







 文章介绍了ArrayList和LinkedList的异同,包括线程安全、底层结构、插入删除、随机访问、内存占用和扩容机制等方面。还详细讲解了HashMap,涉及底层结构、扰动函数、拉链法、扩容机制,对比了其与Hashtable的区别,解释了长度为2的幂次方的原因,以及多线程操作导致死循环的问题。
文章介绍了ArrayList和LinkedList的异同,包括线程安全、底层结构、插入删除、随机访问、内存占用和扩容机制等方面。还详细讲解了HashMap,涉及底层结构、扰动函数、拉链法、扩容机制,对比了其与Hashtable的区别,解释了长度为2的幂次方的原因,以及多线程操作导致死循环的问题。
文章目录
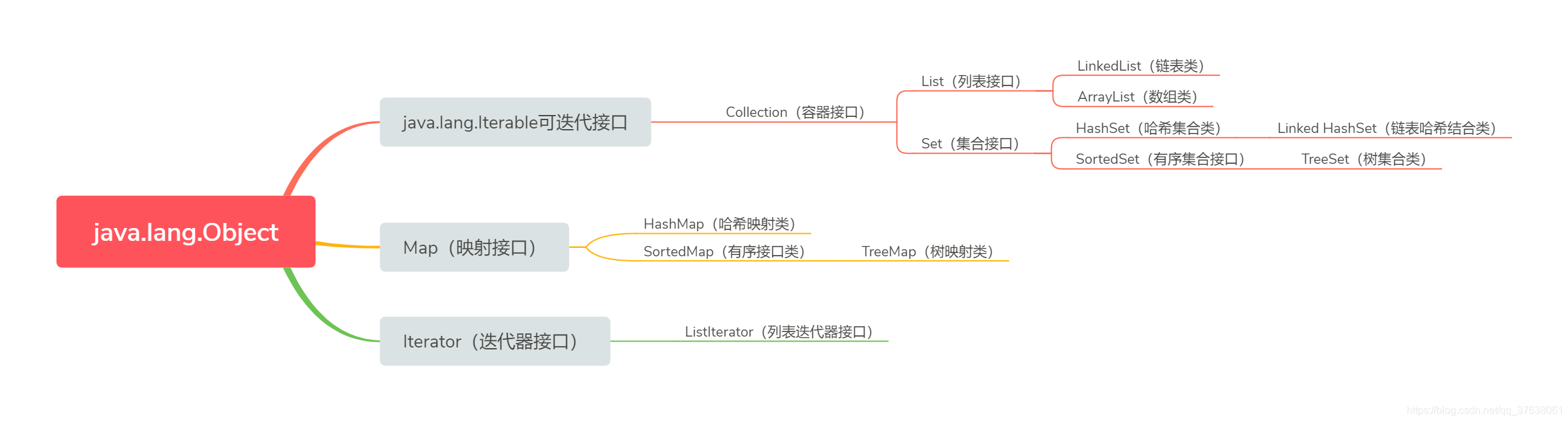
容器框架中的接口和实现接口的类的继承方法(该图片来自于Java程序设计基础第五版)
- 此文章参考于JavaGuide
1. ArrayList 和 LinkedList的异同
-
是否线程安全:两者都是不同步的,即 不保证线程安全。
-
底层数据结构:ArrayList的底层是Object数组,LinkList的底层是双向链表结构
-
插入和删除是否受元素位置的影响:
- ArrayList 采用数组存储,插入、删除元素受元素位置影响。
- LinkedList 采用链表存储,插入。删除不受位置影响。
-
快速随机访问:ArrayList支持,快速随机访问就是通过元素序列号快速获取元素对象(对应于get(int index)方法)。LinkedList 不支持快速随机访问。
-
内存空间占用:ArrayList 的空间浪费主要体现在 list列表的结尾会预留一定的容量空间,而LinkedList的空间花费则体现在他的每一个元素都需要消耗比ArrayList更多的空间(因为要存放 直接前驱 和 直接后继 以及数据)
-
扩容机制:ArrayList的默认初始容量大小为10;每次扩容为当前容量的1.5倍。
/** * ArrayList扩容的核心方法。 */ private void grow(int minCapacity) { //elementData为保存ArrayList数据的数组 ///elementData.length求数组长度elementData.size是求数组中的元素个数 // oldCapacity为旧容量,newCapacity为新容量 int oldCapacity = elementData.length; //将oldCapacity 右移一位,其效果相当于oldCapacity /2, //我们知道位运算的速度远远快于整除运算,整句运算式的结果就是将新容量更新为旧容量的1.5倍, int newCapacity = oldCapacity + (oldCapacity >> 1); //然后检查新容量是否大于最小需要容量,若还是小于最小需要容量,那么就把最小需要容量当作数组的新容量, if (newCapacity - minCapacity < 0) newCapacity = minCapacity; //再检查新容量是否超出了ArrayList所定义的最大容量, //若超出了,则调用hugeCapacity()来比较minCapacity和 MAX_ARRAY_SIZE, //如果minCapacity大于MAX_ARRAY_SIZE,则新容量则为Interger.MAX_VALUE,否则,新容量大小则为 MAX_ARRAY_SIZE。 if (newCapacity - MAX_ARRAY_SIZE > 0) newCapacity = hugeCapacity(minCapacity); // minCapacity is usually close to size, so this is a win: elementData = Arrays.copyOf(elementData, newCapacity); }
2. HashMap
- 底层数据结构:JDK1.8之前 底层是 数组和链表 结合在一起,也就是 链表散列。
- HashMap 通过 key 的 hashCode 经过扰动函数处理过后得到 hash值,然后通过 (n - 1) & hash判断当前元素存放的位置(n:数组的长度),如果当前位置存在元素的话,就判断该元素与要存入的元素的 hash 值以及 key 是否相同,如果相同的话,直接覆盖,不相同就通过拉链法去解决冲突。
- 扰动函数:HashMap 的 hash方法,使用 hash 方法就是为了防止一些实现比较差的hashCode()方法。换句话说,使用扰动函数之后可以减少碰撞。
- 拉链法:将链表和数组相结合。也就是说创建一个链表数组,数组中每一格就是一个链表。若遇到哈希冲突,则将冲突的值加到链表中即可(链地址法)。
- 1.8之后,在解决哈希冲突时有了较大的变化,当链表长度大于阈(yù)值(默认为8)时,将链表转化为红黑树,以减少搜索时间。
- 初始容量:初始容量:16,(长度始终保持为2的n次方),如果用户通过构造函数指定了一个数字作为容量,那么Hash会选择大于该数字的第一个2的幂作为容量。(3->4、7->8、9->16)。
- 扩容机制:每次扩容为原来的2倍。
HashMap 和 Hashtable 的区别
- 线程是否安全:HashMap 非线程安全,HashTable是线程安全的,HashTable 内部的方法都经过了 synchronized 修饰。(但要保证线程安全时,也是使用的 ConcurrentHashMap)
- 效率:因为线程安全的问题,HashMap的效率要比HashTable的效率要高一点。另外,HashTable基本是一个遗留类,尽量不要再代码中使用它
- 对空键和空值的支持:HashMap中,null可以作为键,但这样的键只有一个,可以有一个或多个键所对应的值为null。但是在HashTable中put 进的键值只要有一个 null,直接抛出 NullPointerException。
HashMap的长度为什么是2的幂次方
-
为了能让 HashMap 存取高效,尽量减少碰撞,也就是要尽量吧数据分配均匀。Hash值的范围是 -231(-2147483648)到231-1(2147483647),前后加起来是一个大约40亿的映射空间。只要哈希函数映射的比较均匀松散。但问题是一个40亿长度的数组,内存是放不下去的。 所以这个散列值是不能直接拿来使用的。用之前还有先对数组的长度取模运算,得到的余数就是存放的位置(对应数组的下标),数组下标计算方法是
(n - 1) & hash,(n代表数组长度)。这个算法应该如何设计呢?
取余啊 % 。但是重点来了 取余(%)操作中,如果除数是2的幂次 则等价于 与其除数减一的与(&)操作,也就是说
hash % n == hash & (n - 1),前提是n 必须是2的n次方。并且采用二进制位操作 与& ,相对的能够提高运算效率,这就是为什么 HashMap的长度是2的幂次方。
HashMap多线程操作导致死循环问题
- 在多线程下,进行 put 操作会导致 HashMap 死循环。原因在于 HashMap 的扩容 resize()方法。由于扩容是新建一个数组,复制原数据到数组。由于数组下标挂有链表,所以需要复制链表,但是多线程操作有可能导致环形链表。

















 8325
8325

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









