机器学习CV代码练习(六)之图像描述-根据网络模型结构图训练网络
- 网络模型结构图1:
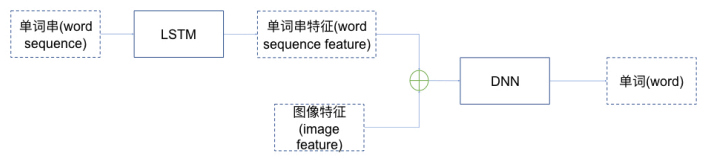
- 网络模型结构图2:
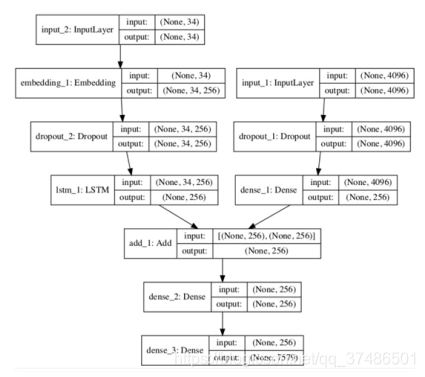
需要哪些层就去Keras的API文档中查找(Eg:Input、Embedding、Dropout、LSTM、Add)
def caption_model(vocab_size, max_len):
"""创建一个新的用于给图片生成标题的网络模型
Args:
vocab_size: 训练集中标题单词个数
max_len: 训练集中的标题最长长度
Returns:
用于给图像生成标题的网络模型
"""
input1 = Input(shape=(4096,))
dropout_1 = Dropout(0.5)(input1)
dense_1 = Dense(256,activation='relu')(dropout_1)
input2 = Input(shape=(max_len,))
embed_1 = Embedding(vocab_size,256)(input2)
lstm_1 = LSTM(256,activation='relu')(embed_1)
add_1 = add([dense_1,lstm_1])
dense_2 = Dense(256,activation='relu')(add_1)
outputs = Dense(vocab_size, activation='softmax')(dense_2)
model = Model(inputs=[input1,input2],outputs=outputs)
model.compile(loss='categorical_crossentropy',optimizer='adam')
return model
模型训练完整代码
from keras.utils import plot_model
from keras.models import Model
from keras.layers import Input
from keras.layers import Dense
from keras.layers import LSTM
from keras.layers import Embedding
from keras.layers import Dropout
from keras.layers.merge import add
from pickle import load
from keras.utils import to_categorical
from keras.preprocessing.sequence import pad_sequences
import util
from numpy import array
def create_batches(desc_list, photo_features, tokenizer, max_len, vocab_size=7378):
"""从输入的图片标题list和图片特征构造LSTM的一组输入
Args:
desc_list: 某一个图像对应的一组标题(一个list)
photo_features: 某一个图像对应的特征
tokenizer: 英文单词和整数转换的工具keras.preprocessing.text.Tokenizer
max_len: 训练数据集中最长的标题的长度
vocab_size: 训练集中的单词个数, 默认为7378
Returns:
tuple:
第一个元素为list, list的元素为图像的特征
第二个元素为list, list的元素为图像标题的前缀
第三个元素为list, list的元素为图像标题的下一个单词(根据图像特征和标题的前缀产生)
Examples:
#>>> from pickle import load
#>>> tokenizer = load(open('tokenizer.pkl', 'rb'))
#>>> desc_list = ['startseq one dog on desk endseq', "startseq red bird on tree endseq"]
#>>> photo_features = [0.434, 0.534, 0.212, 0.98]
#>>> print(create_batches(desc_list, photo_features, tokenizer, 6, 7378))
(array([[ 0.434, 0.534, 0.212, 0.98 ],
...,
[ 0.434, 0.534, 0.212, 0.98 ]]),
array([[ 0, 0, 0, 0, 0, 2],
[ 0, 0, 0, 0, 2, 59],
...,
[ 0, 0, 2, 26, 254, 6],
[ 0, 2, 26, 254, 6, 134]]),
array([[ 0., 0., 0., ..., 0., 0., 0.],
[ 0., 0., 0., ..., 0., 0., 0.],
...,
[ 0., 0., 0., ..., 0., 0., 0.]]))
"""
X1, X2, y = list(), list(), list()
for desc in desc_list:
seq = tokenizer.texts_to_sequences([desc])[0]
for i in range(1, len(seq)):
in_seq, out_seq = seq[:i], seq[i]
in_seq = pad_sequences([in_seq], maxlen=max_len)[0]
out_seq = to_categorical([out_seq], num_classes=vocab_size)[0]
X1.append(photo_features)
X2.append(in_seq)
y.append(out_seq)
return array(X1), array(X2), array(y)
def data_generator(captions, photo_features, tokenizer, max_len):
"""创建一个训练数据生成器, 用于传入模型训练函数的第一个参数model.fit_generator(generator,...)
Args:
captions: dict, key为图像名(不包含.jpg后缀), value为list, 图像的几个训练标题
photo_features: dict, key为图像名(不包含.jpg后缀), value为图像的特征
tokenizer: 英文单词和整数转换的工具keras.preprocessing.text.Tokenizer
max_len: 训练集中的标题最长长度
Returns:
generator, 使用yield [[list, 元素为图像特征, list, 元素为输入的图像标题前缀], list, 元素为预期的输出图像标题的下一个单词]
"""
while 1:
for key, desc_list in captions.items():
photo_feature = photo_features[key]
in_img, in_seq, out_word = create_batches(desc_list, photo_feature, tokenizer, max_len)
yield [[in_img, in_seq], out_word]
def caption_model(vocab_size, max_len):
"""创建一个新的用于给图片生成标题的网络模型
Args:
vocab_size: 训练集中标题单词个数
max_len: 训练集中的标题最长长度
Returns:
用于给图像生成标题的网络模型
"""
input1 = Input(shape=(4096,))
dropout_1 = Dropout(0.5)(input1)
dense_1 = Dense(256,activation='relu')(dropout_1)
input2 = Input(shape=(max_len,))
embed_1 = Embedding(vocab_size,256)(input2)
lstm_1 = LSTM(256,activation='relu')(embed_1)
add_1 = add([dense_1,lstm_1])
dense_2 = Dense(256,activation='relu')(add_1)
outputs = Dense(vocab_size, activation='softmax')(dense_2)
model = Model(inputs=[input1,input2],outputs=outputs)
model.compile(loss='categorical_crossentropy',optimizer='adam')
model.summary()
return model
def train():
filename = 'Flickr_8k.trainImages.txt'
train = util.load_ids(filename)
print('Dataset: %d' % len(train))
train_captions = util.load_clean_captions('descriptions.txt', train)
print('Captions: train number=%d' % len(train_captions))
train_features = util.load_photo_features('features.pkl', train)
print('Photos: train=%d' % len(train_features))
tokenizer = load(open('tokenizer.pkl', 'rb'))
vocab_size = len(tokenizer.word_index) + 1
print('Vocabulary Size: %d' % vocab_size)
max_len = util.get_max_length(train_captions)
print('Description Length: %d' % max_len)
model = caption_model(vocab_size, max_len)
print("load model...")
epochs = 20
steps = len(train_captions)
for i in range(epochs):
generator = data_generator(train_captions, train_features, tokenizer, max_len)
print(i,generator)
model.fit_generator(generator, epochs=1, steps_per_epoch=steps, verbose=1)
model.save('model_' + str(i) + '.h5')
if __name__ == "__main__":
train()



























 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











