链表的时候,由于在链表中的查询复杂度是O(n),因此并不是非常的快,在1.8中,使用红黑树查询的时候,复杂度变成了O(logn),当一个桶中的链表的元素个数大于8了之后,hashmap就会自动将它转换为红黑树,同时java1.8中对扩容机制也做了一些优化,在jdk7中的HashMap扩容操作是将原数组的结点一一进行hash计算,然后一一挂接到新数组上;jdk8中的HashMap扩容操作是将原数组每个结点的hash值和原数组长度进行“与”操作,结果等于0代表该结点位置不变,落在新数组的同样位置,否则该结点在新数组的位置是[j + oldCap]上。
HashMap并发问题:死循环
Hashmap的Resize包含扩容和ReHash两个步骤,ReHash在并发的情况下可能会形成链表环。因为,链表采用头插法,将原数组转移到新数组时,会从前向后遍历链表结点,头插法机制恰好使新数组中结点的相对顺序和原数组中颠倒过来。在并发的时候,假如原来的结点顺序被线程A颠倒了,而被挂起的线程b在恢复执行后,拿扩容前的节点和顺序继续完成第一次循环,而后又遵循A线程扩容后的链表顺序重新排列链表中的顺序,即又颠倒了一下顺序,最终形成了环。

















 43万+
43万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









