







 本文介绍了大数据处理框架的重要性,重点关注数据质量的测评,包括数据质量的定义、数据预处理(数据清洗、数据集成/数据变换、数据规约)以及数据质量测评的方法和工具。同时,讨论了分布式数据模型,如Hadoop的特点和MapReduce的工作原理,并提到了单元测试工具MRUnit。最后,文章提及了大数据基准测试的测试方法和内容。
本文介绍了大数据处理框架的重要性,重点关注数据质量的测评,包括数据质量的定义、数据预处理(数据清洗、数据集成/数据变换、数据规约)以及数据质量测评的方法和工具。同时,讨论了分布式数据模型,如Hadoop的特点和MapReduce的工作原理,并提到了单元测试工具MRUnit。最后,文章提及了大数据基准测试的测试方法和内容。
以hadoop为代表的各种大数据框架不断涌现,这些数据处理框架方便了大数据应用的编写,但是由于数据来源的多样性、数据形式的多元化,使得数据质量存在较大的差异,不正确或者不一致的数据可能严重影响分析效果。
1.概述
大数据处理流程一般如下:使用相关工具对分布广泛的非结构化的数据源进行抽取和集成,采用合适的标准对结果进行统一存储,利用数据分析的相关技术分析存储的数据,从所存储的数据中选择有用的内容并通过恰当的方式提供给大数据应用。
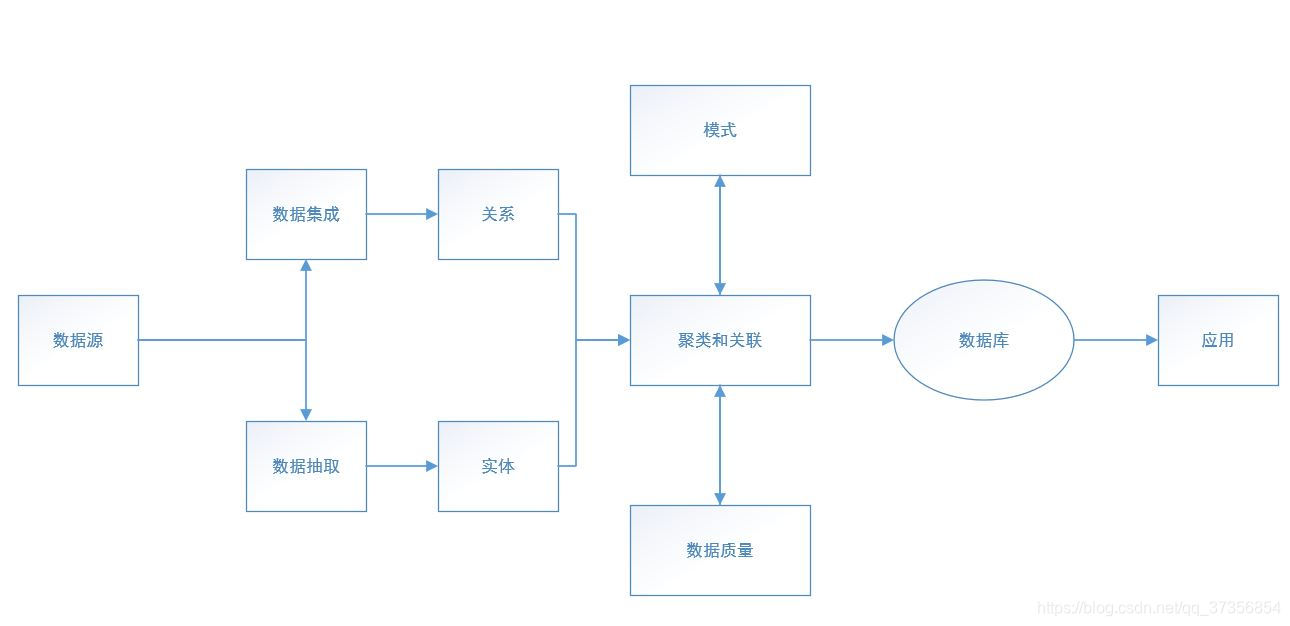
在处理大数据之前需要对来自不同数据源的数据做数据处理,包括数据抽取和数据集成。通过数据集成和数据抽取操作提取关系和实体,对其进行关联和聚类的相关操作后,采用统一定义的结构来存储这些数据。数据清洗发生在数据集成操作和数据抽取操作之前进行,保证数据质量和可行性。
数据处理的核心部分包括数据抽取、数据集成以及数据清洗数据抽取的相关研究在传统的数据库领域已经较为成熟,并且数据集成的相关方法也随新数据源的涌现而不断发展。目前数据抽取与集成的方式可以分为以下四种类型:基于物化或ETL方法引擎、基于数据流方法引擎以及基于搜索引擎的方法。数据清洗是指通过一定的规则将脏数据洗掉,规则包括检查数据一致性、处理无效性和缺失值等。
2.面向数据质量的测评
2.1数据质量
1)数据质量的定义
数据质量包括数据本身质量和数据过程质量。
- 数据真实性:数据真实并且准确地反映实际业务。
- 数据完备性:数据充分,没有遗漏任何有关的操作数据。
- 数据自治性:数据不是孤立存在的而是通过不同的约束互相关联,在满足数据之间关联关系的同时不违反相关的规定。
- 数据的使用质量:数据被正确的使用。
- 数据存储质量:数据被安全地存储在合适的介质中。
- 数据传输质量:在传输过程中数据传输地效率以及数据正确性。
2)数据质量问题的分类

很多单数据源诸如文件、web数据等,缺乏数据模式和统一的数据规范,因而更容易发生错误或者不一致问题。实例层问题在模式层次上是不可见的,无法通过改进模式来避免问题产生。多数据源的数据质量问题比单数据源更加复杂。
3)数据质量控制方法及实现
从对数据仓库自身数据的监控到对数据形成过程的管理,数据仓库中用于数据质量控制的方法有很多。数据质量逐渐与企业业绩和价值挂钩,企业应当采取合适的方法来评估其数据质量的能力和成熟度,因此提出了数据质量成熟度模型的评估理论。
2.2数据预处理
1)数据清洗
数据清洗将脏数据转化为满足数据质量要求的数据。数据清洗所处理的主要问题有:空缺值、错误数据、孤立点和噪声。
通常不符合要求的数据有三类:
(1)数据缺失:
数据缺失一般包括两种情况:数据中拥有大量缺失值的属性以及数据重要属性存在少量的缺失值。对于前者可以采用删除的操作来去除缺失的属性;对于后者而言,需要采用数据补充的方法将数据补充完整后再进行数据挖掘操作。
在数据清洗中,对于不完整的数据特征采用两种填补方案:用相同的常数去替换缺失的属性值;用该属性最有可能值填补缺失值。
(2)数据错误:
当业务系统不够健全时,容易产生数据错误。
(3)数据重复:
当出现数据重复的情况时,用户可以将重复的数据字段导出来确认并且整理。MapReduce可以实现数据去重。利用Map将需要去重的数据作为一个<key,value>值,经过shuffle后输入到reduce中并利用值key的唯一性直接输出值。核心代码略。
2)数据集成/数据变换
数据集成是指从逻辑上或者物理上将来源、格式以及特点性质不同的数据有机的集中起来,为数据挖掘提供比较完整的数据源。
| 问题类型 | 问题描述 |
|---|---|
| 数据表链接不匹配 | 来自多个数据源中的数据表需要通过相同的主键连接。 |
| 冗余 | 在连接数据表的过程中,没有对表中的字段严格选择后就连接,造成大量的冗余 |
| 数据值冲突 | 不同数据源中的不同属性值导致数据表连接字段的类型出现重复 |
数据集成代码略
数据变换是数据清洗过程中重要一步,是对数据的标准化处理。通常数据变换需要处理的内容如下表所示:
| 数据分类 | 描述 |
|---|---|
| 属性的数据类型 | 当属性之间的取值范围相差大时,要进行数据的映射处理。当属性的取值类型较小时,分析数据的分布频率,然后进行数据转换,将其中字符型数据转化为枚举型 |
| 数据离散化 | 将连续取值的属性离散化成若干区间,来帮助消减一个连续属性的个数 |
| 数据标准化 | 不同来源得到的相同字段定义可能不一样 |
3)数据规约
可以获得数据集的简化表示。
(1)属性选择
根据用户的指标选择一个优化属性子集的过程。优化属性子集可以是属性数目最小的子集,也可以是含有最佳预测准确率的子集。包括属性评估方法和搜索方法。
(2)实例选择
实例选择是使用部分数据记录代替原来所有的数据记录进行数据挖掘,减小挖掘时间和降低挖掘资源的代价,获得更高效的挖掘性能。主要通过采样数据集实现,包括简单随机采样、等级采样等。
2.3数据质量测评
1)数据清洗框架和工具
文献提出了数据清洗的框架,该框架将逻辑规范层与物理实现层分离开来,并围绕该框架提出了数据清洗的模型和语言。AJAX模型是逻辑层面的模型,将数据清洗分为映射、匹配、聚集、合并、跟踪五个过程。
常用的数据清洗工具如下:
| 工具名称 | 功能 |
|---|---|
| DATASTAGE | 针对系统的各个环节可能出现的数据二义性、重复、不完整、违法业务规则等问题,允许通过抽取,将有问题的记录删除,再根据实际情况来调整相应的清洗操作 |
| Visual Warehousing | IBM公司推出的一个创建和维护数据仓库的集成工具,可以定义、创建、管理、监控和维护数据仓库 |
| DTS | 提供数据输入/输出和自动调度功能,在数据传输过程中完成数据的验证、清洗和转换等操作 |
银行数据仓库中的数据清洗的流程如下所示:

逻辑规范:

2)数据清洗评估
通常会参照高质量的数据特征来分析数据质量是否合格,一般通过以下几方面评价数据质量。
(1)相关性
数据质量的一个关键目标是信息是否满足客户的要求。
(2)准确性
准确的信息能反映基本现实,并且高质量信息应该是准确的。
(3)及时性
及时性是指没有延误的信息。
等等
3.分布式数据模型及测试
3.1 框架
hadoop是最著名的大数据处理框架之一,它以可靠、高效、可伸缩方式进行大数据的储存、处理和分析。用户在开发分布式大数据处理程序时,无需了解分布式底层细节,就可以利用大规模集群进行告诉计算与存储。
Hadoop具有如下几个方面的特征:扩容能力、成本低、高效率、可靠性。
Hadoop的核心是HDFS与mapreduce,为用户提供了系统底层透明的分布式基础框架。
3.2数据模型
mapreduce能在整个集群上执行map和reduce任务并报告结果。HDFS通过定义来支持大型文件,并且提供了一种支持跨节点复制数据以进行处理的存储模式。
mapreduce采用主/从架构,主要包括:client、jobtracker、tasktracker。mapreduce先对用户提交的数据进行分块,然后交给不同的Map任务处理。
略
3.3单元测试
MapReduce封装了大量的基础功能,方便用户编程,但给MapReduce的单元测试带来很大挑战。
MRUnit是针对MapReduce的单元测试框架,其基本原理是JUnit4与EasyMock,MRUnit结果简单,依赖于JUnit的单元测试,通过实现Mock对象控制outputcollector操作并且拦截该输出,对比期望结果以达到自动断言的目的。
针对不同的测试对象,MRUnit使用以下几种Driver:
- MapDriver 测试单独的Map
- ReduceDriver 测试单独的Reduce
- MapReduce Driver 将Map与Reduce结合起来测试
- PipelineMapReduceDriver 将多个Map-Reduce pair结合起来测试
从Apache下载MRUnit最新版的jar包,并将jar包添加到hadoop的IDE Classpath 路径中。
假设通过MR分析一个电话记录。
其中Mapper代码如下:
public class SMSCDRMapper extends Mapper 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2575
2575

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









