







 本文探讨了N-gram模型在文本处理中的作用,包括文本分词、特征统计及概率计算等内容,介绍了N-gram模型在词性标注、垃圾短信分类、机器翻译和语音识别等领域的应用。
本文探讨了N-gram模型在文本处理中的作用,包括文本分词、特征统计及概率计算等内容,介绍了N-gram模型在词性标注、垃圾短信分类、机器翻译和语音识别等领域的应用。
背景
因为平时建模过程中会碰到一些文本类的特征,所以整理了下该怎样处理文本特征,以及怎样做文本特征类的衍生,涉及到NLP的内容很浅显。
如果想深入学习NLP,请移步到大神微博…
文本分词
利用python中的jieba、中科院、清华、哈工大的一些分词工具来进行分词处理。在处理词类时一般关注词性、词与上下文之间是否有强联系之类的问题。统计分词word前后word的分布概率,通过P(pre_word|word)等合并成词概率高的词。
N-gram特征统计
N-gram模型是一种语言模型,语言模型是一个基于概率的判别模型,他的输入是一句话(单词的顺序序列),输出的是这句话的概率,即这些单词的联合概率

N-gram的特点:
- 某个词的出现依赖于其他若干个词
- 我们获得信息越多,预测越准确
N-gram本身也指一个由N个单词组成的集合,各单词具有先后顺序,且不要求单词之间互不相同。常用的有 Bi-gram (N=2) 和 Tri-gram (N=3),一般已经够用了。例如在上面这句话里,我可以分解的 Bi-gram 和 Tri-gram :
Bi-gram : {I, love}, {love, deep}, {love, deep}, {deep, learning}
Tri-gram : {I, love, deep}, {love, deep, learning}
N-gram中的概率计算
假设我们有一个由n个词组成的句子
S
=
(
ω
1
,
ω
2
,
.
.
.
.
.
.
,
ω
n
)
S=(\omega_1,\omega_2,......,\omega_n)
S=(ω1,ω2,......,ωn),如何衡量他的概率呢?假设每个单词
ω
i
\omega_i
ωi都要依赖于从第一个单词
ω
1
\omega_1
ω1到它之前一个单词
ω
i
=
1
\omega_{i=1}
ωi=1的影响:
p
(
S
)
=
p
(
ω
1
ω
2
.
.
.
ω
n
)
=
p
(
ω
1
)
p
(
ω
2
∣
ω
1
)
.
.
.
p
(
ω
n
∣
ω
n
−
1
.
.
.
ω
2
ω
1
)
p(S)=p(\omega_1\omega_2...\omega_n) = p(\omega_1)p(\omega_2|\omega_1)...p(\omega_n|\omega_{n-1}...\omega_2\omega_1)
p(S)=p(ω1ω2...ωn)=p(ω1)p(ω2∣ω1)...p(ωn∣ωn−1...ω2ω1)
这个衡量方法存在两个缺陷:
- 参数空间过大:概率 p ( ω n ∣ ω n − 1 . . . ω 2 ω 1 ) p(\omega_n|\omega_{n-1}...\omega_2\omega_1) p(ωn∣ωn−1...ω2ω1)的参数有O(n)个
- 数据稀疏严重,词同时出现的情况可能没有,组合阶数高时尤其明显
解决第一个问题–引入马尔科夫假设:一个词的出现仅与它之前若干个词有关
- 如果一个词的出现仅依赖于他前面出现的一个词,就是Bi-gram
p ( S ) = p ( ω 1 ω 2 . . . ω n ) = p ( ω 1 ) p ( ω 2 ∣ ω 1 ) . . . p ( ω n ∣ ω n − 1 ) p(S) = p(\omega_1\omega_2...\omega_n) = p(\omega_1)p(\omega_2|\omega_1)...p(\omega_n|\omega_{n-1}) p(S)=p(ω1ω2...ωn)=p(ω1)p(ω2∣ω1)...p(ωn∣ωn−1) - 如果一个词的出现仅依赖于他前面出现的一个词,就是Tri-gram
p ( S ) = p ( ω 1 ω 2 . . . ω n ) = p ( ω 1 ) p ( ω 2 ∣ ω 1 ) . . . p ( ω n ∣ ω n − 1 ω n − 1 ) p(S) = p(\omega_1\omega_2...\omega_n) = p(\omega_1)p(\omega_2|\omega_1)...p(\omega_n|\omega_{n-1}\omega_{n-1}) p(S)=p(ω1ω2...ωn)=p(ω1)p(ω2∣ω1)...p(ωn∣ωn−1ωn−1)
N-gram的N可以取很高,现实中一般Bi-gram和Tri-gram就够用了
极大似然估计求P
N-gram的用途
- 词性标注
- 垃圾短信分类
- 分词器机器翻译和语音识别
N-gram中N的确定
为了确定N的取值,《Language Modeling with Ngrams》使用了 Perplexity 这一指标,该指标越小表示一个语言模型的效果越好。
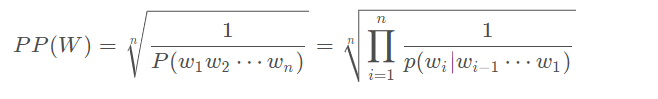
参考
https://blog.youkuaiyun.com/songbinxu/article/details/80209197

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









