




 本文介绍了MapReduce的分布式运算原理,包括其作为离线处理框架的特点、核心的Map和Reduce阶段以及Master/Slave架构。详细阐述了MapReduce在Hadoop 1.x和2.x中的执行流程,分析了JobTracker、TaskTracker和Task的角色与交互,并对比了两代架构的区别,特别是Hadoop 2.x中引入的YARN框架和Resource Manager的高可用性改进。
本文介绍了MapReduce的分布式运算原理,包括其作为离线处理框架的特点、核心的Map和Reduce阶段以及Master/Slave架构。详细阐述了MapReduce在Hadoop 1.x和2.x中的执行流程,分析了JobTracker、TaskTracker和Task的角色与交互,并对比了两代架构的区别,特别是Hadoop 2.x中引入的YARN框架和Resource Manager的高可用性改进。
一.MapReduce简介
1.Mapreduce 是一个分布式运算程序的编程框架,适用于海量的数据离线处理,并且易于编程,有良好的扩展性,和高容错性。
2.Mapreduce 核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的 分布式运算程序,并发运行在一个 hadoop 集群上。
3.Mapreduce有两个阶段组成:Map和Reduce,用户只需实现map()和reduce()两个函数,即可实现分布式计算。
4.MapReduce框架采用了Master/Slave架构,包括一个Master和若干个Slave
二.Mapreduce的体系结构
1.Client:
用户编写的MapReduce程序通过Client提交到JobTracker端
用户可通过Client提供的一些接口查看该作业运行状态、
2.JobTracker:
JobTracker负责资源监控和作业调度
JobTracker监控所有TaskTracker与Job的健康状况,一旦发现失败,就将相应的任务转移到其他节点上
3.TaskTracker:
TaskTracker 会周期性地通过“心跳”将本节点上资源的使用情况和任务的运行进度汇报给JobTracker,同时接收JobTracker 发送过来的命令并执行相应的操作(如启动新任务、杀死任务等)
4.Task:
Task 分为Map Task 和Reduce Task 两种,都由TaskTracker 启动
三.Mapreduce架构和运行流程
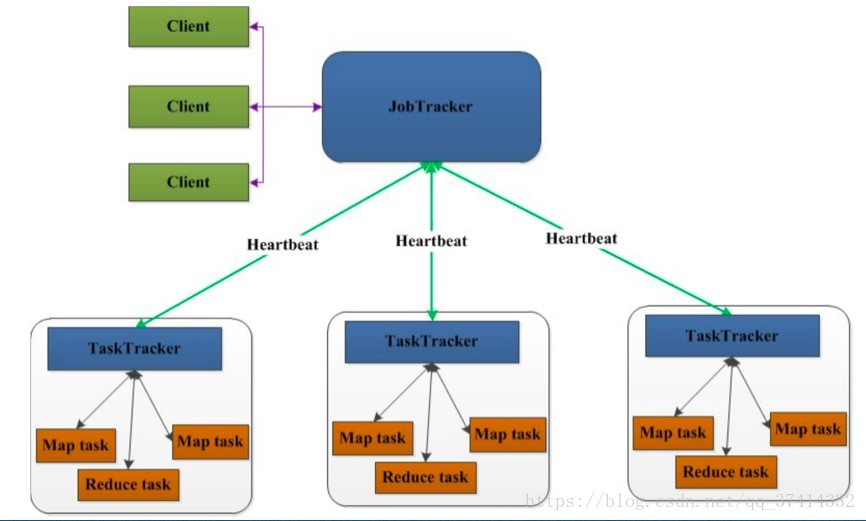
1.Mapreduce1.x的架构图
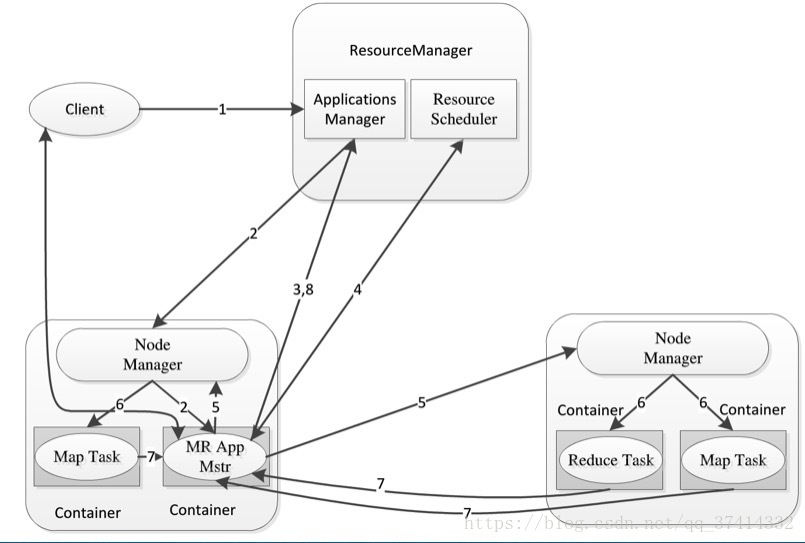
2.Mapreduce2.x的架构图
1)这里先介绍hadoop1.x mapreduce的执行流程:
client端提交job作业给jobtracker,然后jobtracker会给这个job分配资源,在tasktracker上启动task任务,并且还要监控task任务的运行状况,如果task挂了,jobtracker还得重新分配新的资源给挂了的task任务,当task执行完成后,jobtracker会为reduce任务分配资源,然后监控reduce的执行流程,最后执行完成输出。
2)然后是hadoop2.x mapreduce的执行流程:
client端会向resourcemanager提交一个job作业,提交完成后RM会通过它的组件Scheduler为这个作业分配一个Container(资源容器,包括,内存硬盘带宽等),Scheduler分配完成后RM会跟Container对应的NodeManager进行通信,要求在这个NM对应的Container启动ApplicationMaster,AM启动后会首先向RM把自己的信息注册,用户就可以通过RM来查询到该作业的运行情况,然后ApplicationsManager会和Schedule协调来为各个任务申请资源,一旦ApplicationMaster申请到资源后就要与对应的NodeManager通信,要求NM启动任务,NM启动任务后,开始作业,直到结束,释放资源。
通过架构图可以看出hadoop 2.x和1.x的架构差不了多少,但是他们的执行流程却完全不一样。hadoop 2.x 相比1.x 使用了yarn框架,这样使资源的调度和监控分开,然后实现了resourcemanager的HA(高可用)并且通过zkfc进程和zookeeper管理实现。

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









