







 这篇博客介绍了如何用numpy实现三分类问题,包括one-hot编码、softmax函数、损失函数和梯度下降算法。作者通过训练数据集SR.txt进行模型训练,并展示了损失函数随迭代次数的变化情况,最后评估了模型的错误率。
这篇博客介绍了如何用numpy实现三分类问题,包括one-hot编码、softmax函数、损失函数和梯度下降算法。作者通过训练数据集SR.txt进行模型训练,并展示了损失函数随迭代次数的变化情况,最后评估了模型的错误率。
实现的三分类
One-hot Vector
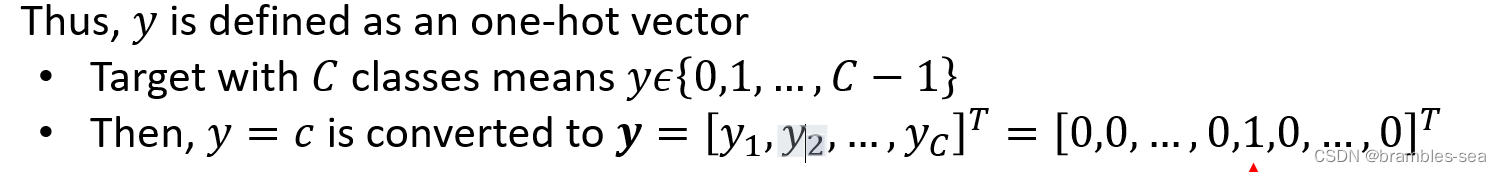
实现方法:np.eye()
Softmax function
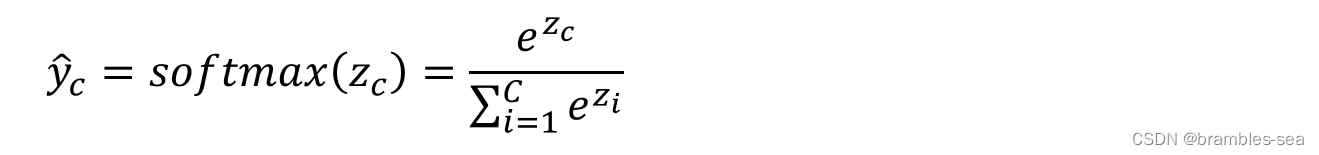
Loss Function
真实值与预测值的差距,预测越接近1,损失越小。
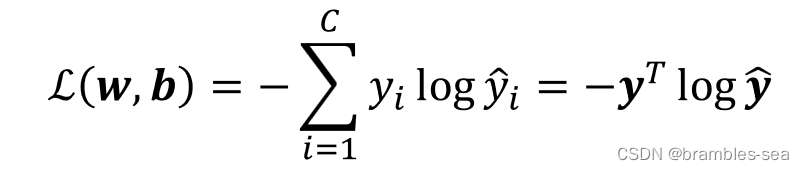
梯度下降
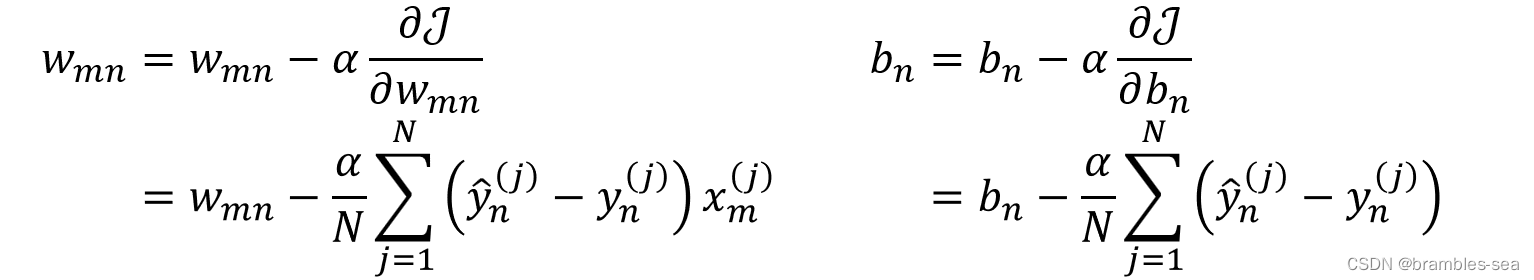
# -*- coding: utf-8 -*-
import numpy as np
import matplotlib.pyplot as plt
def softmax(z):
return np.exp(z)/np.sum(np.exp(z), axis=1, keepdims=True)
def cost_gradient(W, X, Y, n):
hat_y = softmax(np.dot(X, W))
G = 1/n*np.dot(X.T, hat_y-Y)
J = -1/n*np.sum(Y * np.log(hat_y))
return J, G
def train(W, X, Y, n, lr, iterations):
J = np.zeros([iterations, 1])
for i in range(iterations):
(J[i], G) = cost_gradient(W, X, Y, n)
W = W - lr*G
return (W,J)
def error(W, X, Y):
#Y_hat = ###### Output Y_hat by the trained model
Y_hat = softmax(np.dot(X, W))
pred = np.argmax(Y_hat, axis=1)
label = np.argmax(Y, axis=1)
return (1-np.mean(np.equal(pred, label)))
iterations = 1500
lr = 1e-1
data = np.loadtxt('SR.txt', delimiter=',')
n = data.shape[0]
X = np.concatenate([np.ones([n, 1]),
np.expand_dims(data[:,0], axis=1),
np.expand_dims(data[:,1], axis=1),
np.expand_dims(data[:,2], axis=1)],
axis=1)
Y = data[:, 3].astype(np.int32)
c = np.max(Y)+1
#one-hot
Y = np.eye(c)[Y]
W = np.random.random([X.shape[1], c])
(W,J) = train(W, X, Y, n, lr, iterations)
plt.figure()
plt.plot(range(iterations), J)
print(error(W,X,Y))
















 407
407

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









