










 本系统利用Canny边缘检测和霍夫直线检测进行试卷预处理,通过百度OCR识别文字,结合自然语言处理技术自动划分题目,实现高效准确的试卷分析。
本系统利用Canny边缘检测和霍夫直线检测进行试卷预处理,通过百度OCR识别文字,结合自然语言处理技术自动划分题目,实现高效准确的试卷分析。
 bilibili宣传视频:https://www.bilibili.com/video/av53893090
bilibili宣传视频:https://www.bilibili.com/video/av53893090
github:https://github.com/blue-sky-sea/Paper-Question-recognition
当前系统及库版本
Windows:win10
anaconda: Anaconda navigator 1.9.2
opencv: Opencv3 3.1.0
AipOcr: 百度ocr库最新
re: re库,自带
python:Python 3.7.0
系统总体思路
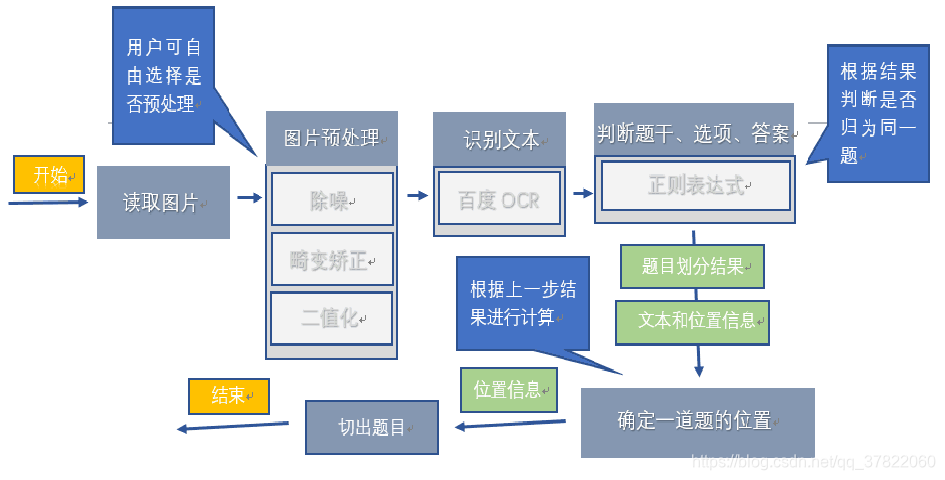
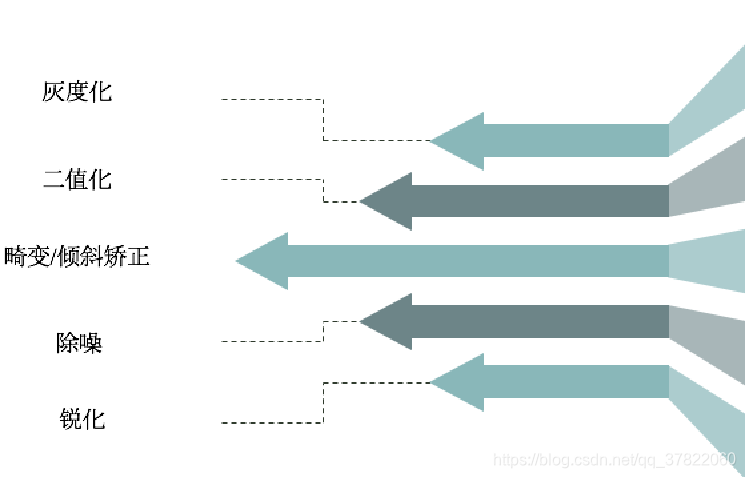
预处理
透视矫正:目标找到纸的四个点然后矫正成右下图的样子

如何找到四个点?
有两大方法:Canny边缘检测和霍夫直线检测
边缘检测效果:得到近似轮廓从而获得四个点的位置
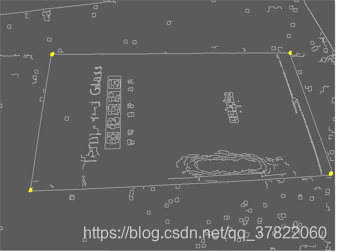
霍夫直线效果:找出所有‘’可疑‘’直线

根据条件和实际情况筛选出竖线和横线,计算交点即可找到纸张的四个点


最终可以根据实际情况综合考虑上述两个方法
双页试卷处理:
类似这种图片,需要把试卷分成左右两份

我们的思路是:
1.选取中间部分的区域(如40%~60%)我们考虑上下也各截取了一部分,将该区域二值化

2.找到连续白色区域最多,但又远大于字与字空隙的距离的区域
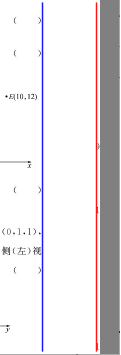
3.计算这个区域的中心线后,这条线就是我们要找的双页试卷的切割线(橙色)

这个方法甚至可以处理两页之间中间有直线的试卷。只要存在满足一定条件的空白区域就可以找到分割线。
文字识别
最初我们用teseeract库作识别,但是识别精度感人,jTesssBoxEditor训练字库的效果也很感人。
时间紧迫,我们就选择了百度Ocr的API接口作为文字识别的工具。缺点是,免费版低精度一天只有500次的使用次数。
自然语言处理
这一部分是划分题目的重中之重。
我们之前的想法是,判断识别出的某一段是否为题干,如果是题干,那么就把它和上面的部分划分开来。
但是,判断题干的效果并不好。原因在于:
1.ocr文字识别出现误差,没有识别出必要的题号等标志性词。
2.没有良好的分词。
3.正则表达式判断题干情感(比如:‘’请问…的答案是‘’、‘’以下…正确的是“ 这种一看就是题目的题干的结构)难以尽善尽美,往往需要后期debug才能补充;
简而言之,能否正确识别出题干,是我们最需要关心的。
只要识别出题干,那么上一题就被分出来了。
 另外还要考虑一下 注意事项,等无关紧要的东西不要被划分成题目。
另外还要考虑一下 注意事项,等无关紧要的东西不要被划分成题目。
划分出选择题的思路大致也和上面一样
划分题目区域
由于百度ocr接口除了文字还附带位置信息,所以我们只需要把每道题的题干+题目内容的位置信息合并就可以知道整道题的位置信息了。
ocr接口位置信息有4个变量(top,left,height,width),如下。
 一道题按理来说就包括了图中的两个红框的位置信息,只要综合考虑位置信息,一定可以得到整道题的位置信息。
一道题按理来说就包括了图中的两个红框的位置信息,只要综合考虑位置信息,一定可以得到整道题的位置信息。
 但是实际操作中出现了意外,一道题当最后一行压根没有识别出来怎么办。
但是实际操作中出现了意外,一道题当最后一行压根没有识别出来怎么办。
解决办法是,根据下一道题的top信息来计算上一道题的height,这样就避免了 A.北京人遗址这一行没被识别出来的尴尬。

前端
综合考虑,我们还是使用了python的tkinter库制作前端。
很简单,很朴素。
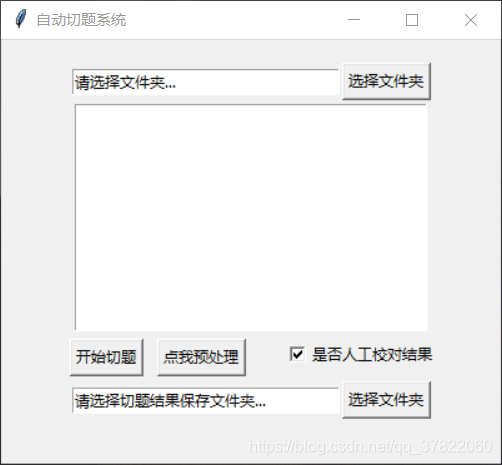
包括了选择图片所在的文件夹,切题结果保存的文件夹,预处理,是否 人工校对,开始切题的功能。
如果开启了人工校对,切题完成后会出现校对页面。右边是原图,左边是切题结果。


















 969
969

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









