




PTX 的mma指令用于计算不同数据类型的矩阵乘法,目前在CUTLASS库中wmma和mma都有使用。
在此记录下mma指令在计算1bit矩阵乘法时,怎么理解其中的线程中的寄存器对于矩阵数据的存放。
这里以1bit m16n8k128为例。
原PTX文档链接如下:
matrix-fragments-for-mma-m16n8k128
一、mma.m16n8k128

原文档这句话是说,这里将会用一个warp(通常是32个线程)执行1bit矩阵大小为m16n8k128的矩阵乘法。m16n8k128的意思是,矩阵A尺寸是16*128(row-major),矩阵B尺寸是128*8(col-major),结果矩阵C尺寸是16*8(row-major)(结果矩阵一般是float数据类型)。注意,这里仍旧是1bit为一个数据。
然后1bit矩阵的所有数据都会被32个线程瓜分。具体怎么瓜分呢?
二、1bit矩阵的线程具体分配过程理解
2.1 矩阵A
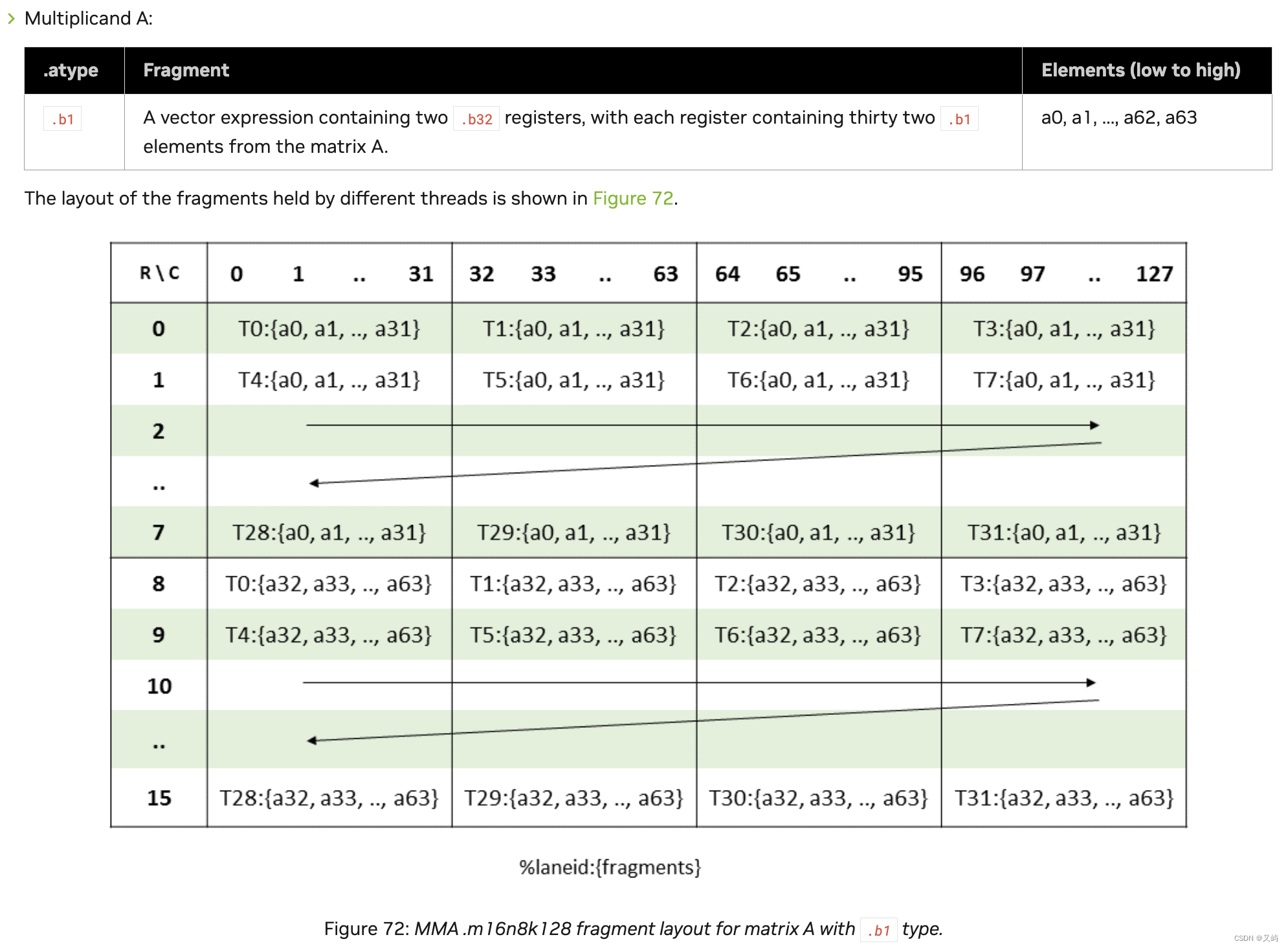
图1
PTX文档中对于1bit矩阵数据的瓜分过程写的很清
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 812
812

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









