






一、JVM内存模型
在上一章JVM难点学习与理解分享(一)中运行时数据区不同。
个人理解: 运行时数据区是大范围的,运行时的状态,是逻辑层面的,仅仅是规范。 JVM内存模型:运行时数据区逻辑视图的物理落地。
对应关系如下:
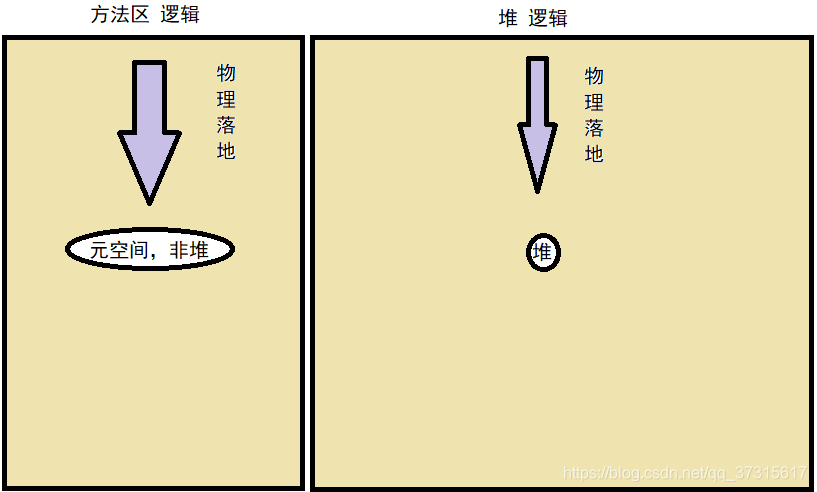
JVM内存模型,又细分为如下图片
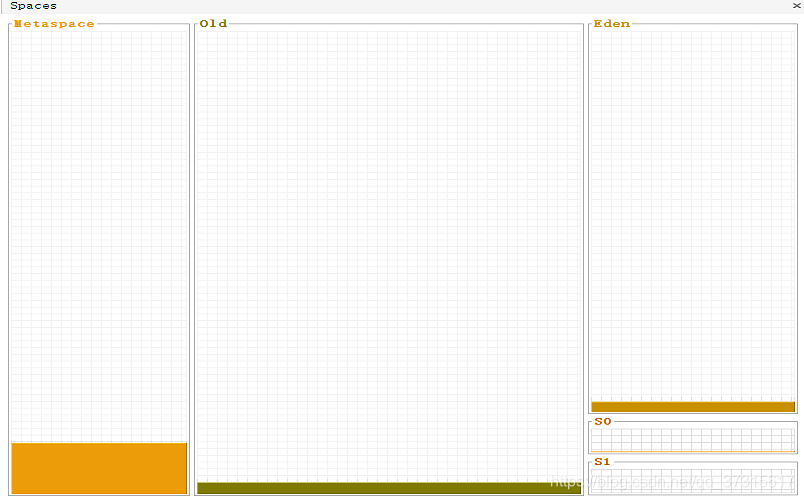
该图片通过官方工具截图。想了解的朋友可以在cmd输入jvisualvm
在下载一个 com-sun-tools-visualvm-modules-visualgc.nbm插件并安装。
所谓的Metaspace即是元空间。 堆区包括了两大块,一个是Old区,一个是Young区
Young区分为两大块,一个是Survivor区(S0+S1),
一块是Eden区 S0和S1一样大,也可以叫From和To
问题一、Minor/Major/Full GC是什么
Minor GC:新生代Major GC:老年代Full GC:新生代+老年代
问题二、为什么需要Survivor区?为什么需要两个Survivor区?
1、减少被送到老年代的对象,因为老年代会触发Full
GC非常消耗内存。经历16次GC还存活的对象,才会进入老年代,所以需要Survivor区。
2、如果没有两个Survivor区,每次GC,都会产生空间碎片,两个Survivor区恰好利用了永远有一个Survivor是空的,另一个非空的Survivor无碎片,利用一块空间换去无空间碎片,很值。
二、垃圾回收
1、如何确定一个对象是垃圾?
1引用计数法:
对于某个对象而言,只要应用程序中持有该对象的引用,就说明该对象不是垃圾,如果一个对象没有任 何指针对其引用,它就是垃圾。 弊端
:如果AB相互持有引用,导致永远不能被回收。
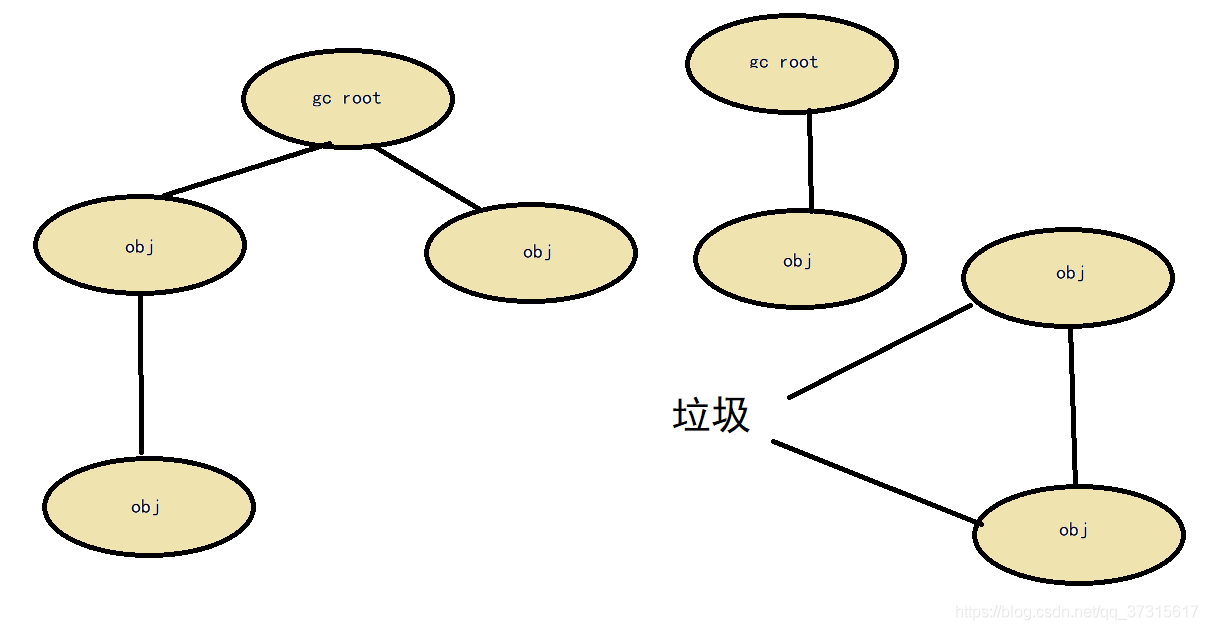
2可达性分析
通过GC Root的对象,开始向下寻找,看某个对象是否可达 可作为GC Root的对象:类加载器、Thread、虚拟机栈的本地变量表等
2、什么时候会垃圾回收
GC是由JVM自动完成的,根据JVM系统环境而定,所以时机是不确定的。
我们可以手动进行垃圾回收,比如调用System.gc()方法通知JVM进行一次垃圾回收,但是System.gc()只是通知要回收,什么时候回收由JVM决定。但是不建议手动调用该方法,因为GC消耗的资源比较大。
(1)当Eden区、S区不够用了Minor GC
(2)老年代空间不够用了Major GC
(3)方法区空间不够用了
(4)System.gc()
3、垃圾回收算法(怎么样回收)
1.标记-清除
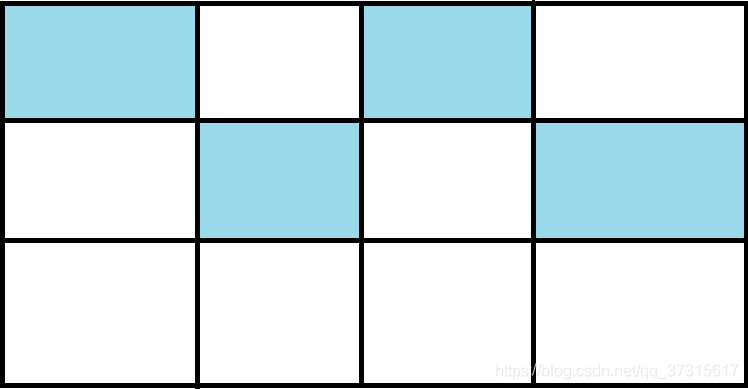
缺点:将内存划分为两块相等的区域,每次只使用其中一块,适用老年代。如下图所示:
标记:
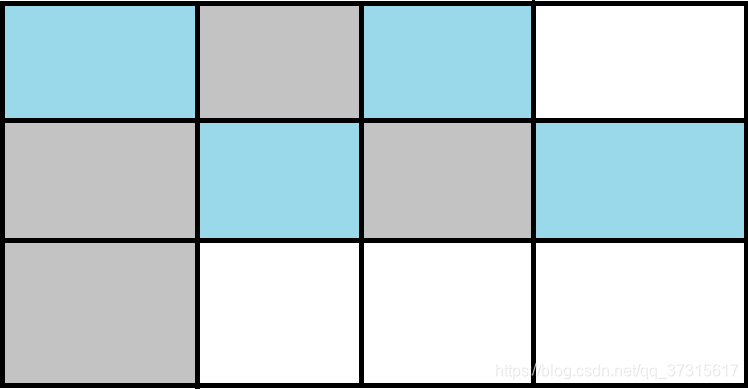
清除:
2.标记-复制
缺点: 空间利用率降低,新生代的两个survior区就是利用这个算法。适用yong gc。
标记

复制

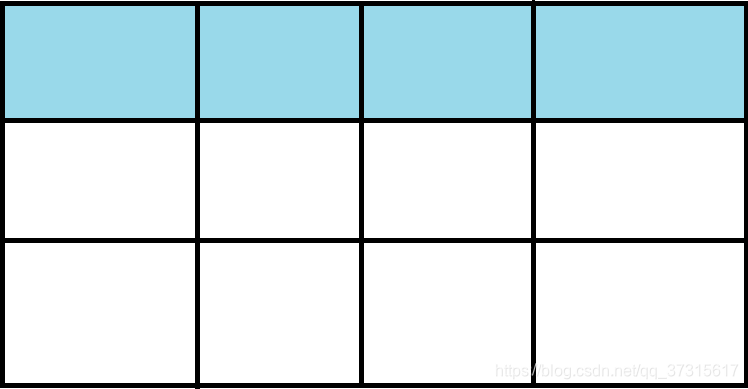
3.标记整理
标记过程仍然与"标记-清除"算法一样,但是后续步骤不是直接对可回收对象进行清理,而是让所有存活的对象都向一端移动,然后直接清理掉端边界以外的内存。实现难度极大,效率变低。
标记

整理
4.垃圾收集器(上述算法落地)
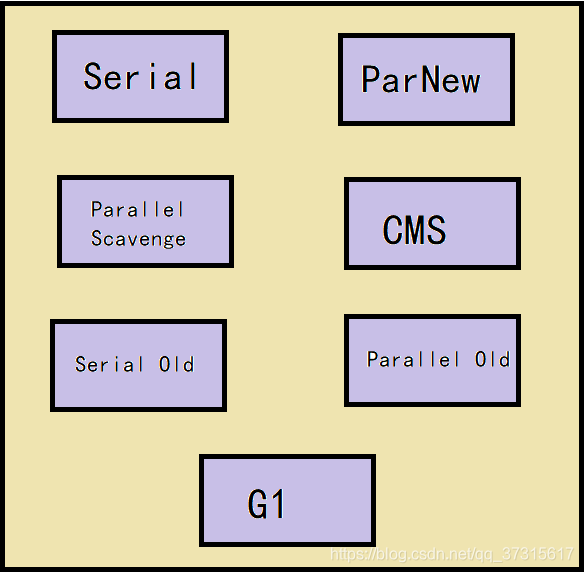
1.Serial(串行)
一种单线程收集器,只会使用一个CPU或者一条收集线程去完成垃圾收集工作,在进行垃圾收集的时候需要暂停其他线程。
优点:简单高效,拥有很高的单线程收集效率
缺点:收集过程需要暂停所有线程
算法:复制算法
例图:

2.Serial Old(串行)
Serial Old收集器是Serial收集器的老年代版本,一个单线程收集器。
采用"标记-整理算法",运行过程和Serial收集器一样。

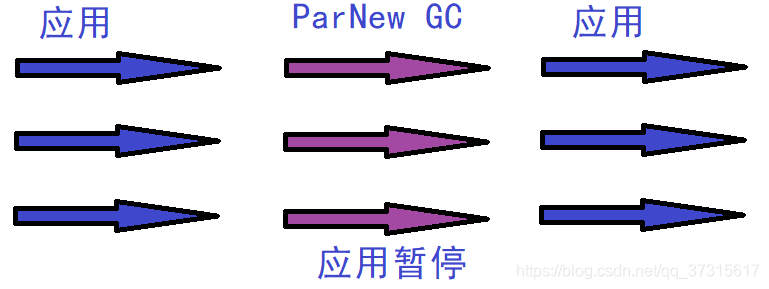
3.ParNew(并行)
个人理解:Serial收集器的多线程版本。
优点:在多CPU时,比Serial效率高。
缺点:收集过程暂停所有应用程序线程,单CPU时比Serial效率差。
算法:复制算法
例图
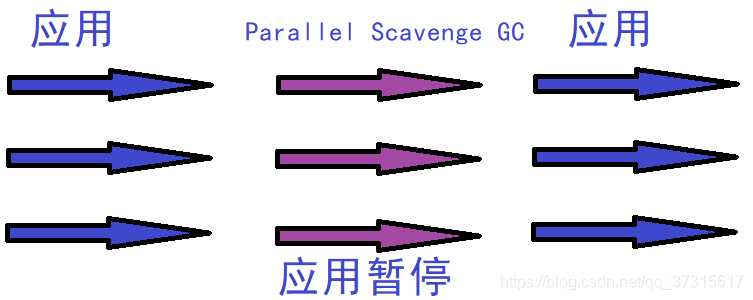
4.Parallel Scavenge(并行)
Parallel
Scavenge收集器是一个新生代收集器,它也是使用复制算法的收集器,又是并行的多线程收集器,看上去和ParNew一样,但是Parallel
Scanvenge更关注系统的吞吐量。 吞吐量=运行用户代码的时间/(运行用户代码的时间+垃圾收集时间)
-XX:MaxGCPauseMillis控制最大的垃圾收集停顿时间-XX:GCRatio直接设置吞吐量的大小。
5.Parallel Old(并行)
Parallel Old收集器是Parallel Scavenge收集器的老年代版本,使用多线程和标记-整理算法进行垃圾回收,也是更加关注系统的吞吐量。
6.CMS(并发)
CMS(Concurrent Mark Sweep)收集器是一种以获取 最短回收停顿时间 为目标的收集器。
采用的是"标记-清除算法",整个过程分为4步 优点:并发收集、低停顿 缺点:产生大量空间碎片、并发阶段会降低吞吐量

7.G1(Garbage-First)(并发)
特點: 筛选回收(Live Data Counting and Evacuation) 对各个Region的回收价值和成本进行排序,根据用户所期望的GC停顿时间制定回收计划
设置Region大小:-XX:G1HeapRegionSize=M
注意:调优时关注 吞吐量和停顿时间。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









