




 本文详细介绍智能对话系统的训练流程,包括数据收集、清洗、分类和标注,对话模型配置与评估,以及效果优化策略。强调了智能对话训练师的角色与能力要求。
本文详细介绍智能对话系统的训练流程,包括数据收集、清洗、分类和标注,对话模型配置与评估,以及效果优化策略。强调了智能对话训练师的角色与能力要求。
百度技术学院-智能对话训练师视频链接:https://bit.baidu.com/productsBuy?id=108
百度技术学院-智能对话训练师学习笔记
智能对话市场与就业前景
智能对话训练师的职责
一:收集真实场景下的问法及相关数据并进行数据的清洗、分类和标注
二:配置出可用的对话模型,并合理评估出对话效果
三:能够持续优化模型、不断提升技能的对话理解效果
智能对话训练师的能力要求
一:数据处理-从数据中分析出关键的信息,数据清洗、分类、标注
二:行业背景-了解专业术语知识
三:AI技术边界:清楚知道可以实现什么、不能实现什么
四:AI行业思考:设计相应方案
智能对话系统概念整体介绍
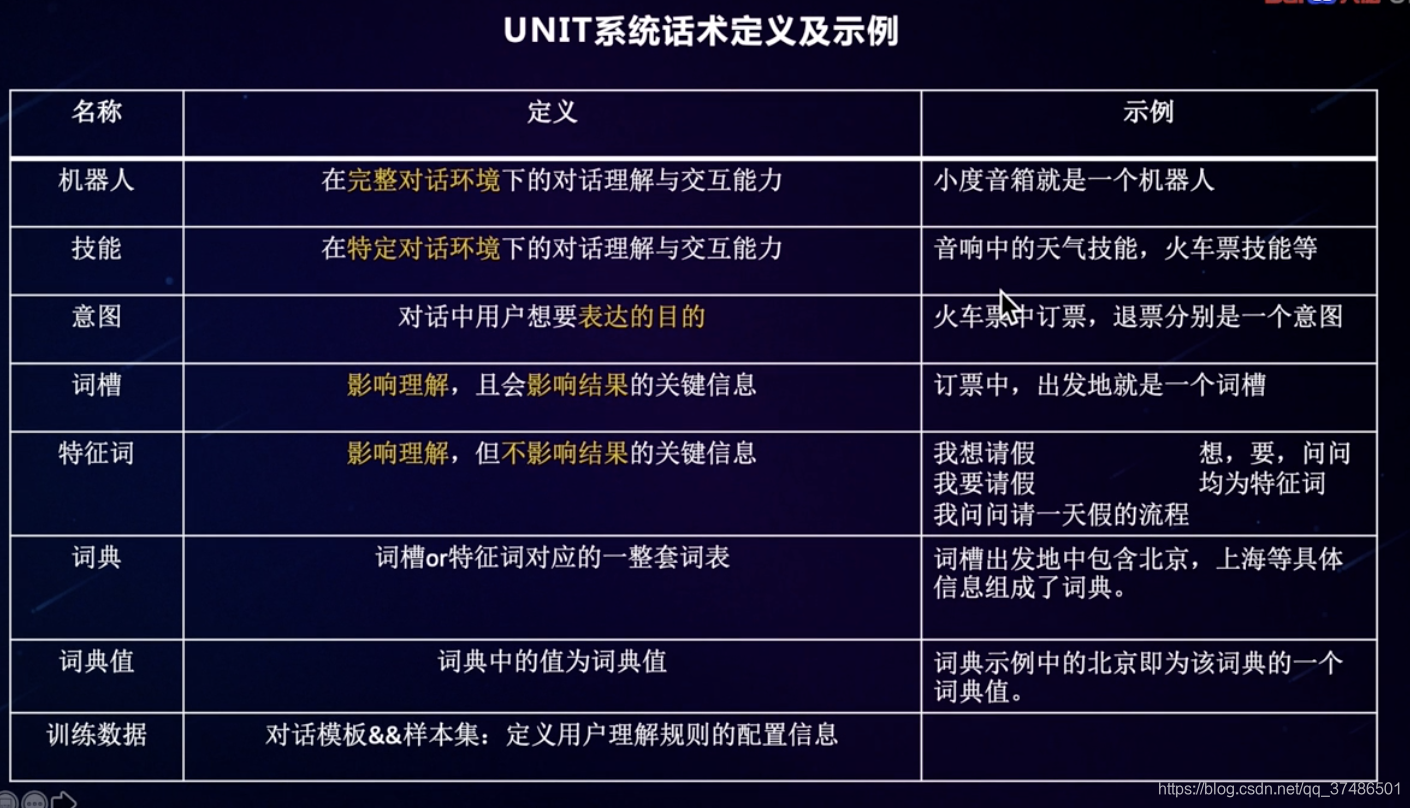
UNIT知识体系及术语介绍
Query:用户的话/请求
INTENT:用户话的目的/意图
SLOT:用户话中的关键信息(称之为:词槽)
UNIT机器人功能介绍
百度UNIT机器人:http://unit.baidu.com
UNIT技能等相关功能介绍
- 问答技能: FAQ–Question and Answer
技能需要:先训练-再测试
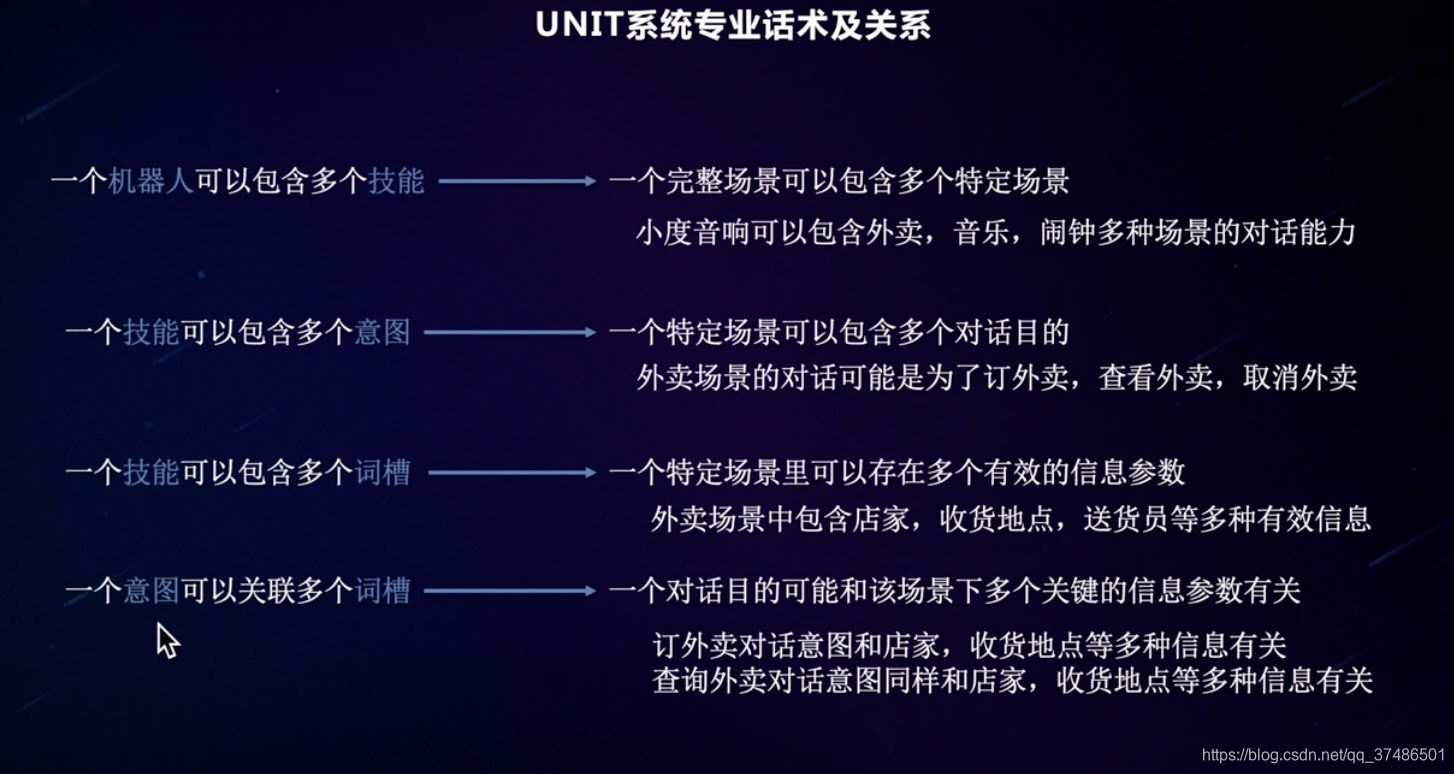
UNIT具有泛化内容 - 对话技能:包含意图(多个词槽)
根据业务选择词槽
UNIT训练数据功能介绍
- 训练数据-对话模版-对话样本集(配置模版)
- 技能训练
UNIT优化工具能力介绍
- 交互学习日志(局限性)–生僻的问法句子加入到训练数据中;
- 对话日志–重点关注未识别failure的部分
clarify命中意图,需要澄清词槽
satisfy对话完成,收集完成所有信息
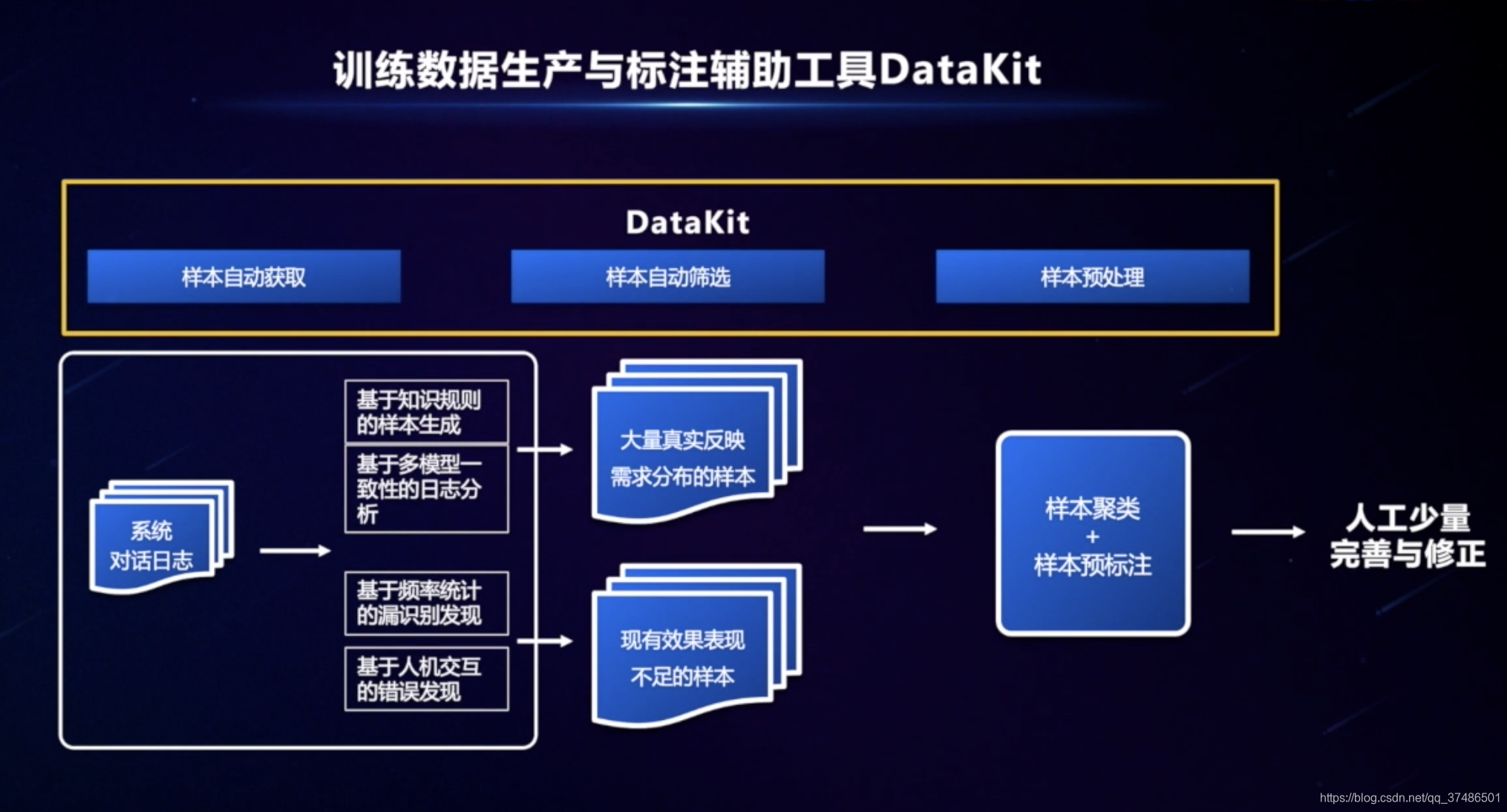
failure模型识别不到的query - DataKit-训练数据生产与标注辅助工具
样本自动获取、样本自动筛选、样本预处理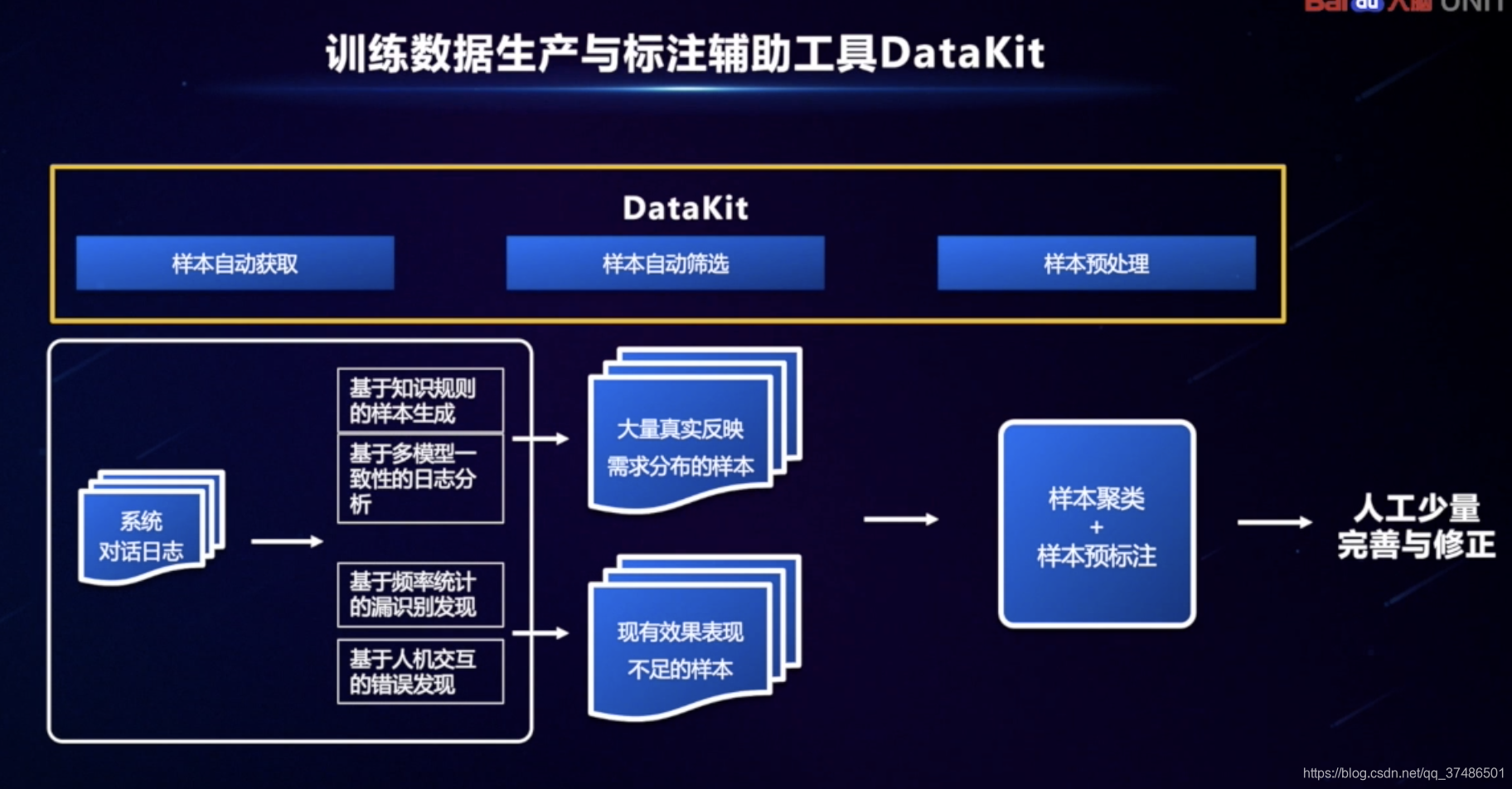
如何处理对话语料
- 场景数据收集: 任务型、问答型
- 数据清洗:剔除无效数据,保留有效数据
有效数据:句式、信息量、问法
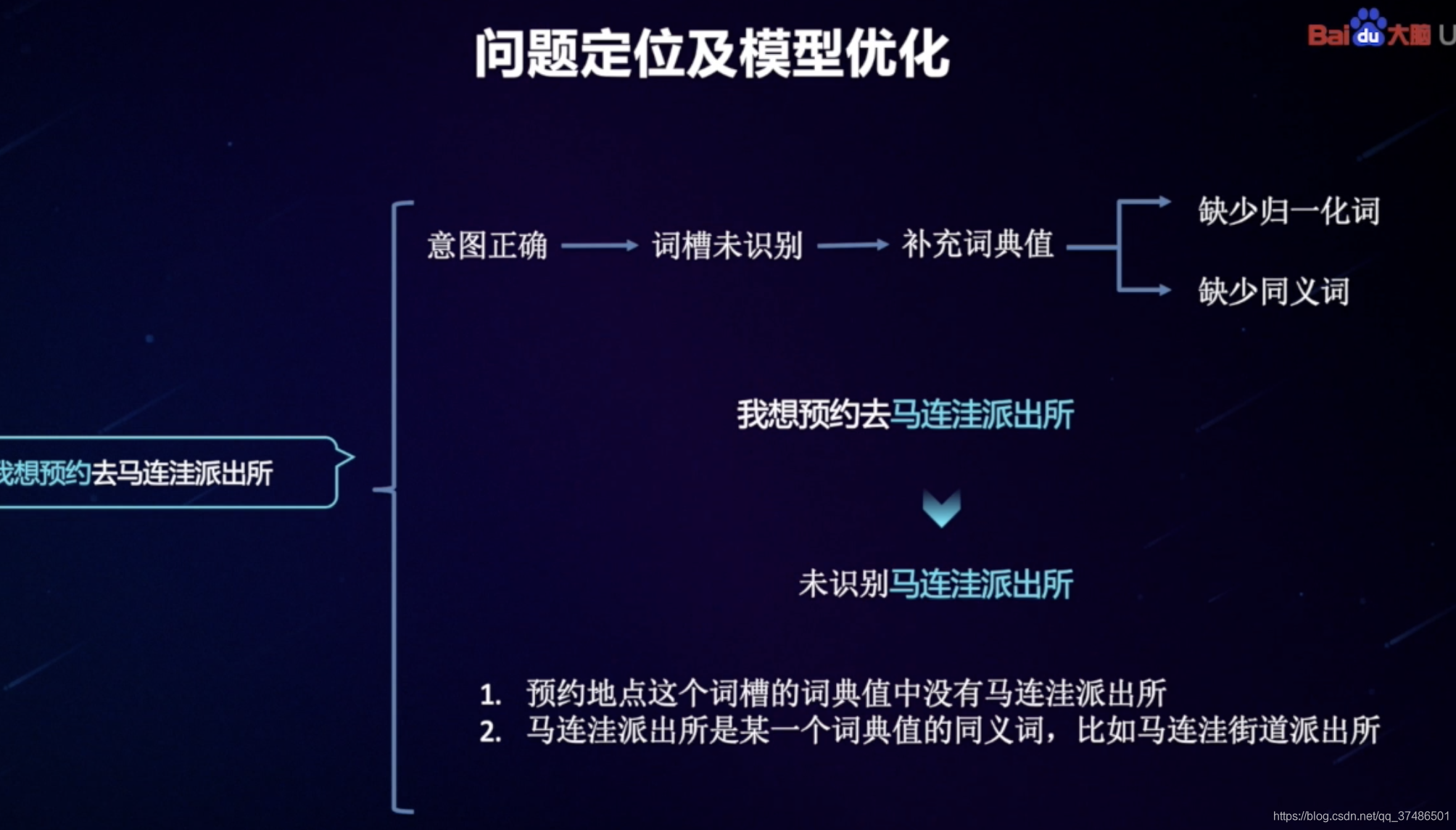
无效数据:直接替换词槽词典值、存在歧义 - 数据分类
- 关键数据标注(参数标注出来,词槽标注)
- 词槽提取及词典值方案确认
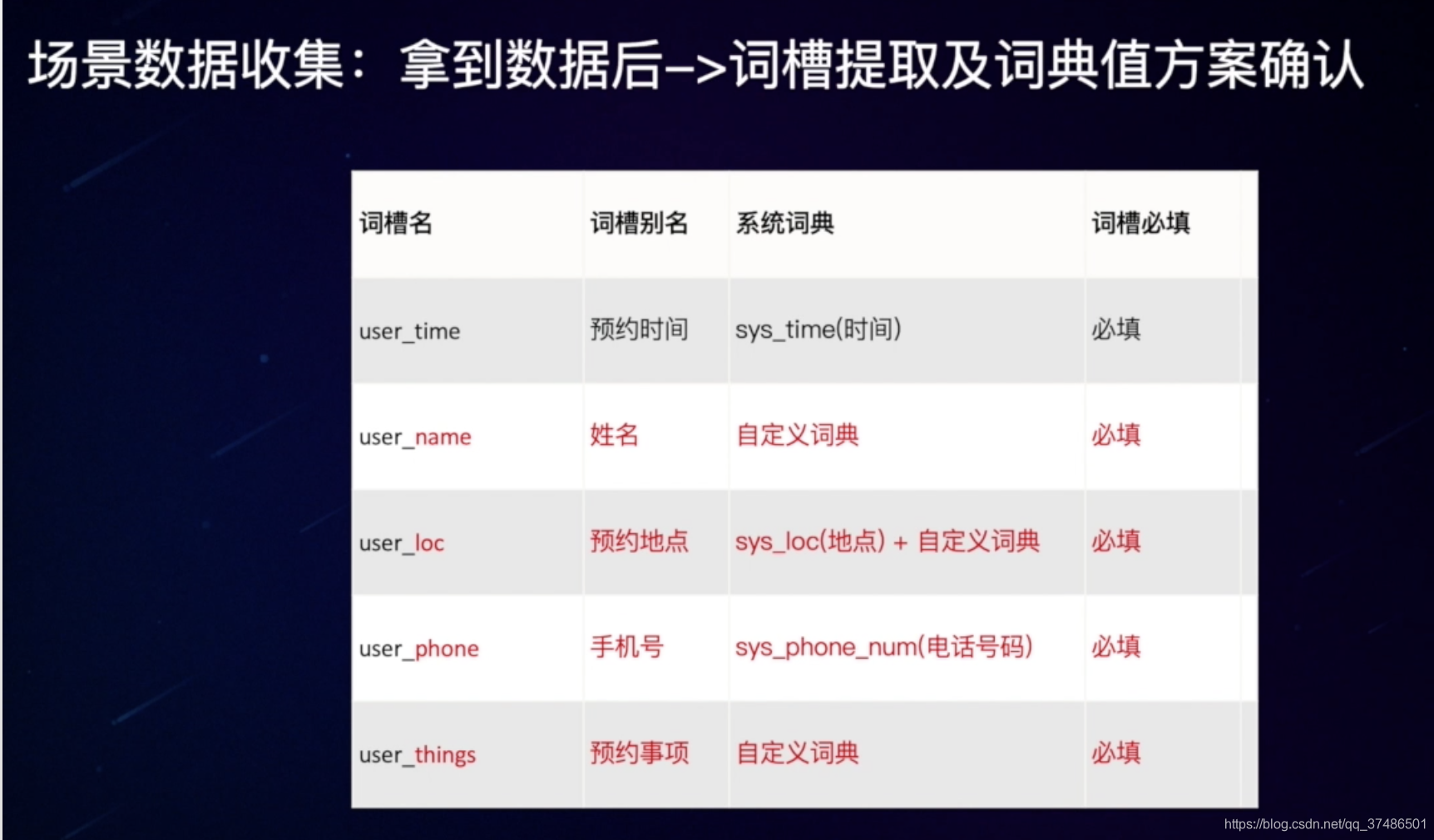
- 场景数据的三种使用方式:开发集、评估集、测试集(数据不足,优先保证开发集、测试集)

- 富集数据能力不同的解决方案

如何定义一个对话系统
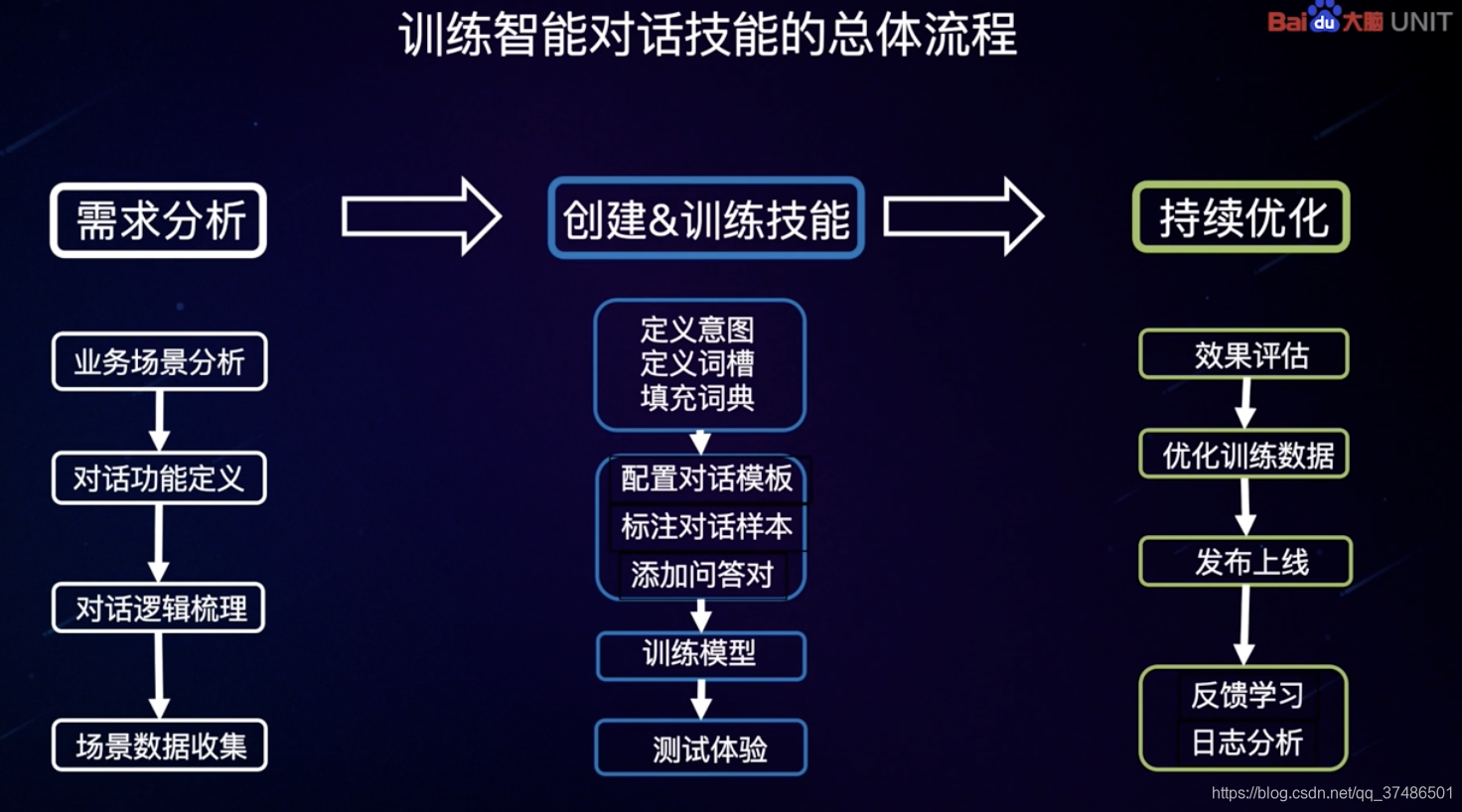
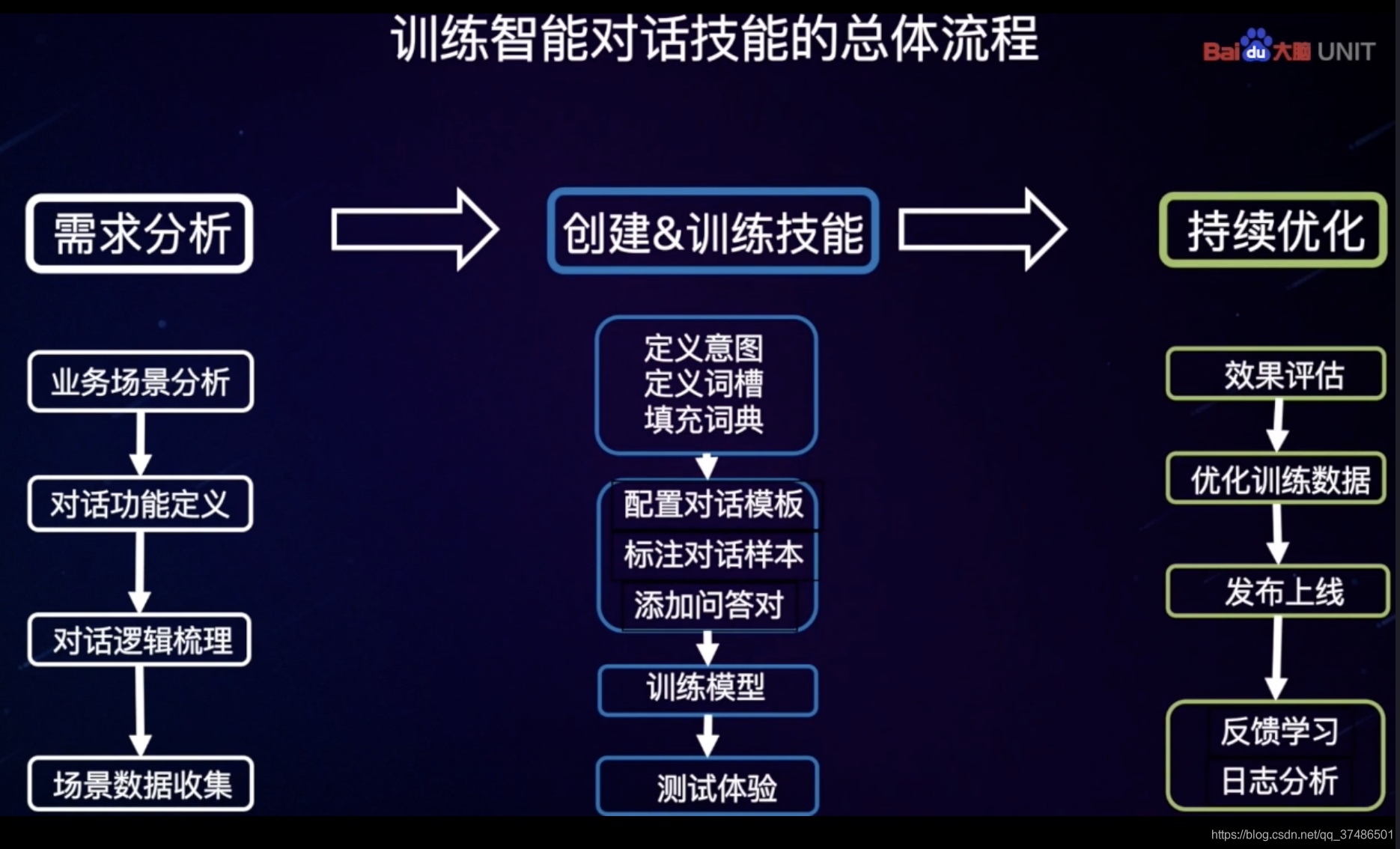
训练智能对话技能的总体流程:
需求分析:对话场景确认-需求要做什么-需要哪些信息
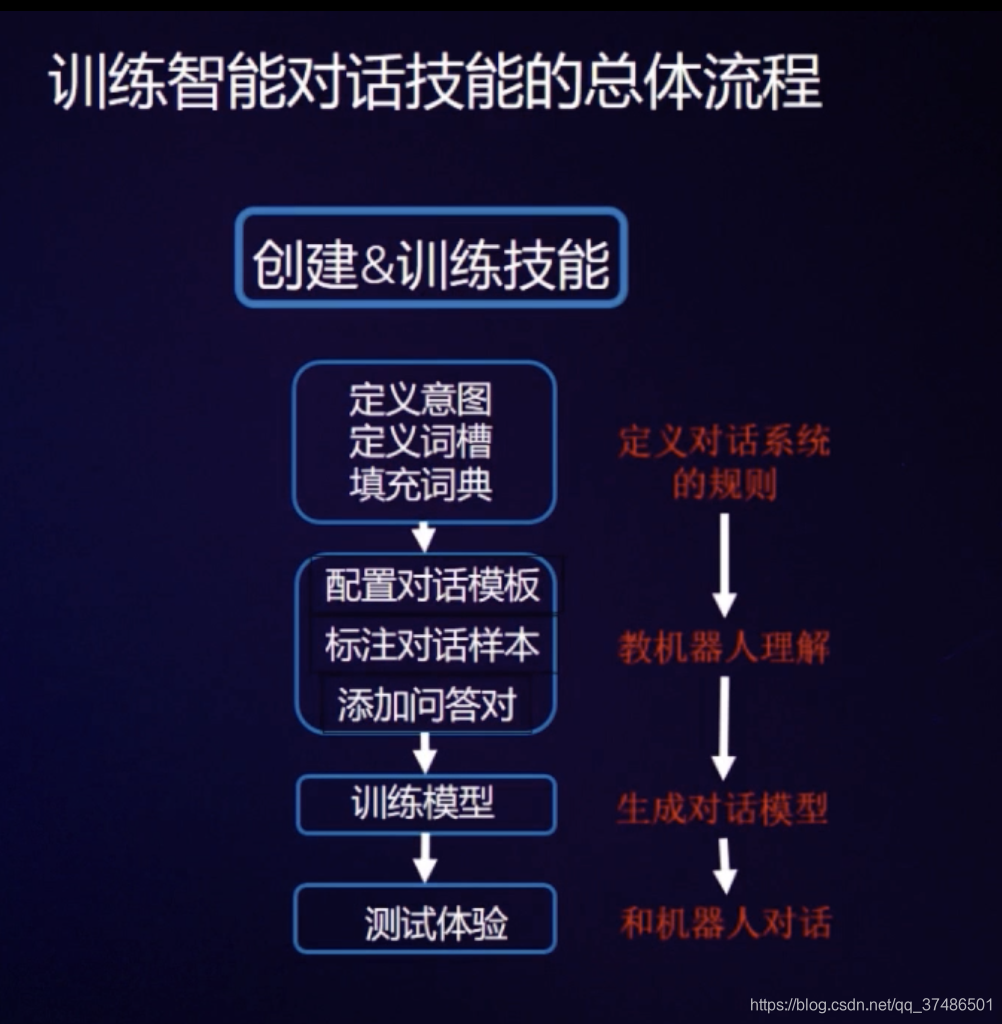
创建训练技能
持续优化
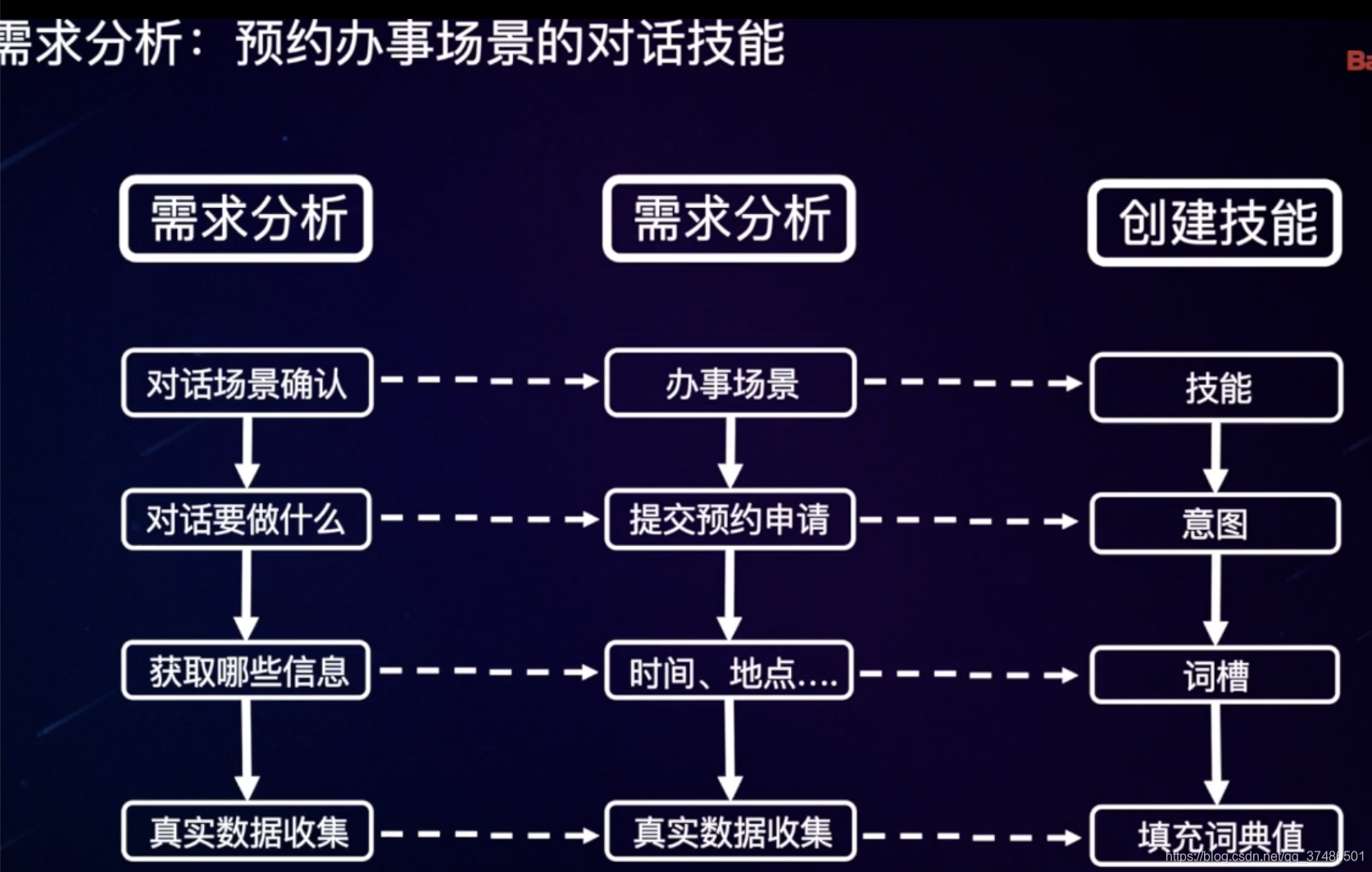
预约办事场景的对话技能:
意图(预约)-预约申请所包含的词槽

如何配置训练数据
训练数据:用数据教会机器人你定义的对话技能。
已完成:添加技能-添加技能里对应的意图及词槽-定义整个对话系统-训练数据(教会机器人你定义的对话技能)
训练策略:快速生效、深度训练
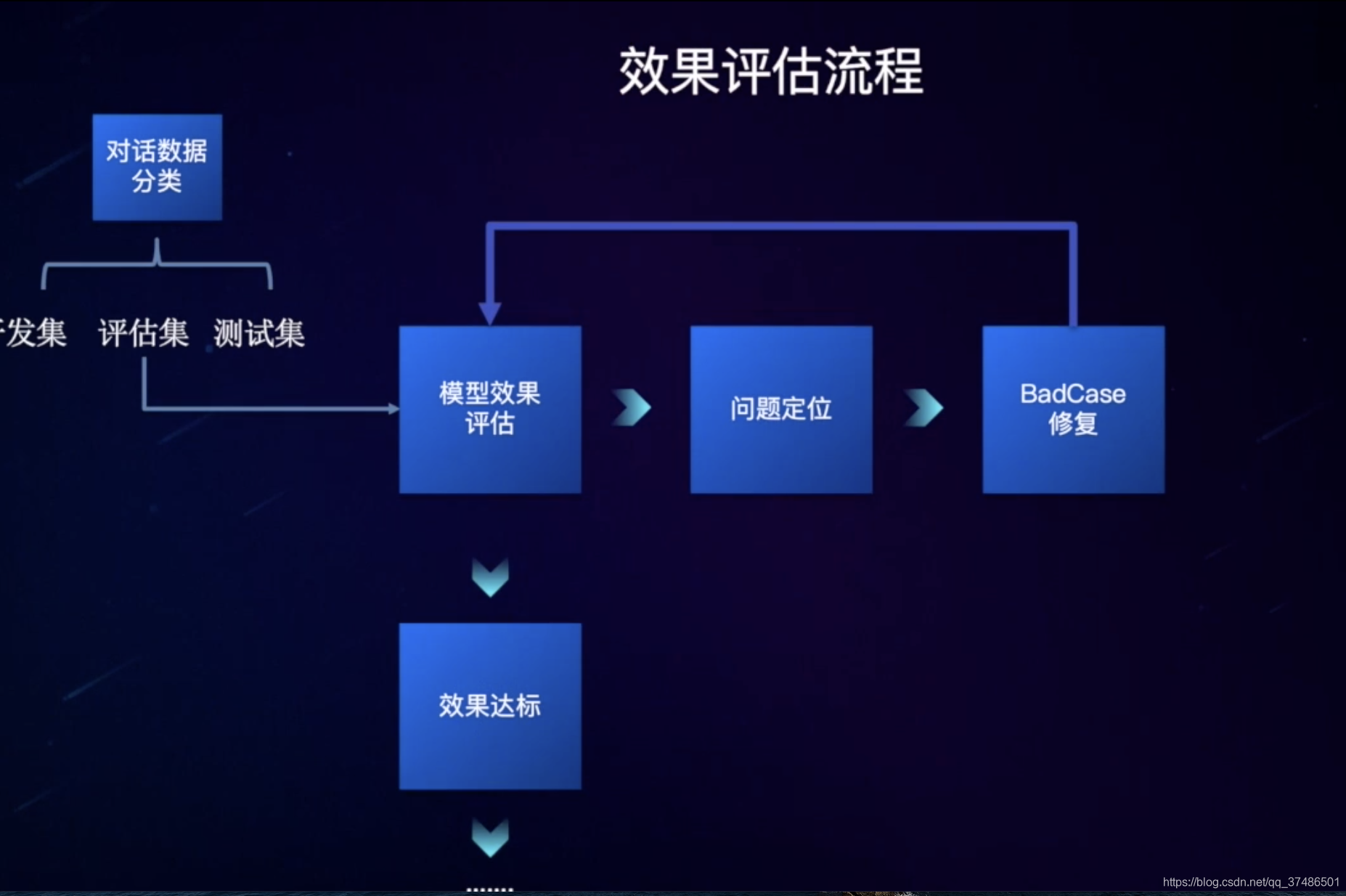
如何进行效果评估
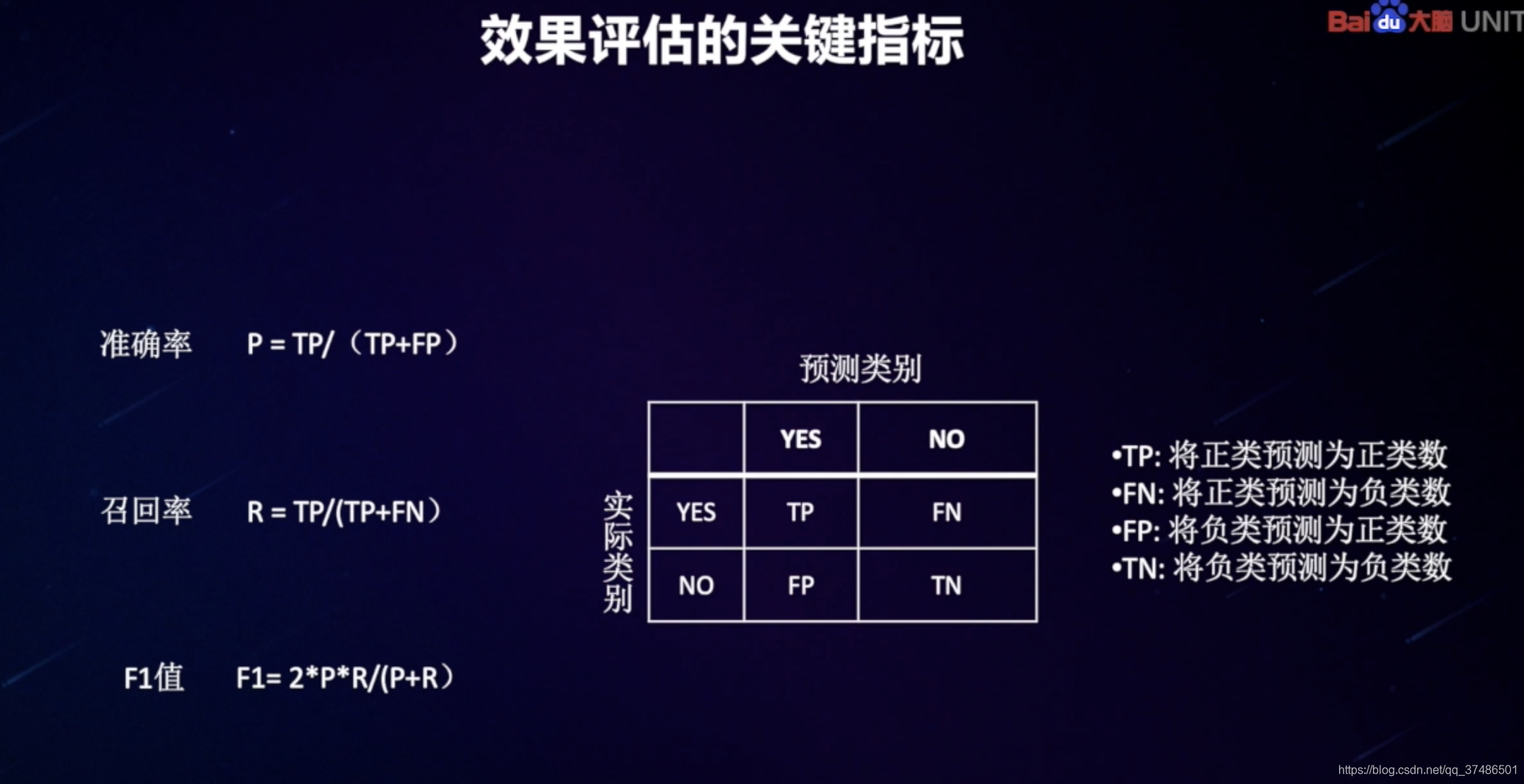
平台提供的测试工具评估对话效果,根据准确率和召回率判断后续优化的方向。
评估集文件要求:
txt文件,一行一个样本,顺序依次为:query,意图,词槽。三者之间以’\t’分隔,词槽之间以’###’分隔,编码为utf-8。再次提醒,评估样本建议为真实场景下的样本,请勿凭空构造。评估集中的每条样本都要标注意图、词槽(没有词槽的只标意图),其中正例样本是指需要识别为场景中意图的样本,例如上面评估查天气的BOT的评估样本中意图为ASK_WEATHER的都是正例样本。而对于当前bot对应场景不应该识别的对话 都可以标为负例样本,同系统预置的负例意图SYS_OTHER 表示。
帮助文档:https://ai.baidu.com/forum/topic/show/870435
效果优化与线上运营迭代
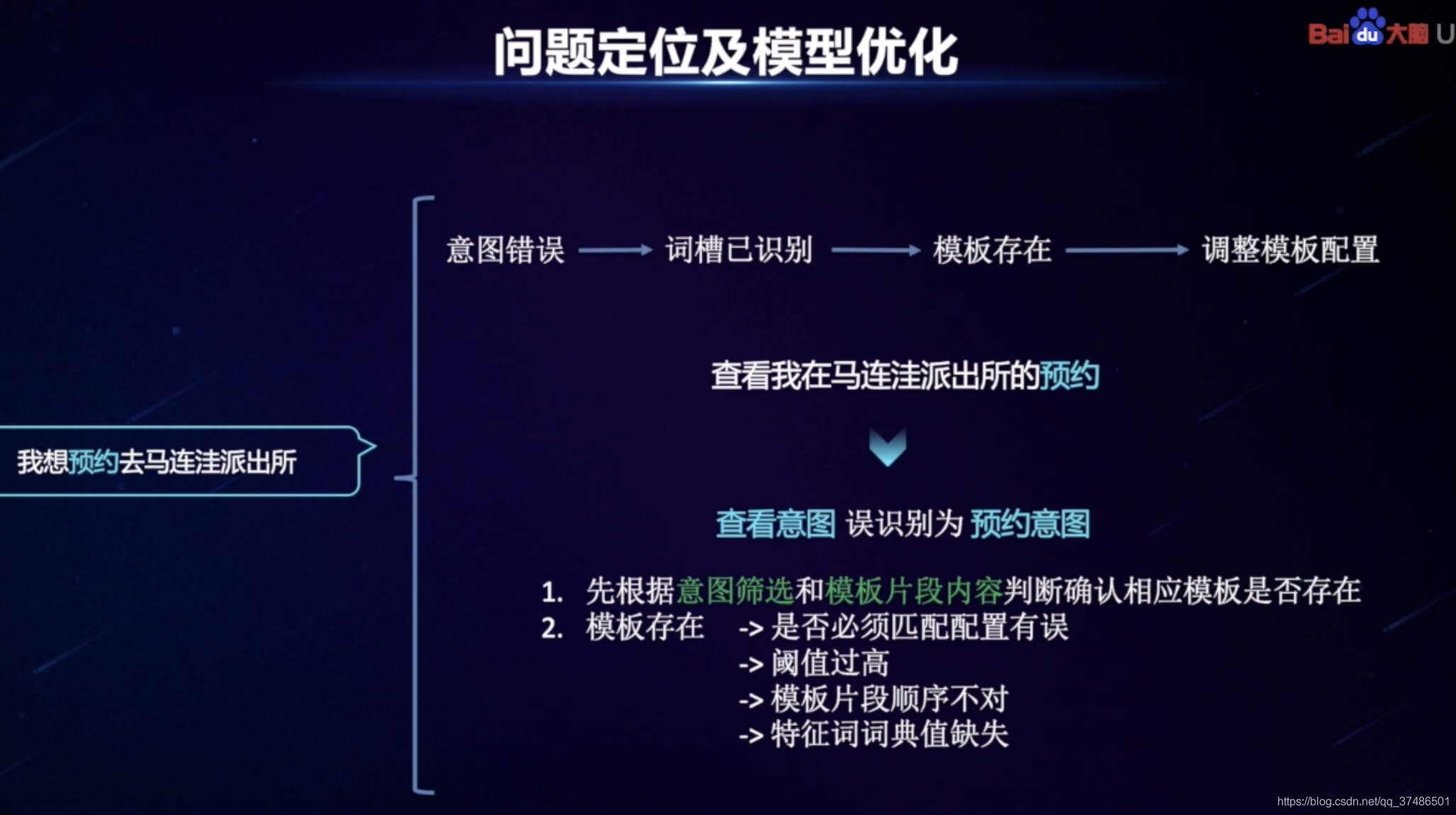
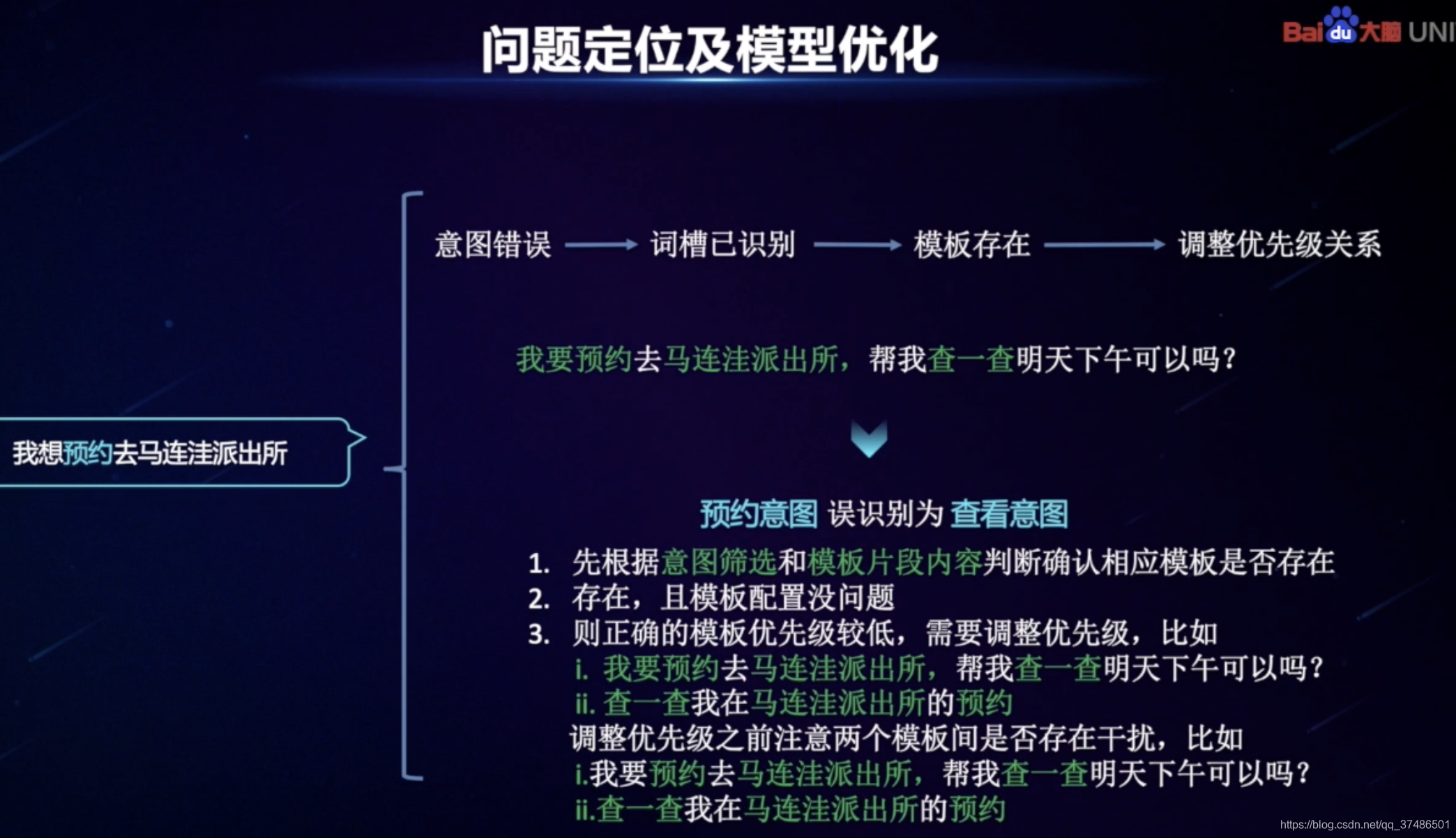
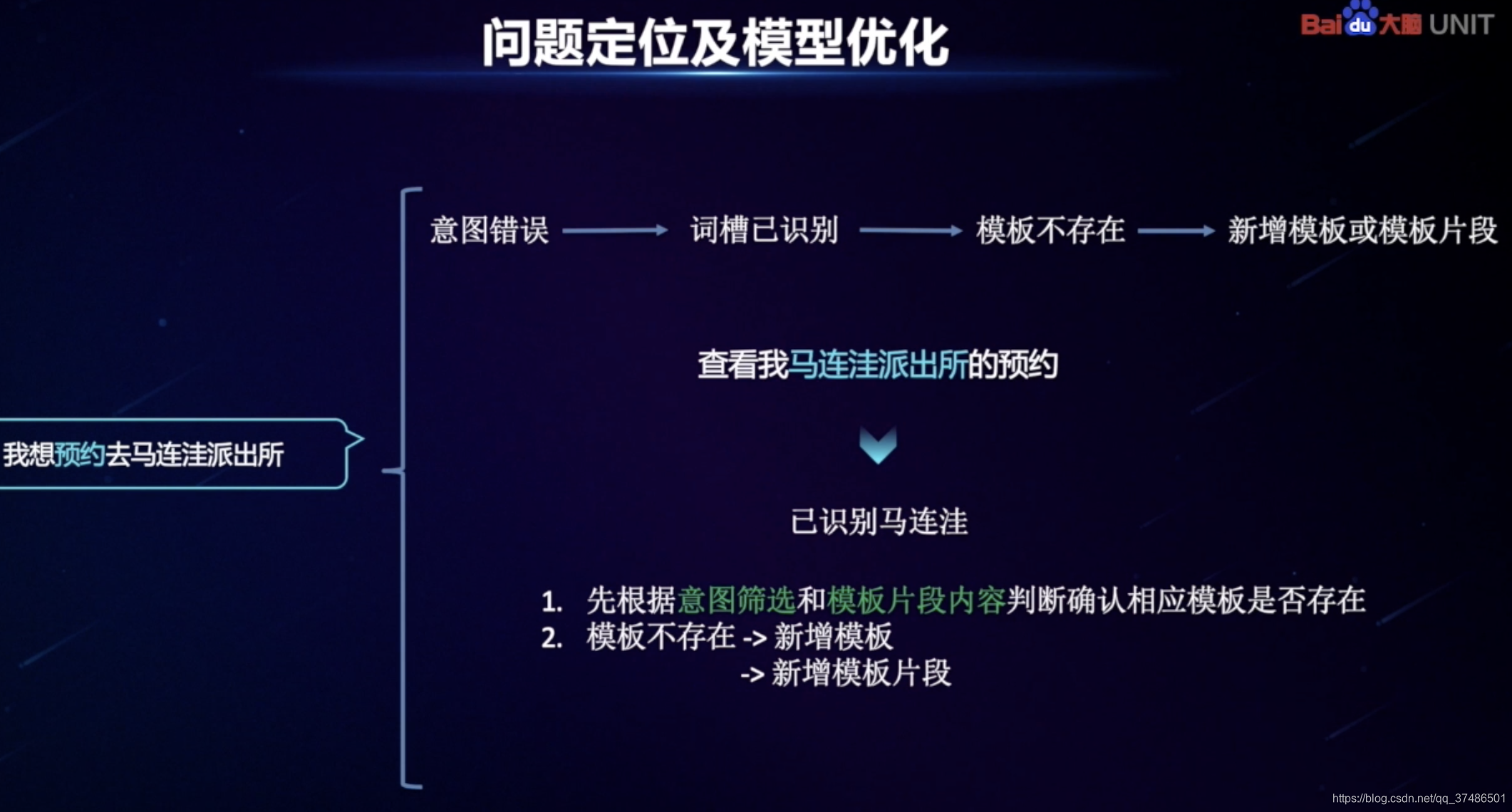
对话测试窗口,线上实时对话,可查看完整接口返回的JSON数据,定位问题。
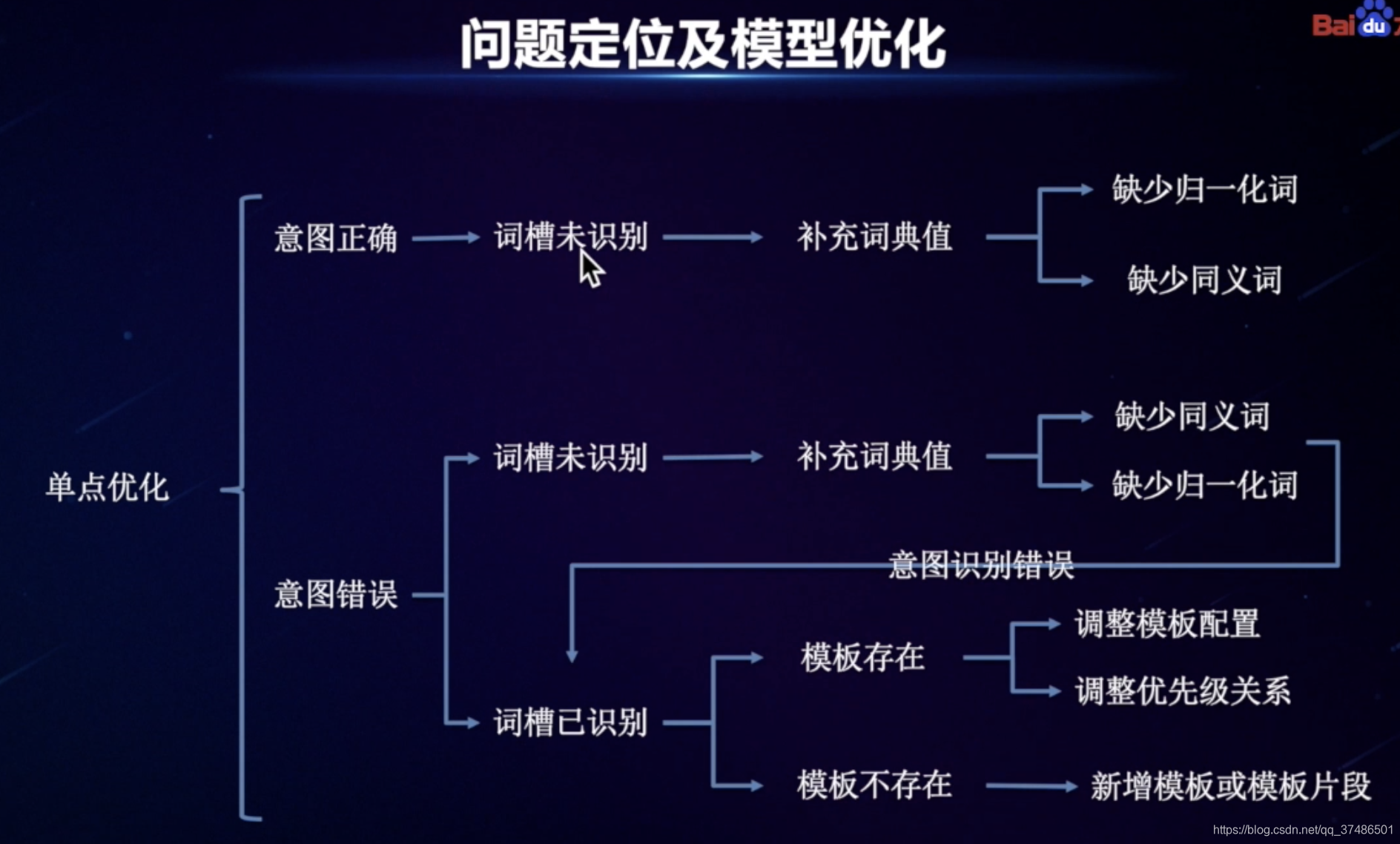
正常:识别出意图-词槽-做出澄清回复。
错误:不理解句子时,需要查看JSON数据(schema、qu_res重点看、action_list),其中qu_res中的“lexical_analysis”有这条Query的具体解析结果,etypes中没有命中词槽说明词典值没有被识别;etypes中有命中词槽说明词槽有被识别。
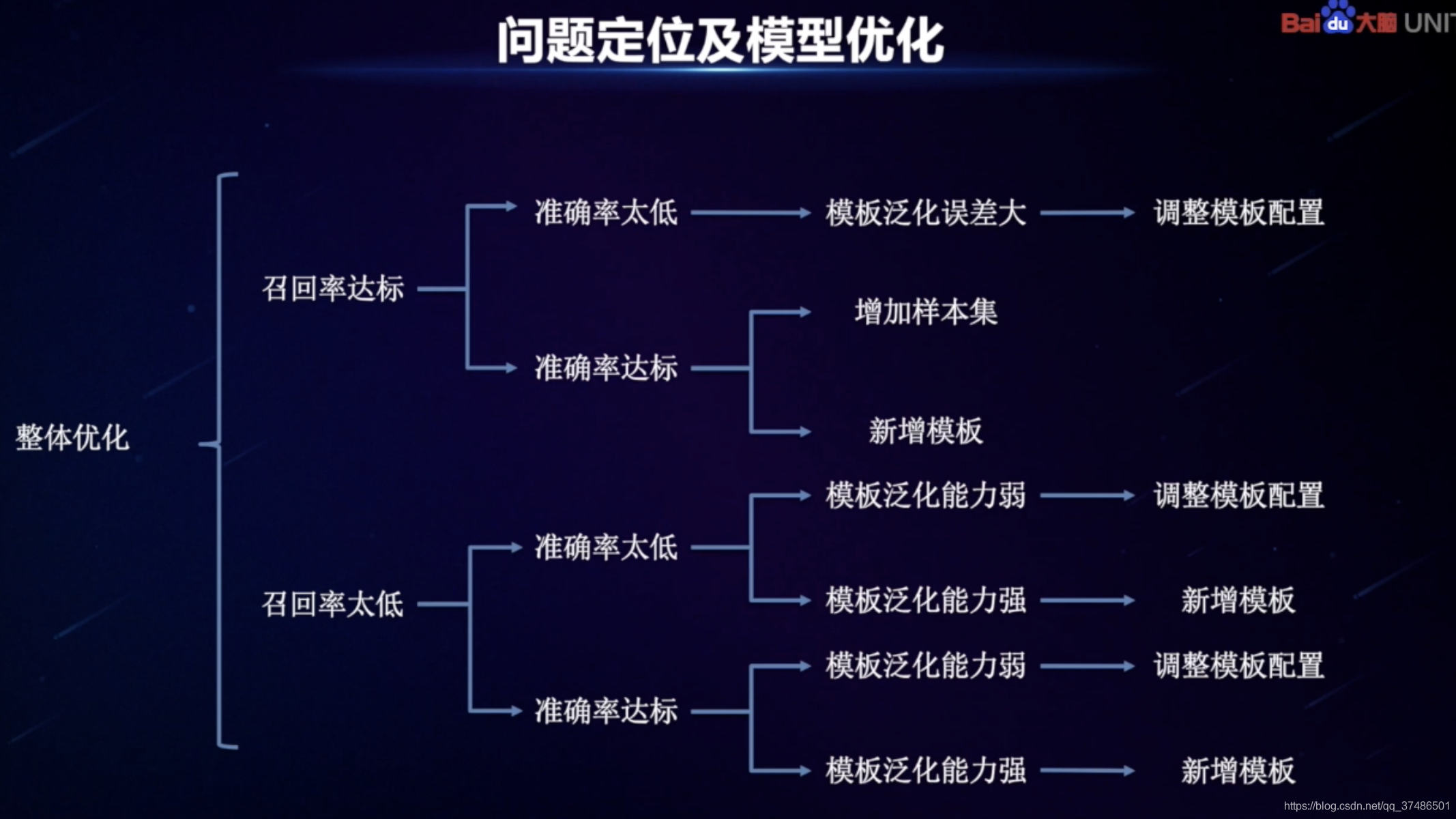
通常建议:召回率80%、准确率90%达标。
交互学习日志(优先级低)
对话日志
DataKit(线上优化迭代,模型已经达到了较好的泛化效果,提升时才可以用到):目标是帮助大家低成本地把模型理解效果从80分往90分,从90分往95分去优化。
补充ing
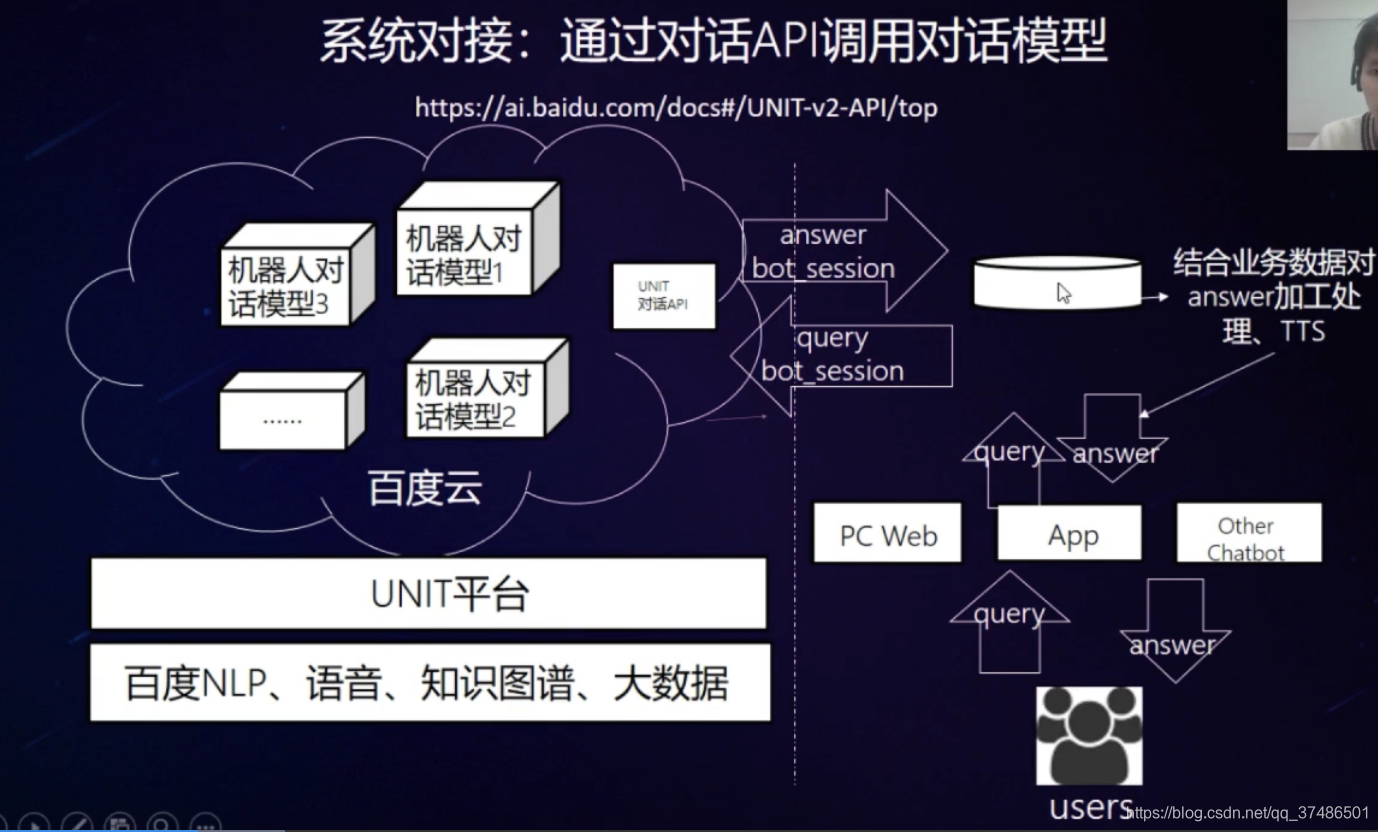
系统对接
对话模版:用户常用的语言表述规则,通过不同的用法,可以实现对不同形态的query的解析。
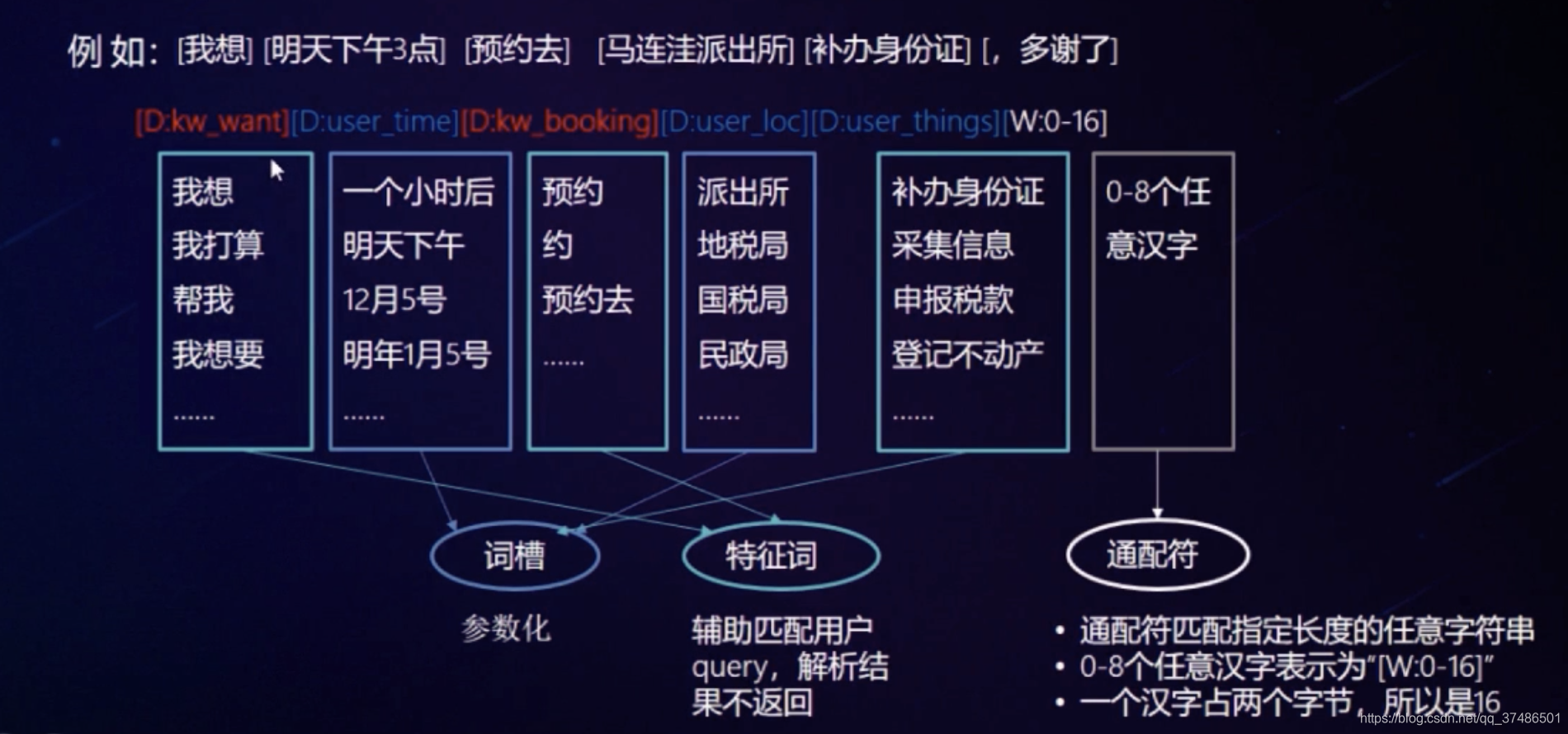
对话样本:把需求分析阶段手机的对话样本导入样本集,进行意图和词槽的标注。
三种训练数据该如何选择?

单个技能中对话可以正确识别意图,但是和机器人对话就不能正确识别意图。–由于用到了干预学习能力,干预学习能力需要加入到训练数据中进行训练后,才可以在其他地方使用的。
Unit有自动获取对话样本集的功能,起码要很多条数据以上,才会有作用。
样本集怎样帮助机器人理解的呢,什么原理?–深度学习算法训练出的模型


















 874
874

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











