







概率基础
1概率定义
- 概率定义为一件事情发生的可能性
- 扔出一个硬币,结果头像朝上
- P(X):取值在[0,1]
2女神是否喜欢计算案例
在讲这两个概率之前我们通过一个例子,来计算一些结果:
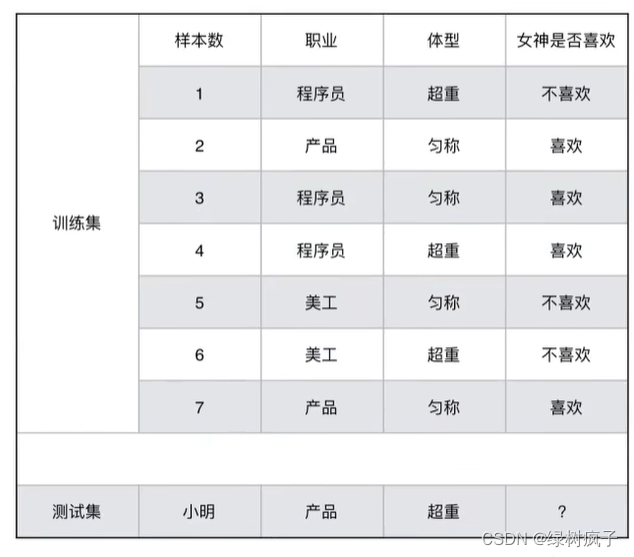
-
问题如下:
1、女神喜欢的概率?
2、职业是程序员并且体型匀称的概率?
3、在女神喜欢的条件下,职业是程序员的概率?
4、在女神喜欢的条件下,职业是程序员,体重是超重的概率? -
计算结果为:
P(喜欢)=4/7
P(程序员,匀称)=1/7
P(程序员|喜欢)=2/4 = 1/2
P(程序员,超重|喜欢)=1/4
联合概率、条件概率与相互独立
- 联合概率:包含多个条件,且所有条件同时成立的概率
- 记作:P(A,B)
- 例如:P(程序员,匀称),P(程序员,超重|喜欢)
- 条件概率:就是事件A在另外一个事件B已经发生条件下的发生概率
- 记作:P(A|B)
- 例如:P(程序员|喜欢),P(程序员,超重|喜欢)
- 相互独立:如果P(A,B)=P(A)P(B),则称事件A与事件B相互独立。
贝叶斯公式
1公式
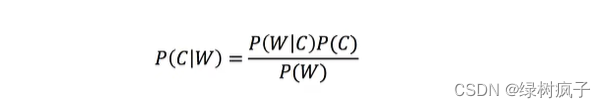
注:W为给定文档的特征值(频数统计,预测文档提供),C为文档类别。
2实例计算




即:
P(喜欢|产品,超重)=P(产品,超重|喜欢)P(喜欢)/P(产品,超重)
上式中,P(产品,超重|喜欢)和P(产品,超重)的结果均为0,导致无法计算结果。这是因为样本量太少了,不具有代表性,本来现实生活中,肯定是存在职业是产品经理并且体重超重的人的,P(产品,超重)不可能为0;而且事件“职业是产品经理”和事件“体重超重”通常被认为是相互独立的事件,但是,根据我们有限的7个样本计算“P(产品,超重)=P(产品)P(超重)”不成立。
而朴素贝叶斯可以帮助我们解决这个问题
朴素贝叶斯,简单理解,就是假定了特征与特征之间相互独立的贝叶斯公式。也就是说,朴素贝叶斯,之所以朴素,就在于假定了特征与特征相互独立。
所以,思考题如果按照朴素贝叶斯的思路来解决,就可以是:
P(产品,超重)=P(产品)*P(超重):2/7*3/7=6/49
p(产品,超重|喜欢)=P(产品|喜欢)*P(超重|喜欢)=1/2*1/4=1/8
P(喜欢|产品,超重)=P(产品,超重|喜欢)P(喜欢)/P(产品,超重)=1/8 * 4/7 / 6/49 = 7/12
朴素:假定特征与特征之间是相互独立的
贝叶斯:贝叶斯公式
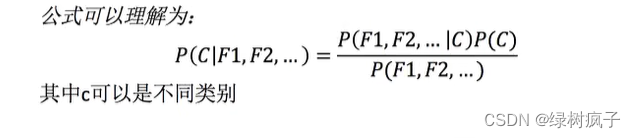
公式分为三个部分:
- P(C):每个文档类别的概率(某文档类别数/总文档数量)
- P(W | C):给定类别下特征((被预测文档中出现的词)的概率
- 计算方法:P(F1 | C)=Ni/N(训练文档中去计算)
- Ni为该F1词在C类别所有文档中出现的次数
- N为所属类别C下的文档所有词出现的次数和
- 计算方法:P(F1 | C)=Ni/N(训练文档中去计算)
- P(F1,F2…)预测文档中每个词的概率
如果计算两个类别概率比较:
所以我们只要比较前面的大小就可以,得出谁的概率大

















 329
329

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









