







 本文详细介绍了爬虫的基本架构,包括URL管理、网页下载及解析模块,并深入探讨了使用Python和BeautifulSoup进行网页抓取的具体操作,适合初学者快速掌握爬虫搭建与应用。
本文详细介绍了爬虫的基本架构,包括URL管理、网页下载及解析模块,并深入探讨了使用Python和BeautifulSoup进行网页抓取的具体操作,适合初学者快速掌握爬虫搭建与应用。
一、爬虫简介
•自动抓取互联网信息的程序
• 利用互联网数据进行分析、开发产品
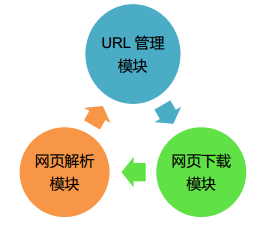
基本架构
• URL 管理模块
对计划爬取的或已经爬取的URL进行管理(比如失效的URL、已经抓取的URL、新来的呀爬取的URL)
• 网页下载模块
将URL管理模块中指定的URL进行访问下载
• 网页解析模块
解析网页下载模块中的URL, 处理或保存数据,如果解析到要继续爬取的URL,返回URL管理模块继续循环
二、URL管理模块
•URL管理的作用: 防止重复爬取或循环指向
• 功能:
可添加新的URL、管理已爬取的URL和未爬取的URL、获取待爬取的URL
• 实现方式
Python的set数据结构, why? 集合的特性决定的啦
数据库中的数据表, how? 标记位
三、网页下载模块
将URL对应的网页下载到本地或读入内存(字符串)
• requests模块
• requests.get(url)返回response对象
• response对象
• status_codes: 状态码
• headers: 网页header信息
• encoding: 网页编码
• text: 请求返回的文本信息
• content: 以字节形式返回的非文本信息
常见的HTTP状态码
• 200:请求成功
• 404:请求的资源不存在
• 500:内部服务器错误
当然,除了requests可以实现网页下载以外,urllib也可以实现相同的功能,则使用这两种方法下载网页的代码正确的:
urllib.request.urlopen(url)
# 状态码
r_obj.status_code
# 网页header信息
r_obj.headers
# 网页编码
r_obj.encoding
# 请求返回的文本信息
r_obj.text
# 以字节形式返回的非文本信息
r_obj.content
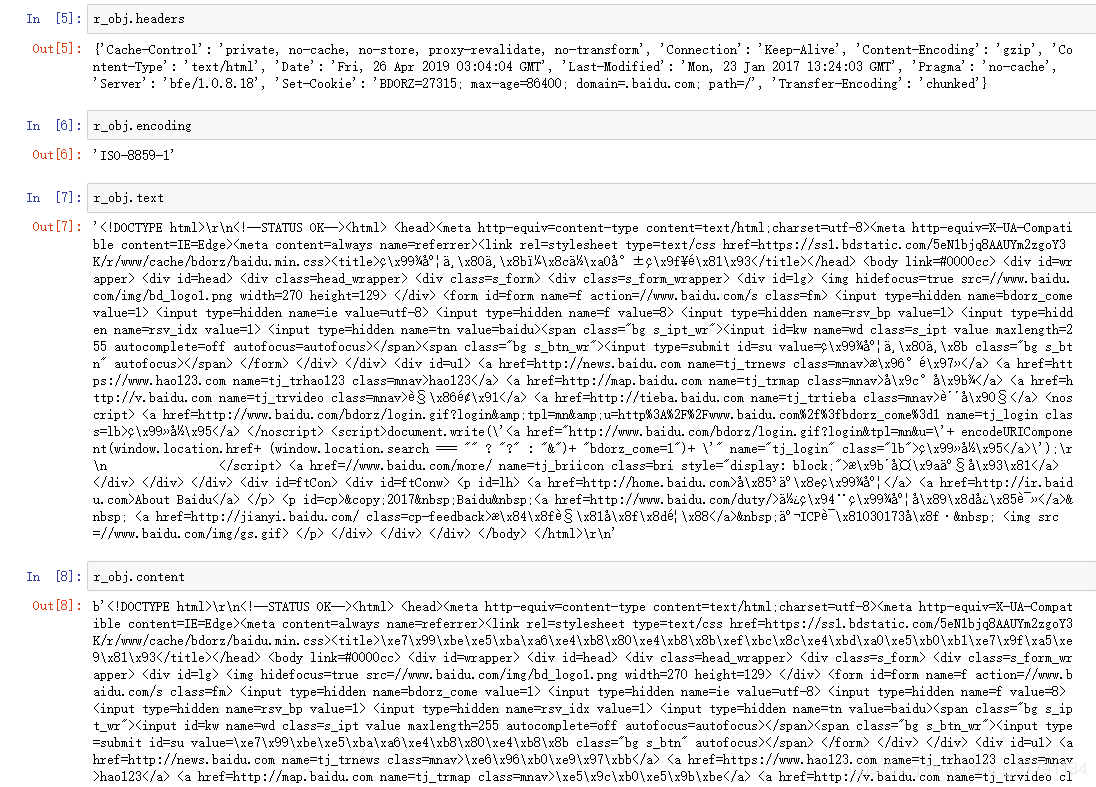
一般情况吓text和content针对一般任务都差不多,content包含的就是由非文本其他的信息,例如图片之类的
因为百度 网页编码是'ISO-8859-1',所以看到的是乱码,怎么办?嗯, 出现乱码,使用utf-8编码就可显示出中文啦,ok。

四、网页解析模块
从已下载的网页中解析所需的内容
• 实现方式
字符串匹配:如正则表达式 (通过对字符串进行某些规则使得将我们需要的信息解析出来)
html.parser: Python自带的解析html的工具
BeautifulSoup: 结构化的网页解析 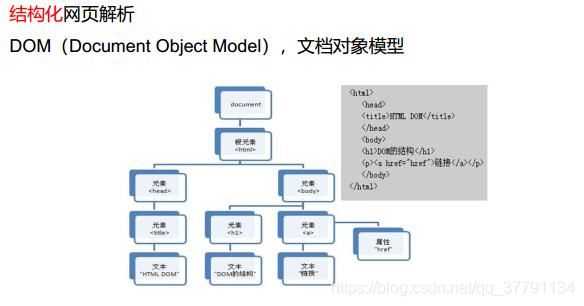
BeautifulSoup使用步骤
1. 创建BeautifulSoup对象 (美味的汤)
BeautifulSoup(
url,
html_parser, 指定解析器
encoding 指定编码格式(确保和网页编码格式一致)
)
BeautifulSoup常用的解码器有哪些啊?
叫“解析器”会更准确。常用的有4个:html.parser,lxml,lxml-xml,html5lib。对比如下:

2. 查询节点
• find(),找到第一个满足条件的节点
• find_all(),找到所有满足条件的节点
3. 获取节点信息
•查询节点
• 可按节点类型或属性查找
如: <a href=“test.html” class=“test_link”>next page</a>
• 按类型: find_all(‘a’)
• 按属性:
find_all(‘a’, href=‘test.html’)
find_all(‘a’, href=‘test.html’, string=‘next page’)
find_all(‘a’, class_=‘test_link’)
没有学术哦

但是网址有哦
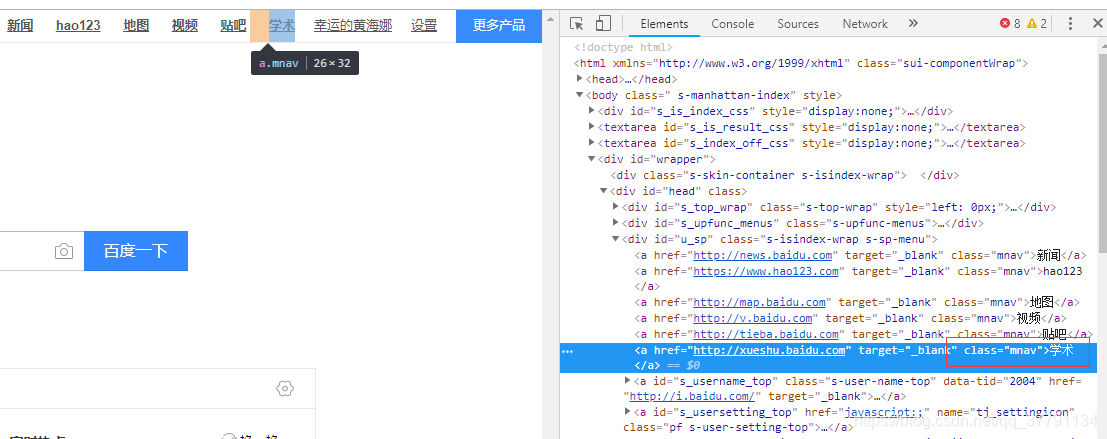 说明什么呢?说明反爬!
说明什么呢?说明反爬!
这里很疑惑 ,为什么编码和r_obj.encoding出来的不一样!
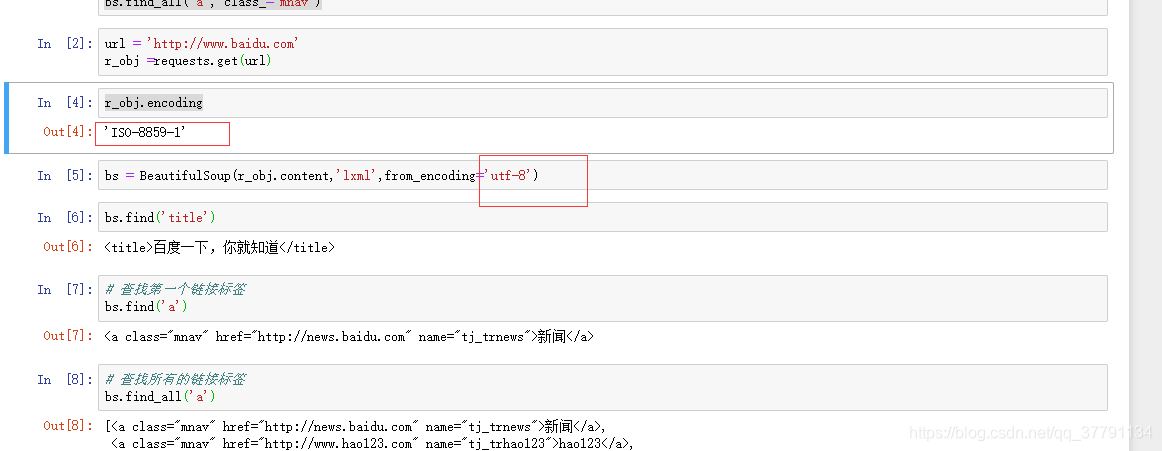
BeautifulSoup使用步骤
1. 创建BeautifulSoup对象
BeautifulSoup(
url,
html_parser, 指定解析器
encoding 指定编码格式(确保和网页编码格式一致)
)
2. 查询节点
• find(),找到第一个满足条件的节点
• find_all(),找到所有满足条件的节点
3. 获取节点信息
• 获取节点信息
• 查找节点返回的是Tag对象,获取Tag对象信息
如:![]()
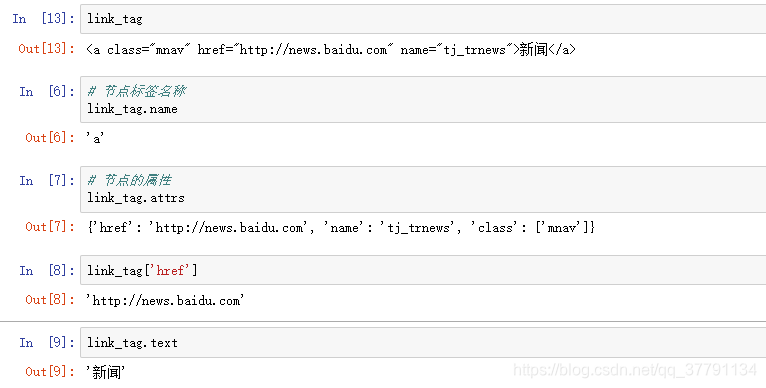
• Tag.name:节点标签名称, ’a’
• Tag.attrs:节点的属性,字典类型
{'class': ['mnav'], 'href': 'http://news.baidu.com', 'name': 'tj_trnews'}
• Tag.text:获取节点文本, ‘新闻”
• 获取其他节点信息
• children:只返回“孩子”节点
• desecdants 返回所有“子孙”节点
• next_siblings 返回下一个“同辈”节点
• previous_siblings 返回上一个“同辈”节点
• parent 返回“父亲”节点
例子:
简单解析百度首页
- url = 'http://www.baidu.com'
r_obj = requests.get(url) - bs = BeautifulSoup(r_obj.content,
'lxml',
from_encoding='utf-8') - # 查找title标签
link_tag = bs.find('a')
获取节点信息
获取其他节点信息
url = 'http://www.pythonscraping.com/pages/page3.html'
r_obj = requests.get(url)
bs_obj = BeautifulSoup(r_obj.content, 'lxml')
# 获取表格标签
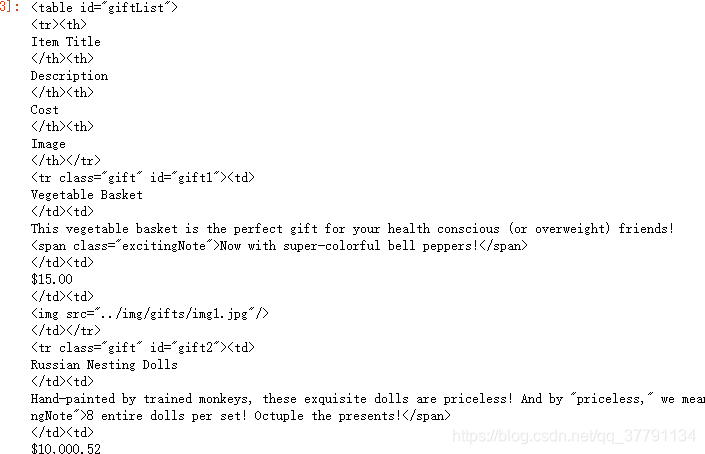
table_tag = bs_obj.find('table')
# 获取表格的每行内容,即“孩子”节点
for row in table_tag.children:
print(row)

上面就是把这个节点包含的所有信息都显示出来
# 获取子孙节点
for descendant in table_tag.descendants:
print(descendant)

很长很长 先显示了全部又分开的显示了一次
# 返回下一个“同辈”节点
first_row = table_tag.find('tr')
#找tr的“同辈”节点
for sibling in first_row.next_siblings:
print(sibling)

first_row为table的第一个tr节点

# 返回“父亲”节点
first_row.parent
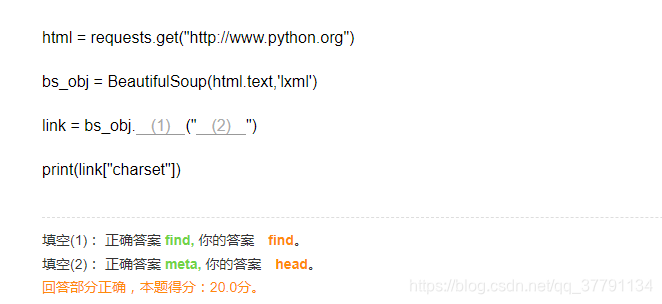
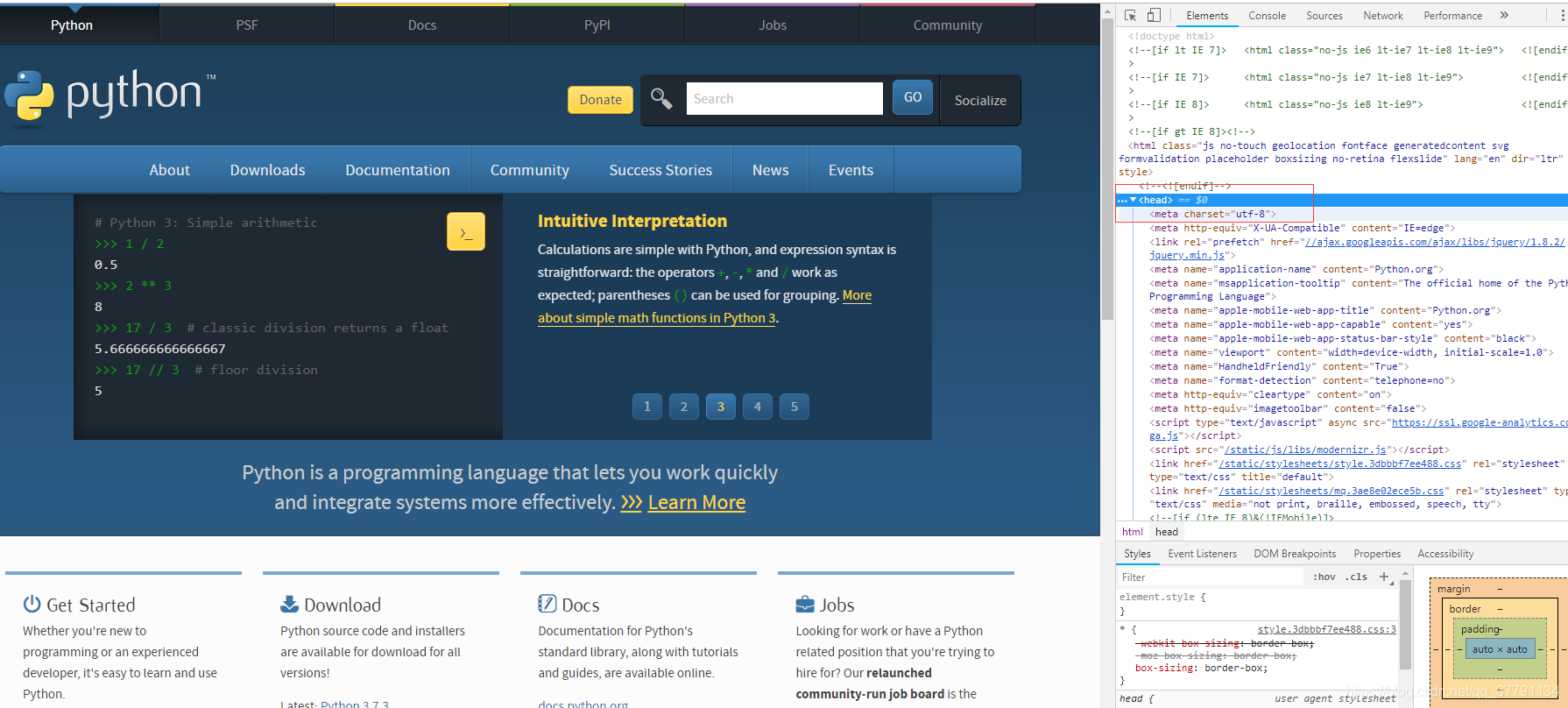
练习
使用BeautifulSoup对网页内容进行分析,进而获取url = http://www.python.org的编码charset方式

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









