







Note 4 - Policy Iteration Algorithms
4. Policy Iteration Algorithms
在Note 3中,我们开发了解决无限范围MDP问题的VI算法。尽管该算法很简单,而且具有良好的理论收敛特性,但很明显,当状态空间很大时,该算法的效率会很低。VI算法实际上也变得不可行,因为它需要无限次地迭代以达到策略空间中的必要和充分的最优条件。此外,由于每个可接受的策略都有一个唯一的总成本函数,而唯一策略的总数是有限的,很明显,由VI算法产生的大多数总成本函数估计值并不对应于任何合法策略。换句话说,VI算法对于解决具有有限状态和行动空间的MDP问题来说,确实是非常低效的。因此,在本次会议上,我们研究了另一种解决该问题的方法,即在策略空间中搜索。
补充:范数的性质
在相关证明时,我们会利用到范数的性质,在这里作为补充。若 X X X 是数域上的线性空间,泛函 ∥ ⋅ ∥ : X → R \|\cdot\|: X \rightarrow \mathbb{R} ∥⋅∥:X→R 满足:
- 正定性: ∥ x ∥ ≥ 0 \|x\| \geq 0 ∥x∥≥0 ,且 ∥ x ∥ = 0 ⇔ x = 0 \|x\|=0 \Leftrightarrow x=0 ∥x∥=0⇔x=0 ;
- 正齐次性: ∥ c x ∥ = ∣ c ∣ ∥ x ∥ \|c x\|=|c|\|x\| ∥cx∥=∣c∣∥x∥;
- 次可加性 (三角不等式) : ∥ x + y ∥ ≤ ∥ x ∥ + ∥ y ∥ \|x+y\| \leq\|x\|+\|y\| ∥x+y∥≤∥x∥+∥y∥ 。
那么, ∥ ⋅ ∥ \|\cdot\| ∥⋅∥ 称为 X 上的一个范数。
4.1 贪婪诱导策略的特性 (Properties of Greedily Induced Policy)
首先,让我们研究一下贪婪诱导策略的一些特性。
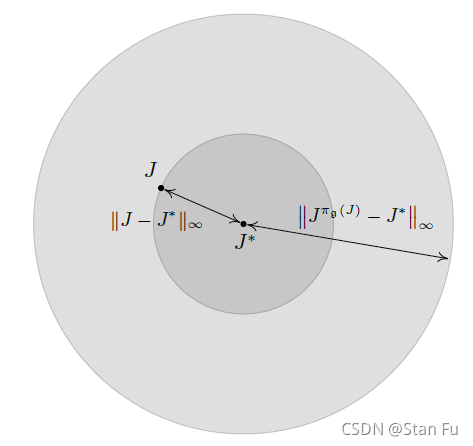
图1:贪婪诱导策略的直接误差界限。注意,圆形只是向量空间上度量的视觉效果,与无穷范数无关。
Proposition 4.1 贪婪诱导策略的直接误差边界 (Direct error bound of greedily induced policy)
给定一个无限范围MDP
{
X
,
U
,
p
,
g
,
γ
}
\{\mathcal{X}, \mathcal{U}, p, g, \gamma\}
{X,U,p,g,γ},让
J
∗
J^{*}
J∗是最佳总成本函数,
J
J
J是
J
∗
J^{*}
J∗的近似值,
π
\pi
π是定义3.5中关于
J
J
J的贪婪诱导策略。
∥
J
π
−
J
∗
∥
∞
≤
2
γ
1
−
γ
∥
J
−
J
∗
∥
∞
(4.1)
\left\|J^{\pi}-J^{*}\right\|_{\infty} \leq \frac{2 \gamma}{1-\gamma}\left\|J-J^{*}\right\|_{\infty} \tag{4.1}
∥Jπ−J∗∥∞≤1−γ2γ∥J−J∗∥∞(4.1)
Proof.
由于策略
π
\pi
π是关于
J
J
J的贪婪诱导策略,很明显,
T
π
J
=
T
g
J
\mathrm{T}_{\pi} J=\mathrm{T}_{\mathfrak{g}}J
TπJ=TgJ 那么,我们可以简单地
∥
J
π
−
J
∗
∥
∞
=
∥
J
π
−
T
π
J
+
T
π
J
−
J
∗
∥
∞
≤
∥
J
π
−
T
π
J
∥
∞
+
∥
T
π
J
−
J
∗
∥
∞
≤
γ
∥
J
π
−
J
∥
∞
+
∥
T
g
J
−
T
g
J
∗
∥
∞
≤
γ
∥
J
π
−
J
∥
∞
+
γ
∥
J
−
J
∗
∥
∞
(4.2)
\begin{aligned} \left\|J^{\pi}-J^{*}\right\|_{\infty} &=\left\|J^{\pi}-\mathrm{T}_{\pi} J+\mathrm{T}_{\pi} J-J^{*}\right\|_{\infty} \\ & \leq\left\|J^{\pi}-\mathrm{T}_{\pi} J\right\|_{\infty}+\left\|\mathrm{T}_{\pi} J-J^{*}\right\|_{\infty} \\ & \leq \gamma\left\|J^{\pi}-J\right\|_{\infty}+\left\|\mathrm{T}_{\mathfrak{g}} J-\mathrm{T}_{\mathfrak{g}} J^{*}\right\|_{\infty} \\ & \leq \gamma\left\|J^{\pi}-J\right\|_{\infty}+\gamma\left\|J-J^{*}\right\|_{\infty} \end{aligned}\tag{4.2}
∥Jπ−J∗∥∞=∥Jπ−TπJ+TπJ−J∗∥∞≤∥Jπ−TπJ∥∞+∥TπJ−J∗∥∞≤γ∥Jπ−J∥∞+∥TgJ−TgJ∗∥∞≤γ∥Jπ−J∥∞+γ∥J−J∗∥∞(4.2)
其中,第一个不等式是根据无穷范数的三角不等式,而第二和第三个不等式是由于贝尔曼算子
T
π
\mathrm{T}_{\pi}
Tπ和
T
g
T_{\mathfrak{g}}
Tg的收缩性质。 同样,根据无穷范数的三角不等式,我们可以用以下结果代替公式
(
4.2
)
(4.2)
(4.2),
∥
J
π
−
J
∥
∞
≤
∥
J
π
−
J
∗
∥
∞
+
∥
J
−
J
∗
∥
∞
(4.3)
\left\|J^{\pi}-J\right\|_{\infty} \leq\left\|J^{\pi}-J^{*}\right\|_{\infty}+\left\|J-J^{*}\right\|_{\infty} \tag{4.3}
∥Jπ−J∥∞≤∥Jπ−J∗∥∞+∥J−J∗∥∞(4.3)
并得出
∥
J
π
−
J
∗
∥
∞
≤
γ
∥
J
π
−
J
∗
∥
∞
+
2
γ
∥
J
−
J
∗
∥
∞
(4.4)
\left\|J^{\pi}-J^{*}\right\|_{\infty} \leq \gamma\left\|J^{\pi}-J^{*}\right\|_{\infty}+2 \gamma\left\|J-J^{*}\right\|_{\infty} \tag{4.4}
∥Jπ−J∗∥∞≤γ∥Jπ−J∗∥∞+2γ∥J−J∗∥∞(4.4)
即得结果。
Remark 4.1
在这里,很容易将该界限解释为直接的上界,即假定来自估计值
J
J
J和地面真值
J
∗
J^{*}
J∗的初始误差,见图5中的可视化。将
γ
\gamma
γ 代入公式(4.1),如果
γ
≤
1
/
3
\gamma\leq 1 / 3
γ≤1/3,那么GIP的总成本函数的误差界限就保证小于或等于初始误差。如果
γ
>
1
/
3
\gamma>1 / 3
γ>1/3,那么误差甚至可以被放大。换句话说,误差边界的问题取决于折扣系数的总成本。
地面真值 J ∗ J^{*} J∗是一个正确的基准值,一般用来进行误差估算和效果评价。
此外,由于一般情况下,地面真值
J
∗
J^{*}
J∗并不是给定的,也就是说,初始误差
∥
J
−
J
∗
∥
∞
\|J-J^{*}\|_{\infty}
∥J−J∗∥∞是不可用的,我们当然需要一些替代品。正如Lemma 3.4所建议的,初始误差也可以通过利用最优贝尔曼算子的一步应用的误差来估计。也就是,我们有以下的约束
∥
J
π
−
J
∗
∥
∞
≤
2
γ
(
1
−
γ
)
2
∥
J
−
T
g
J
∥
∞
(4.5)
\left\|J^{\pi}-J^{*}\right\|_{\infty} \leq \frac{2 \gamma}{(1-\gamma)^{2}}\left\|J-\mathrm{T}_{\mathfrak{g}} J\right\|_{\infty} \tag{4.5}
∥Jπ−J∗∥∞≤(1−γ)22γ∥J−TgJ∥∞(4.5)
很简单,我们可以把它解释为一个间接上限。那么很明显,可以理解的是,这个间接上界是更宽松的约束。特别是,如果参数 γ \gamma γ接近于1,间接界限就会变得非常宽松。在下文中,我们提出另一种方法来估计不同的间接约束。
Proposition 4.2 贪婪诱导策略的间接误差边界
给定一个无限范围
M
D
P
{
X
,
U
,
p
,
g
,
γ
}
M D P\{\mathcal{X}, \mathcal{U}, p, g, \gamma\}
MDP{X,U,p,g,γ},让
J
∗
∈
R
K
J^{*} \in \mathbb{R}^K
J∗∈RK是最优的总成本函数,
J
J
J是
J
∗
J^{*}
J∗的近似值,
π
\pi
π是定义3.5中关于
J
J
J的贪婪诱导策略。那么,贪婪诱导策略
J
∗
J^{*}
J∗的总成本函数
J
π
J^{\pi}
Jπ的上界为
∥
J
π
−
J
∗
∥
∞
≤
2
1
−
γ
∥
T
g
J
−
J
∥
∞
(4.6)
\left\|J^{\pi}-J^{*}\right\|_{\infty} \leq \frac{2}{1-\gamma}\left\|\mathrm{T}_{\mathfrak{g}} J-J\right\|_{\infty} \tag{4.6}
∥Jπ−J∗∥∞≤1−γ2∥TgJ−J∥∞(4.6)
Proof.
首先,我们运用与Proposition
4.1
4.1
4.1相同的技巧,得到
∥
J
π
−
J
∗
∥
∞
=
∥
J
π
−
J
+
J
−
J
∗
∥
∞
≤
∥
J
π
−
J
∥
∞
+
∥
J
−
J
∗
∥
∞
≤
∥
J
π
−
J
∥
∞
+
1
1
−
γ
∥
J
−
T
g
J
∥
∞
(4.7)
\begin{aligned} \left\|J^{\pi}-J^{*}\right\|_{\infty} &=\left\|J^{\pi}-J+J-J^{*}\right\|_{\infty} \\ & \leq\left\|J^{\pi}-J\right\|_{\infty}+\left\|J-J^{*}\right\|_{\infty} \\ & \leq\left\|J^{\pi}-J\right\|_{\infty}+\frac{1}{1-\gamma}\left\|J-\mathrm{T}_{\mathrm{g}} J\right\|_{\infty} \end{aligned} \tag{4.7}
∥Jπ−J∗∥∞=∥Jπ−J+J−J∗∥∞≤∥Jπ−J∥∞+∥J−J∗∥∞≤∥Jπ−J∥∞+1−γ1∥J−TgJ∥∞(4.7)
其中第二个不等式是由Lemma 3.4得出的。然后我们回顾 π \pi π的构造为 T π J = T g J \mathrm{T}_{\pi} J=\mathrm{T}_{\mathfrak{g}} J TπJ=TgJ,并进一步对公式(4.7)最后一个不等式的右边第一项进行同样的运算,即
∥ J π − J ∥ ∞ = ∥ J π − T g J + T g J − J ∥ ∞ ≤ ∥ J π − T g J ∥ ∞ + ∥ T g J − J ∥ ∞ ≤ γ ∥ J π − J ∥ ∞ + ∥ T g J − J ∥ ∞ (4.8) \begin{aligned} \left\|J^{\pi}-J\right\|_{\infty} &=\left\|J^{\pi}-\mathrm{T}_{\mathfrak{g}} J+\mathrm{T}_{\mathfrak{g}} J-J\right\|_{\infty} \\ & \leq\left\|J^{\pi}-\mathrm{T}_{\mathfrak{g}} J\right\|_{\infty}+\left\|\mathrm{T}_{\mathfrak{g}} J-J\right\|_{\infty} \\ & \leq \gamma\left\|J^{\pi}-J\right\|_{\infty}+\left\|\mathrm{T}_{\mathfrak{g}} J-J\right\|_{\infty} \end{aligned} \tag{4.8} ∥Jπ−J∥∞=∥Jπ−TgJ+TgJ−J∥∞≤∥Jπ−TgJ∥∞+∥TgJ−J∥∞≤γ∥Jπ−J∥∞+∥TgJ−J∥∞(4.8)
i.e.,
∥ J π − J ∥ ∞ ≤ 1 1 − γ ∥ T g J − J ∥ ∞ (4.9) \left\|J^{\pi}-J\right\|_{\infty} \leq \frac{1}{1-\gamma}\left\|\mathrm{T}_{\mathfrak{g}} J-J\right\|_{\infty} \tag{4.9} ∥Jπ−J∥∞≤1−γ1∥TgJ−J∥∞(4.9)
将上述内容代入公式(4.7)中的不等式就可以得到结果。
显然,这两个间接误差界限是不同的,其比率取决于折扣系数 γ \gamma γ。具体来说,如果 γ < 0.5 \gamma<0.5 γ<0.5,公式(4.5)中的间接界限比公式(4.6)中的更收紧,反之,如果 γ > 0.5 \gamma>0.5 γ>0.5,我们就得出贪婪诱导策略间接界限的结果。
Theorem 4.1 GIPs的间接约束 (Indirect bound of GIPs)
给定一个无限范围 M D P { X , U , p , q , γ } M D P\{\mathcal{X}, \mathcal{U}, p, q, \gamma\} MDP{X,U,p,q,γ},让 J ∗ ∈ R K J^{*} \in \mathbb{R}^{K} J∗∈RK为最优总成本函数, J J J为 J ∗ J^{*} J∗的近似值, π \pi π为公式(3.5)中定义的相对于 J J J贪婪诱导策略。那么,贪婪诱导策略 J ∗ J^{*} J∗的总成本函数 J π J^{\pi} Jπ的上界为
∥ J π − J ∗ ∥ ∞ ≤ min { 2 γ ( 1 − γ ) 2 , 2 1 − γ } ∥ T g J − J ∥ ∞ (4.10) \left\|J^{\pi}-J^{*}\right\|_{\infty} \leq \min \left\{\frac{2 \gamma}{(1-\gamma)^{2}}, \frac{2}{1-\gamma}\right\}\left\|\mathrm{T}_{\mathfrak{g}} J-J\right\|_{\infty} \tag{4.10} ∥Jπ−J∗∥∞≤min{(1−γ)22γ,1−γ2}∥TgJ−J∥∞(4.10)
Remark 4.2
根据最优贝尔曼算子的固定点性质,当且仅当近似总成本函数
J
J
J确实是真正的最优总成本函数
J
∗
J^{*}
J∗时,公式(4.10)中不等式右边的项为零。因此,诱导贪婪策略似乎对错误非常敏感。另一方面,我们知道,通过问题的构造,只有有限的几个策略。Theorem 4.1中提出的GIP的误差界限可能过于保守。
4.2 策略空间中VI的收敛性 (Convergence of VI in policy space)
如Proposition 3.5贝尔曼算子的收缩性所示, V I VI VI算法收敛于最优总成本函数。那么很明显,关于总成本函数估计的无限序列的GIPs也收敛于最优策略。根据只有有限数量的策略的假设,可以合理地预期,在有限数量的 V I VI VI迭代之后,当总成本函数的估计值足够接近于真正的最优总成本函数时,相关的GIPs会稳定在一个最优策略。
Proposition 4.3
给定一个无限范围 M D P MDP MDP { X . U , p , q , γ } \{\mathcal{X} . \mathcal{U}, p, q, \gamma\} {X.U,p,q,γ},在最优总成本函数 J ∗ J^{*} J∗周围存在一个开放的邻域,用 N ( J ∗ ) \mathcal{N}\left(J^{*}\right) N(J∗)表示,这样,关于在 J ∈ N ( J ∗ ) J \in \mathcal{N}\left(J^{*}\right) J∈N(J∗)中的任何 J J J的 G I P GIP GIP是最优的。
Proof
让我们用
P
d
m
∗
\mathfrak{P}_{d m}^{*}
Pdm∗来表示最优策略的集合。根据策略数量是有限的这一结构,以及贝尔曼算子的唯一固定点,很明显,最优总成本和任何非最优总成本之间有差距,也就是说,。
ρ : = min π ∉ P d m ∗ ∥ J π − J ∗ ∥ ∞ > 0 (4.11) \rho:=\min _{\pi \notin \mathfrak{P}_{d m}^{*}}\left\|J^{\pi}-J^{*}\right\|_{\infty}>0 \tag{4.11} ρ:=π∈/Pdm∗min∥Jπ−J∗∥∞>0(4.11)
构造上,Proposition 4.1意味着,对于任何任意的 J J J,满足
∥ J − J ∗ ∥ ∞ < ρ ( 1 − γ ) 2 γ (4.12) \left\|J-J^{*}\right\|_{\infty}<\frac{\rho(1-\gamma)}{2 \gamma} \tag{4.12} ∥J−J∗∥∞<2γρ(1−γ)(4.12)
相应的GIP
π
g
(
J
)
\pi_{\mathfrak{g}}(J)
πg(J)关于
J
J
J的总成本函数是在上界严格约束的,即
∥
J
π
g
(
J
)
−
J
∗
∥
∞
≤
2
γ
1
−
γ
∥
J
−
J
∗
∥
∞
<
ρ
(4.13)
\left\|J_{\pi_{\mathfrak{g}}(J)}-J^{*}\right\|_{\infty} \leq \frac{2 \gamma}{1-\gamma}\left\|J-J^{*}\right\|_{\infty}<\rho \tag{4.13}
∥∥Jπg(J)−J∗∥∥∞≤1−γ2γ∥J−J∗∥∞<ρ(4.13)
因此,一个GIP π g ( J ) \pi_{\mathfrak{g}}(J) πg(J) 必须是最优的。
Proposition 4.4
给定一个无限范围 M D P { X , U , p , g , γ } M D P\{\mathcal{X}, \mathcal{U}, p, g, \gamma\} MDP{X,U,p,g,γ},让 J 0 ∈ R K J_{0} \in \mathbb{R}^{K} J0∈RK是一个任意的总成本函数估计值, { J k } k = 1 , 2 … . \left\{J_{k}\right\}_{k=1,2 \ldots .} {Jk}k=1,2….是VI算法(Algorithm 1)产生的序列,那么存在一个数 κ ∈ N \kappa \in \mathbb{N} κ∈N,这样对于所有 k ≥ κ k \geq \kappa k≥κ,相关的 G I P π k : = π g ( J k ) G I P \pi_{k}:=\pi_{\mathfrak{g}}\left(J_{k}\right) GIPπk:=πg(Jk)是最优。
Proof
让一个任意的
J
0
J_{0}
J0初始化VI算法(算法1),并通过以下方式定义原始误差
c 0 : = ∥ J 0 − J ∗ ∥ ∞ (4.14) c_{0}:=\left\|J_{0}-J^{*}\right\|_{\infty} \tag{4.14} c0:=∥J0−J∗∥∞(4.14)
最佳贝尔曼算子的收缩特性导致第k个总成本函数估计与最佳总成本函数的误差界限
T
a
k
J
0
\mathrm{T}_{\mathrm{a}}^{k} J_{0}
TakJ0如下
∥
T
g
k
J
0
−
J
∗
∥
∞
≤
γ
k
c
0
<
ρ
(
1
−
γ
)
2
γ
(4.15)
\left\|\mathrm{T}_{\mathfrak{g}}^{k} J_{0}-J^{*}\right\|_{\infty} \leq \gamma^{k} c_{0}<\frac{\rho(1-\gamma)}{2 \gamma} \tag{4.15}
∥∥TgkJ0−J∗∥∥∞≤γkc0<2γρ(1−γ)(4.15)
其中第二个不等式来自Proposition 4.3. 如果
k > [ log γ ρ ( 1 − γ ) 2 γ c 0 ] (4.16) k>\left[\log _{\gamma} \frac{\rho(1-\gamma)}{2 \gamma c_{0}}\right] \tag{4.16} k>[logγ2γc0ρ(1−γ)](4.16)
直接得出所有 GIP 的 π k \pi_{k} πk是最佳的。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-uvNbeVwb-1637533833819)(https://cdn.mathpix.com/cropped/f9b1b42b5e28ba9217a29ca53071d4b2-4.jpg?height=396&width=903&top_left_y=171&top_left_x=171)]](https://i-blog.csdnimg.cn/blog_migrate/d83db0a32804deadb178434cf297da31.png)
4.3 策略迭代算法 (The Policy Iteration Algorithm)
上一节的结果清楚地表明了 V I VI VI在策略空间中的收敛性。然而,它的性能仍然在很大程度上取决于 V I VI VI的性质。通过观察符合条件的策略空间是有限的这一事实,我们在下面的命题中研究了基于策略的真实总成本的最优贝尔曼算子的进一步性质。
Proposition 4 . 5 策略改进的性质 (Properties of Policy Improvement).
给定一个无限范围 M D P { X , U , p , g , γ } M D P\{\mathcal{X}, \mathcal{U}, p, g, \gamma\} MDP{X,U,p,g,γ},让 J π ∈ R K J^{\pi} \in \mathbb{R}^{K} Jπ∈RK为任意固定策略 π \pi π的总成本函数, π ′ : = π g ( J π ) \pi^{\prime}:=\pi_{\mathfrak{g}}\left(J^{\pi}\right) π′:=πg(Jπ)为公式(3.34)中定义的GIP。
即, T π ′ J π = T g J π . \mathrm{T}_{\pi^{\prime}} J^{\pi}=\mathrm{T}_{\mathfrak{g}} J^{\pi} . Tπ′Jπ=TgJπ. 然后,我们有
J
π
′
≤
J
π
(4.17)
J^{\pi^{\prime}} \leq J^{\pi} \tag{4.17}
Jπ′≤Jπ(4.17)
并且,当且仅当
J
π
J^{\pi}
Jπ是最优总成本函数时,该等式成立。
Proof
根据贝尔曼算子 T π \mathrm{T}_{\pi} Tπ的固定点特性,即 T π J π = J π \mathrm{T}_{\pi} J^{\pi}=J^{\pi} TπJπ=Jπ,以及最优Bellam算子的特性,即 T g J π ≤ T π J π \mathrm{T}_{\mathfrak{g}} J^{\pi} \leq \mathrm{T}_{\pi} J^{\pi} TgJπ≤TπJπ,我们有
T g J π ≤ T π J π = J π (4.18) \mathrm{T}_{\mathfrak{g}} J^{\pi} \leq \mathrm{T}_{\pi} J^{\pi}=J^{\pi} \tag{4.18} TgJπ≤TπJπ=Jπ(4.18)
GIP π ′ \pi^{\prime} π′ 的构建结果是
T π ′ J π ≤ T g J π ≤ J π (4.19) \mathrm{T}_{\pi^{\prime}} J^{\pi} \leq \mathrm{T}_{\mathfrak{g}} J^{\pi} \leq J^{\pi} \tag{4.19} Tπ′Jπ≤TgJπ≤Jπ(4.19)
那么公式(4.17)中的结果直接来自于Corollary 3.2。
如果 J π J^{\pi} Jπ等于最优总成本函数 J ∗ J^{*} J∗,那么很容易就能看出平等性成立。如果 J π ′ = J π J^{\pi^{\prime}}=J^{\pi} Jπ′=Jπ,那么公式(4.19)中的结果会导致
J π ′ = T g J π = J π (4.20) J^{\pi^{\prime}}=\mathrm{T}_{\mathfrak{g}} J^{\pi}=J^{\pi} \tag{4.20} Jπ′=TgJπ=Jπ(4.20)
显然,根据 T g \mathrm{T}_{\mathfrak{g}} Tg的唯一固定点特性, J π = J ∗ J^{\pi}=J^{*} Jπ=J∗。
计算策略
π
\pi
π的真实总成本函数
J
π
J^{\pi}
Jπ的过程被称为策略评估 Policy
Evaluation (PE) ,或
R
L
RL
RL的预测任务。相关的贝尔曼算子
T
π
T_{\pi}
Tπ的固定点性质给出了一个简单的算法。最后,我们对
P
I
PI
PI算法的收敛性做出如下结论。
Theorem 4 . 2 PI的收敛性 (Convergence of PI )
给定一个无限范围 M D P { X , U , p , g , γ } M D P\{\mathcal{X}, \mathcal{U}, p, g, \gamma\} MDP{X,U,p,g,γ}, P I P I PI算法在有限多次扫描中收敛到最优总成本函数。
Proof
根据命题4.5,我们很容易看到 J π k + 1 ≤ J π k J_{\pi_{k+1}} \leq J_{\pi_{k}} Jπk+1≤Jπk 由于假设状态空间和行动空间都是有限的,所以静止策略的数量也是有限的。根据策略改进的严格改进特性,很明显PI算法在有限多次扫描中收敛。
现在很明显,PI算法的瓶颈是PE,即迭代策略评估需要无限次地迭代贝尔曼算子。在下文中,我们在MDP模型中引入了一个方便的解决方案。让我们回顾贝尔曼方程为
J π ( x ) = E p π ( x ′ ∣ x ) [ g ( x , π ( x ) , x ′ ) + γ J π ( x ′ ) ] (4.21) J^{\pi}(x)=\mathbb{E}_{p_{\pi}\left(x^{\prime} \mid x\right)}\left[g\left(x, \pi(x), x^{\prime}\right)+\gamma J^{\pi}\left(x^{\prime}\right)\right] \tag{4.21} Jπ(x)=Epπ(x′∣x)[g(x,π(x),x′)+γJπ(x′)](4.21)
定义4.1预期成本函数 (Expected cost function)
给定一个无限范围MDP问题 { X , U , p , g , γ } \{\mathcal{X}, \mathcal{U}, p, g, \gamma\} {X,U,p,g,γ},在状态 x ∈ X x \in \mathcal{X} x∈X的预期成本函数被定义为
G π ( x ) : = E p π ( x ′ ∣ x ) [ g ( x , π ( x ) , x ′ ) ] (4.22) G_{\pi}(x):=\mathbb{E}_{p_{\pi}\left(x^{\prime} \mid x\right)}\left[g\left(x, \pi(x), x^{\prime}\right)\right] \tag{4.22} Gπ(x):=Epπ(x′∣x)[g(x,π(x),x′)](4.22)
我们进一步定义状态转换矩阵 P π P_{\pi} Pπ为从每个状态 x x x到其所有潜在后续状态 x ′ x^{\prime} x′的转换概率。
P π : = [ p 11 ⋯ p 1 K ⋱ p K 1 ⋯ p K K ] (4.23) P_{\pi}:=\left[\begin{array}{ccc} p_{11} & \cdots & p_{1 K} \\ & \ddots & \\ p_{K 1} & \cdots & p_{K K} \end{array}\right] \tag{4.23} Pπ:=⎣⎡p11pK1⋯⋱⋯p1KpKK⎦⎤(4.23)
其中 P π P_{\pi} Pπ的每一行之和为1。矩阵 P π P_{\pi} Pπ被称为Markov矩阵。下面的结果描述了Markov矩阵的特征值的有界性,这对进一步的发展很有帮助。
Lemma 4.1
给定一个马尔科夫矩阵 P ∈ R m × m P \in \mathbb{R}^{m \times m} P∈Rm×m, 对于 i = 1 , … , m i=1, \ldots, m i=1,…,m 其特征值 λ i \lambda_{i} λi 满足 ∣ λ i ∣ ≤ 1 \left|\lambda_{i}\right| \leq 1 ∣λi∣≤1
proof
让 λ ∈ C \lambda \in \mathbb{C} λ∈C是 P P P的一个特征值, x ∈ C m x\in\mathbb{C}^{m} x∈Cm是一个相应的特征向量,即, M x = λ x . M x=\lambda x . Mx=λx. 让 k k k为 x x x中模数最大的条目的索引,即 ∣ x k ∣ ≥ ∣ x i ∣ \left|x_{k}\right| \geq\left|x_{i}\right| ∣xk∣≥∣xi∣ for all i = 1 , … , m i=1, \ldots, m i=1,…,m。那么我们有
∣ λ x k ∣ = ∣ λ ∣ ⋅ ∣ x k ∣ = ∣ ∑ j = 1 p k j x j ∣ ≤ ∑ j = 1 p k j ∣ x j ∣ ≤ ∑ j = 1 p k j ∣ x k ∣ = ∣ x k ∣ (4.24) \begin{aligned} \left|\lambda x_{k}\right| &=|\lambda| \cdot\left|x_{k}\right| \\ &=\left|\sum_{j=1} p_{k j} x_{j}\right| \\ & \leq \sum_{j=1} p_{k j}\left|x_{j}\right| \\ & \leq \sum_{j=1} p_{k j}\left|x_{k}\right| \\ &=\left|x_{k}\right| \end{aligned} \tag{4.24} ∣λxk∣=∣λ∣⋅∣xk∣=∣∣∣∣∣j=1∑pkjxj∣∣∣∣∣≤j=1∑pkj∣xj∣≤j=1∑pkj∣xk∣=∣xk∣(4.24)
因此这种关系 ∣ λ ∣ ⋅ ∣ x k ∣ ≤ ∣ x k ∣ |\lambda| \cdot\left|x_{k}\right| \leq\left|x_{k}\right| ∣λ∣⋅∣xk∣≤∣xk∣ 导致 ∣ λ ∣ ≤ 1 |\lambda| \leq 1 ∣λ∣≤1
那么贝尔曼方程可以表示为
J π = G π + γ P π J π (4.25) J^{\pi}=G_{\pi}+\gamma P_{\pi} J^{\pi} \tag{4.25} Jπ=Gπ+γPπJπ(4.25)
其中 J π ∈ R K J^{\pi} \in \mathbb{R}^{K} Jπ∈RK中,每个状态有一个对应的项,即
[ J π ( x 1 ) ⋮ J π ( x K ) ] = [ G 1 ⋮ G K ] + γ [ p 11 ⋯ p 1 K ⋱ p K 1 ⋯ p K K ] [ J π ( x 1 ) ⋮ J π ( x K ) ] (4.26) \left[\begin{array}{c} J^{\pi}\left(x_{1}\right) \\ \vdots \\ J^{\pi}\left(x_{K}\right) \end{array}\right]=\left[\begin{array}{c} G_{1} \\ \vdots \\ G_{K} \end{array}\right]+\gamma\left[\begin{array}{ccc} p_{11} & \cdots & p_{1 K} \\ & \ddots & \\ p_{K 1} & \cdots & p_{K K} \end{array}\right]\left[\begin{array}{c} J^{\pi}\left(x_{1}\right) \\ \vdots \\ J^{\pi}\left(x_{K}\right) \end{array}\right] \tag{4.26} ⎣⎢⎡Jπ(x1)⋮Jπ(xK)⎦⎥⎤=⎣⎢⎡G1⋮GK⎦⎥⎤+γ⎣⎡p11pK1⋯⋱⋯p1KpKK⎦⎤⎣⎢⎡Jπ(x1)⋮Jπ(xK)⎦⎥⎤(4.26)
通过求解
J
k
∈
R
K
J_{k} \in \mathbb{R}^{K}
Jk∈RK线性方程,可以很容易地找到解
(
I
K
−
γ
P
π
)
J
=
G
π
(4.27)
\left(I_{K}-\gamma P_{\pi}\right) J=G_{\pi} \tag{4.27}
(IK−γPπ)J=Gπ(4.27)
由于
γ
\gamma
γ的总成本严格小于1,Lemma 4.1意味着矩阵
I
K
−
γ
P
π
I_{K}-\gamma P_{\pi}
IK−γPπ是可逆的。因此,线性方程组有一个唯一的解,即
J
=
(
I
K
−
γ
P
π
)
−
1
G
π
(4.28)
J=\left(I_{K}-\gamma P_{\pi}\right)^{-1} G_{\pi} \tag{4.28}
J=(IK−γPπ)−1Gπ(4.28)
很明显,解决方案的近似形式表达只适用于MDP环境。让我们回顾一下公式(3.8)中定义的贝尔曼方程。除了固定点算法外,还有一个由寻根问题给出的替代解决方案。也就是说,我们定义
F
π
:
R
K
→
R
K
,
J
↦
J
−
T
π
J
=
(
I
K
−
γ
P
π
)
J
−
G
π
(4.29)
\begin{aligned} F_{\pi}: \mathbb{R}^{K} \rightarrow \mathbb{R}^{K}, \quad J & \mapsto J-\mathrm{T}_{\pi} J \\ &=\left(I_{K}-\gamma P_{\pi}\right) J-G_{\pi} \end{aligned} \tag{4.29}
Fπ:RK→RK,J↦J−TπJ=(IK−γPπ)J−Gπ(4.29)
显然,这是一个线性系统 F π ( J ) = 0 F_{\pi}(J)=0 Fπ(J)=0的寻根问题,其解在公式 ( 4.28 ) (4.28) (4.28)中简单给出。
同样地,我们定义一个非线性算子
F g : R K → R K , J ↦ J − T g J (4.30) F_{\mathfrak{g}}: \mathbb{R}^{K} \rightarrow \mathbb{R}^{K}, \quad J \mapsto J-\mathrm{T}_{\mathfrak{g}} J \tag{4.30} Fg:RK→RK,J↦J−TgJ(4.30)
很容易看出, F g ( J ) = 0 F_{\mathfrak{g}}(J)=0 Fg(J)=0的解只是最佳总成本函数。解决非线性寻根问题的一个经典方案是牛顿法。不幸的是,最优的贝尔曼算子 T g \mathrm{T}_{\mathfrak{g}} Tg在 J J J中一般是不可微的。因此,采用牛顿方法的概念是不直接可行的。尽管如此,让 J k J_{k} Jk为根的第 k k k个估计值,并假设存在一个唯一的策略 π k \pi_{k} πk,使得 T π k J k = T g J k \mathrm{T}_{\pi_{k}} J_{k}=\mathrm{T}_{\mathfrak{g}} J_{k} TπkJk=TgJk换句话说,我们假设 P π k P_{\pi_{k}} Pπk的存在。那么 F g F_{\mathfrak{g}} Fg的Jacobian可以计算为
J F g ( J k ) = I K − γ P π k (4.31) J_{F_{\mathfrak{g}}}\left(J_{k}\right)=I_{K}-\gamma P_{\pi_{k}} \tag{4.31} JFg(Jk)=IK−γPπk(4.31)
因此,标准牛顿方法可以形成以下迭代更新规则
J
k
+
1
=
J
k
−
(
I
K
−
γ
P
π
k
)
−
1
F
π
k
(
J
k
)
=
J
k
−
(
I
K
−
γ
P
π
k
)
−
1
(
(
I
K
−
γ
P
π
k
)
J
k
−
G
π
k
)
=
(
I
K
−
γ
P
π
k
)
−
1
G
π
k
(4.32)
\begin{aligned} J_{k+1} &=J_{k}-\left(I_{K}-\gamma P_{\pi_{k}}\right)^{-1} F_{\pi_{k}}\left(J_{k}\right) \\ &=J_{k}-\left(I_{K}-\gamma P_{\pi_{k}}\right)^{-1}\left(\left(I_{K}-\gamma P_{\pi_{k}}\right) J_{k}-G_{\pi_{k}}\right) \\ &=\left(I_{K}-\gamma P_{\pi_{k}}\right)^{-1} G_{\pi_{k}} \end{aligned} \tag{4.32}
Jk+1=Jk−(IK−γPπk)−1Fπk(Jk)=Jk−(IK−γPπk)−1((IK−γPπk)Jk−Gπk)=(IK−γPπk)−1Gπk(4.32)
这就是策略迭代算法。有了这样一个有趣的解释,部署潜在的数字方法确实是一个自然的步骤,这将在后面的章节中讨论。
4.4 优化策略迭代算法 (Optimistic Policy Iteration Algorithms)
VI算法的本质是解决一连串的优化问题。那么很明显,当状态空间巨大时,VI算法的计算成本会非常高。一个有趣的观察是,在VI算法的每一步都有一个合法的策略产生。通过这样的事实,评估一个正常的策略,即一个线性算子,通常比评估一个最优的贝尔曼算子要容易得多。多次执行这些GIP算子是很直观的,见Algorithm 3。众所周知,如果第五行的迭代次数 m k m_{k} mk达到无穷大,那么多步策略评估就会收敛到某些不一定是最优策略的总成本函数,见图6 。这样的算法通常被称为优化策略迭代算法,也被称为修正策略迭代算法。在本节的其余部分,我们研究这种算法的收敛性。

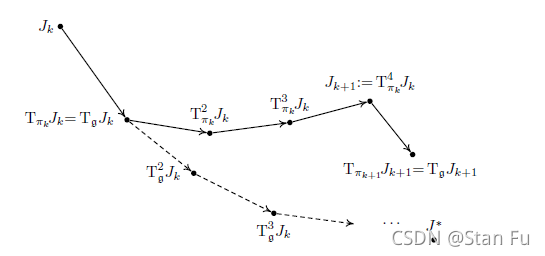
图6:修改后的总成本迭代,又称优化策略迭代。从第
k
k
k个 总成本函数估计值
J
k
J_k
Jk开始,实线路径表示最优策略迭代的评估。而虚线表示总成本迭代的潜在评估。
我们首先研究多步策略迭代的特性。对于任意 m m m步我们定义多步贝尔曼算子,即
T π m : R K → R K , J ↦ ( T π ∘ … ∘ T π ) ⏟ m times J (4.33) \mathrm{T}_{\pi}^{m}: \mathbb{R}^{K} \rightarrow \mathbb{R}^{K}, \quad J \mapsto \underbrace{\left(\mathrm{T}_{\pi} \circ \ldots \circ \mathrm{T}_{\pi}\right)}_{m \text { times }} J \tag{4.33} Tπm:RK→RK,J↦m times (Tπ∘…∘Tπ)J(4.33)
被称为 m m m步贝尔曼算子。从命题3.6,可以直接得出以下结果。
Lemma 4.2
给定一个无限范围MDP X , U , p , g , γ {\mathcal{X}, \mathcal{U}, p, g, \gamma} X,U,p,g,γ,让 J , J ′ ∈ R K J, J^{\prime} \in \mathbb{R}^{K} J,J′∈RK是总成本函数的两个估计值,那么 m m m步贝尔曼算子是一个关于无穷范数的 γ m \gamma^{m} γm-收缩映射,即,
∥ T π m J − T π m J ′ ∥ ∞ ≤ γ m ∥ J − J ′ ∥ ∞ (4.34) \left\|\mathrm{T}_{\pi}^{m} J-\mathrm{T}_{\pi}^{m} J^{\prime}\right\|_{\infty} \leq \gamma^{m}\left\|J-J^{\prime}\right\|_{\infty} \tag{4.34} ∥TπmJ−TπmJ′∥∞≤γm∥J−J′∥∞(4.34)
Proposition 4.6 特殊OPI的融合 (Convergence of Special OPI)
给定一个无限范围M D P { X , U , p , g , γ } \{\mathcal{X}, \mathcal{U}, p, g, \gamma\} {X,U,p,g,γ}。让 J 0 J_{0} J0满足 T g J 0 ≤ J 0 \mathrm{T}_{\mathfrak{g}} J_{0} \leq J_{0} TgJ0≤J0,并且 { J k } \left\{J_{k}\right\} {Jk}和 { π k } \left\{\pi_{k}\right\} {πk}是由最优PI算法生成的序列,那么 J k J_{k} Jk在 k → ∞ k \rightarrow \infty k→∞时收敛到 J ∗ J^{*} J∗。 此外,对于所有指数 k k k大于某个指数 κ , π k \kappa, \pi_{k} κ,πk对于所有 k > κ k>\kappa k>κ是最优的。
Proof.
根据策略改进的定义, 即,
T
π
0
J
0
=
T
g
J
0
\mathrm{T}_{\pi_{0}} J_{0}=\mathrm{T}_{\mathfrak{g}} J_{0}
Tπ0J0=TgJ0, 我们有
T π 0 J 0 = T g J 0 ≤ J 0 (4.35) \mathrm{T}_{\pi_{0}} J_{0}=\mathrm{T}_{\mathfrak{g}} J_{0} \leq J_{0} \tag{4.35} Tπ0J0=TgJ0≤J0(4.35)
让我们假设 T π k J k ≤ J k \mathrm{T}_{\pi_{k}} J_{k} \leq J_{k} TπkJk≤Jk。然后我们有
T π k + 1 J k + 1 = T g J k + 1 (Policy improvement) ≤ T π k J k + 1 (Optimal Bellman operator) = ( T π k ∘ T π k m k ) J k (Optimistic policy evaluation) ≤ T π k m k J k (Assumption + Lemma 3.2) = J k + 1 (Optimistic policy evaluation) (4.36) \begin{aligned} \mathrm{T}_{\pi_{k+1}} J_{k+1} &=\mathrm{T}_{\mathfrak{g}} J_{k+1} & & \text { (Policy improvement) } \\ & \leq \mathrm{T}_{\pi_{k}} J_{k+1} & & \text { (Optimal Bellman operator) } \\ &=\left(\mathrm{T}_{\pi_{k}} \circ \mathrm{T}_{\pi_{k}}^{m_{k}}\right) J_{k} & & \text { (Optimistic policy evaluation) } \\ & \leq \mathrm{T}_{\pi k}^{m_{k}} J_{k} & & \text { (Assumption + Lemma 3.2) } \\ &=J_{k+1} & & \text { (Optimistic policy evaluation) } \end{aligned}\tag{4.36} Tπk+1Jk+1=TgJk+1≤TπkJk+1=(Tπk∘Tπkmk)Jk≤TπkmkJk=Jk+1 (Policy improvement) (Optimal Bellman operator) (Optimistic policy evaluation) (Assumption + Lemma 3.2) (Optimistic policy evaluation) (4.36)
因此,不等式 T π k J k ≤ J k \mathrm{T}_{\pi_{k}} J_{k} \leq J_{k} TπkJk≤Jk对OPI算法生成的所有 J k J_{k} Jk序列都成立。我们进一步推导出
J k = T π k − 1 m k − 1 J k − 1 ≤ T π k − 1 J k − 1 = T g J k − 1 (4.37) \begin{aligned} J_{k} &=\mathrm{T}_{\pi_{k-1}}^{m_{k-1}} J_{k-1} \\ & \leq \mathrm{T}_{\pi_{k-1}} J_{k-1} \\ &=\mathrm{T}_{\mathfrak{g}} J_{k-1} \end{aligned}\tag{4.37} Jk=Tπk−1mk−1Jk−1≤Tπk−1Jk−1=TgJk−1(4.37)
其中不等式由推论3.2得出,第二个等式是策略改进步骤。很明显,我们有
J ∗ ≤ J k ≤ T g k J 0 (4.38) J^{*} \leq J_{k} \leq T_{\mathfrak{g}}^{k} J_{0} \tag{4.38} J∗≤Jk≤TgkJ0(4.38)
让 k → ∞ k\rightarrow\infty k→∞导致的结果是, J k J_{k} Jk在极限时收敛到 J ∗ J^{*} J∗。
最后,由于策略的有限性,可以得出存在一个常数 c > 0 c>0 c>0,这样如果 ∥ J − J ∗ ∥ ≤ c \left\|J-J^{*}\right\| \leq c ∥J−J∗∥≤c和 T π J = T g J \mathrm{T}_{\pi} J=\mathrm{T}_{\mathrm{g}} J TπJ=TgJ,那么 π \pi π就会被收敛。那么 π \pi π就是最优的。因此,显而易见的是
∥ J k − J ∗ ∥ ∞ ≤ ∥ T g k J 0 − J ∗ ∥ ∞ ≤ γ k ∥ J 0 − J ∗ ∥ ∞ ≤ c (4.39) \begin{aligned} \left\|J_{k}-J^{*}\right\|_{\infty} & \leq\left\|\mathrm{T}_{\mathfrak{g}}^{k} J_{0}-J^{*}\right\|_{\infty} \\ & \leq \gamma^{k}\left\|J_{0}-J^{*}\right\|_{\infty} \\ & \leq c \end{aligned} \tag{4.39} ∥Jk−J∗∥∞≤∥∥TgkJ0−J∗∥∥∞≤γk∥J0−J∗∥∞≤c(4.39)
因此,可以直接得出结论: π k \pi_{k} πk对于所有足够大的 k k k来说都是最优的,证明结束。
Remark 4.3
尽管该命题证明了OPI算法在经过一定数量的扫描(sweep)后收敛于最优策略,但收敛性只能从总成本函数的角度来确定。最后一个结果如公式(4.39)所示,OPI在总成本函数的收敛方面与VI算法没有区别。换句话说,与经典的VI算法相比,选择OPI算法似乎没有什么好处。在本节的其余部分,我们研究OPI算法的收敛速度。
Proposition 4 . 7 优化PI的收敛性 (Convergence of Optimistic PI)
给定一个无限范围 M D P { X , U , p , g , γ } M D P\{\mathcal{X}, \mathcal{U}, p, g, \gamma\} MDP{X,U,p,g,γ}让 { J k } \left\{J_{k}\right\} {Jk}和 { π k } \left\{\pi_{k}\right\} {πk}是由最优 P I P I PI算法产生的序列。那么 J k J_{k} Jk就会收敛到 J ∗ J^{*} J∗。此外,对于所有指数 k k k大于某个指数 κ \kappa κ, π k \pi_{k} πk对于所有 k > κ k>\kappa k>κ都是最优的,并且
∥ J k + 1 − J ∗ ∥ ∞ ≤ γ m ∥ J k − J ∗ ∥ ∞ (4.40) \left\|J_{k+1}-J^{*}\right\|_{\infty} \leq \gamma^{m}\left\|J_{k}-J^{*}\right\|_{\infty} \tag{4.40} ∥Jk+1−J∗∥∞≤γm∥Jk−J∗∥∞(4.40)
Proof.
鉴于总成本函数 J 0 J_{0} J0的初始估计,我们定义
c : = ∥ T g J 0 − J 0 ∥ ∞ (4.41) c:=\left\|\mathrm{T}_{\mathfrak{g}} J_{0}-J_{0}\right\|_{\infty} \tag{4.41} c:=∥TgJ0−J0∥∞(4.41)
那么,对于所有 x ∈ X x\in\mathcal{X} x∈X来说,有以下几点是明显的
T g J 0 ( x ) − J 0 ( x ) ≤ c = c ( 1 − γ ) 1 − γ (4.42) \mathrm{T}_{\mathfrak{g}} J_{0}(x)-J_{0}(x) \leq c=\frac{c(1-\gamma)}{1-\gamma} \tag{4.42} TgJ0(x)−J0(x)≤c=1−γc(1−γ)(4.42)
这相当于
T g J 0 ( x ) + γ c 1 − γ ≤ J 0 ( x ) + c 1 − γ (4.43) \mathrm{T}_{\mathfrak{g}} J_{0}(x)+\frac{\gamma c}{1-\gamma} \leq J_{0}(x)+\frac{c}{1-\gamma} \tag{4.43} TgJ0(x)+1−γγc≤J0(x)+1−γc(4.43)
显然,左手边是在右手边应用最优贝尔曼算子 T g T_{\mathfrak{g}} Tg的结果。也就是说,对于任何 J 0 J_{0} J0,我们可以构建
J 0 ′ ( x ) : = J 0 ( x ) + c 1 − γ (4.44) J_{0}^{\prime}(x):=J_{0}(x)+\frac{c}{1-\gamma} \tag{4.44} J0′(x):=J0(x)+1−γc(4.44)
对于所有 x ∈ X x \in \mathcal{X} x∈X,所以 T n J 0 ′ ≤ J 0 ′ \mathrm{T}_{n} J_{0}^{\prime} \leq J_{0}^{\prime} TnJ0′≤J0′ 需要注意的是,对 J 0 J_{0} J0和 J 0 ′ J_{0}^{\prime} J0′应用 O P I OPI OPI算法的结果是对所有 k = 0 , … , ∞ k=0, \ldots, \infty k=0,…,∞的相同策略序列 π k \pi_{k} πk。因此,在不丧失一般性的情况下,我们只需要研究应用于 J 0 ′ J_{0}^{\prime} J0′的 O P I OPI OPI的收敛特性。
根据最优贝尔曼算子 T g \mathrm{T}_{\mathfrak{g}} Tg的单调性,我们有
lim k → ∞ ( J k ′ ( x ) − J k ( x ) ) = lim k → ∞ c γ k 1 − γ = 0 (4.45) \begin{aligned} \lim _{k \rightarrow \infty}\left(J_{k}^{\prime}(x)-J_{k}(x)\right) &=\lim _{k \rightarrow \infty} \frac{c \gamma^{k}}{1-\gamma} \\ &=0 \end{aligned} \tag{4.45} k→∞lim(Jk′(x)−Jk(x))=k→∞lim1−γcγk=0(4.45)
对于所有 x ∈ X x\in \mathcal{X} x∈X。
由于 J k → J ∗ J_{k} \rightarrow J^{*} Jk→J∗,因此,对于所有大于某个指数的 k k k, π k + 1 \pi_{k+1} πk+1是一个最优策略,所以 T π k + 1 = T g \mathrm{T}_{\pi_{k+1}}=\mathrm{T}_{\mathfrak{g}} Tπk+1=Tg。因此,我们有
∥ J k + 1 − J ∗ ∥ ∞ = ∥ T π k m J k − J ∗ ∥ ∞ = ∥ T π k m J k − T π k m J ∗ ∥ ∞ ≤ γ m ∥ J k − J ∗ ∥ ∞ (4.46) \begin{aligned} \left\|J_{k+1}-J^{*}\right\|_{\infty} &=\left\|\mathrm{T}_{\pi_{k}}^{m} J_{k}-J^{*}\right\|_{\infty} \\ &=\left\|\mathrm{T}_{\pi_{k}}^{m} J_{k}-\mathrm{T}_{\pi_{k}}^{m} J^{*}\right\|_{\infty} \\ & \leq \gamma^{m}\left\|J_{k}-J^{*}\right\|_{\infty} \end{aligned} \tag{4.46} ∥Jk+1−J∗∥∞=∥∥TπkmJk−J∗∥∥∞=∥∥TπkmJk−TπkmJ∗∥∥∞≤γm∥Jk−J∗∥∞(4.46)
证明结束。
remark 4.4
如公式(4.46)所示的结果表明,在策略收敛到最优策略后,OPI算法产生的总成本函数收敛得更快。因此,OPI算法通常被认为是更有效的,因为它避免了密集解决一连串优化问题的沉重计算负担。
4.5 Policy Iteration: E-Bus
Consider a group of electric buses running round trips 24 hours a day. The task is to identify optimal operating actions at different battery states. The battery’s endurance and charging speed gradually decrease with the increase of battery life. Hence, for different buses, they have different transition probabilities between battery states. The following figure illustrates the state transitions between different states.
- Three states: H - high battery, L - low battery, E - empty battery
- Two actions: S \mathrm{S} S - continue to serve, C \mathrm{C} C - charge
- Numbers on the edges refer to transition probabilities. α = 0.5 , β = 0.3 , ϵ = 0.7 \alpha=0.5, \beta=0.3, \epsilon=0.7 α=0.5,β=0.3,ϵ=0.7
- Discount factor
γ
=
0.9
\gamma=0.9
γ=0.9 .
We choose the number of unserviced passengers as the local costs: - In the high battery state, if it keeps the service, the unserviced passenger number is 0 .
- In the low battery stats, if it keeps the service, the unserviced passenger number is 2 . (We could imagine some of passengers might give up getting on the bus due to low battery status.)
- In the low battery state, if it charges the battery, the unserviced passenger number is 10 . (Since the charging time is relatively short.)
- In the empty battery state, if it charges the battery, the unserviced passenger number is 20 . (Since the charging time is longer.)
Two eligible deterministic Markov policies are given as follows,
π 1 ( x ) = { C , if x = E S , if x = L S , if x = H \pi_{1}(x)=\left\{\begin{array}{ll} C, & \text { if } x=E \\ S, & \text { if } x=L \\ S, & \text { if } x=H \end{array}\right. π1(x)=⎩⎨⎧C,S,S, if x=E if x=L if x=H
and
π 2 ( x ) = { C , if x = E C , if x = L S , if x = H \pi_{2}(x)=\left\{\begin{array}{ll} C, & \text { if } x=E \\ C, & \text { if } x=L \\ S, & \text { if } x=H \end{array}\right. π2(x)=⎩⎨⎧C,C,S, if x=E if x=L if x=H
(hint: J ∗ = [ 31.034 , 37.930 , 49.792 ] ⊤ J^{*}=[31.034,37.930,49.792]^{\top} J∗=[31.034,37.930,49.792]⊤ )
(1) Error bound of GIP: Given
J
0
=
0
J_{0}=0
J0=0 , verify the correctness Eq. (4.10) in Theorem 4.1 (in the manuscript) numerically.
(2) Convergence of VI in policy space: Estimate the largest number of iterations that the VI needs to iterate, so that all GIPs afterwards are optimal.
(3) Closed-form PI algorithm: Starting from policy
π
1
\pi_{1}
π1 , compute one sweep of the closed-form PI algorithm.
import math
import numpy as np
from numpy.linalg import inv
import matplotlib.pyplot as plt
# some constants:
gamma = 0.9
alpha = 0.5
beta = 0.3
epsilon = 0.7
# local costs:
gec = 20 # g(E,C)=20
ghs = 0 # g(H,S)=0
glc = 10 # g(L,C)=10
gls = 2 # g(L,S)=2
print("\n---------- Policy Iteration (closed form) ----------\n")
# Init total cost:
jh = jl = je = 0 # J(H)=J(L)=J(E)=0
ul = 0 # initial policy: pi_1: H->S, E->C, L->S
print("Init policy: pi_1: H->S, E->C, L->S")
# closed form definition, based on definition 4.1
# expected cost function G for pi_1
G_pi_1 = np.array([
alpha * ghs + (1-alpha) * ghs,
beta * gls + (1-beta) * gls,
epsilon * gec + (1-epsilon) * gec
])
# state transition matrix P for pi_1
P_pi_1 = np.array([
[alpha, 1-alpha, 0],
[0, beta, 1-beta],
[epsilon, 1-epsilon,0 ]
])
# expected cost function G for pi_2
G_pi_2 = np.array([
alpha * ghs + (1-alpha) * ghs,
glc,
epsilon * gec + (1-epsilon) * gec
])
# state transition matrix P for pi_2
P_pi_2 = np.array([
[alpha, 1-alpha, 0],
[1, 0, 0],
[epsilon, 1-epsilon, 0]
])
for k in range(0, 4):
# Policy evaluation: compute J^{pi_k}
if ul == 0:
J_pi = np.dot(inv(np.identity(3) - gamma * P_pi_1), G_pi_1) # based on Eq. 4.28
jh, jl, je = float(J_pi[0]), float(J_pi[1]), float(J_pi[2])
else:
J_pi = np.dot(inv(np.identity(3) - gamma * P_pi_2), G_pi_2) # based on Eq. 4.28
jh, jl, je = float(J_pi[0]), float(J_pi[1]), float(J_pi[2])
# Policy improvement by GIP
ul = np.argmin([
beta * (gls + gamma * jl) + (1 - beta) * (gls + gamma * je), # Service
glc + gamma * jh # Charge
])
if ul == 0:
print("Iter {} \t pi_1: H->S, E->C, L->S".format(k))
elif ul == 1:
print("Iter {} \t pi_2: H->S, E->C, L->C".format(k))
print('After PI, jh = {}, jl = {}, je = {}\n'.format(jh, jl, je))
print("\n---------- Optimistic Policy Iteration ----------\n")
def T_pi(jh, jl, je, ul):
je_ = epsilon * (gec + gamma * jh) + (1-epsilon) * (gec + gamma * jl)
jh_ = alpha * (ghs + gamma * jh) + (1-alpha) * (ghs + gamma * jl)
if ul == 0:
jl_ = beta * (gls + gamma * jl) + (1-beta) * (gls + gamma * je)
elif ul == 1:
jl_ = glc + gamma * jh
return jh_, jl_, je_
# Init total cost:
jh = jl = je = 0 # J(H)=J(L)=J(E)=0
for k in range(0, 4):
# Policy improvement: generate a GIP
ul = np.argmin([
beta * (gls + gamma * jl) + (1-beta) * (gls + gamma * je), # Service
glc + gamma * jh # Charge
])
if ul == 0:
print("Iter {} \t pi_1: H->S, E->C, L->S".format(k))
elif ul == 1:
print("Iter {} \t pi_2: H->S, E->C, L->C".format(k))
# Finite-step Policy Evaluation: compute J_k+1 by evaluating T_pi on J_k
m_k = 0
j_threshold = 1
while j_threshold > 0.001:
jh_, jl_, je_ = T_pi(jh, jl, je, ul)
j_threshold = max(abs(jh_-jh), abs(jl_-jl), abs(je_-je))
jh, jl, je = jh_, jl_, je_
m_k += 1
print('\t after PE:jh = {:.4f}, jl = {:.4f}, je = {:.4f}'.format(jh, jl, je))
print("\t {} steps for policy evaluation\n".format(m_k))
print('After OPI, jh = {}, jl = {}, je = {}\n'.format(jh, jl, je))
the outputs are
---------- Policy Iteration (closed form) ----------
Init policy: pi_1: H->S, E->C, L->S
Iter 0 pi_2: H->S, E->C, L->C
Iter 1 pi_2: H->S, E->C, L->C
Iter 2 pi_2: H->S, E->C, L->C
Iter 3 pi_2: H->S, E->C, L->C
After PI, jh = 31.034482758620683, jl = 37.93103448275862, je = 49.793103448275865
---------- Optimistic Policy Iteration ----------
Iter 0 pi_1: H->S, E->C, L->S
after PE:jh = 50.7878, jl = 62.0759, je = 68.7559
84 steps for policy evaluation
Iter 1 pi_2: H->S, E->C, L->C
after PE:jh = 31.0432, jl = 37.9398, je = 49.8018
74 steps for policy evaluation
Iter 2 pi_2: H->S, E->C, L->C
after PE:jh = 31.0423, jl = 37.9389, je = 49.8010
1 steps for policy evaluation
Iter 3 pi_2: H->S, E->C, L->C
after PE:jh = 31.0415, jl = 37.9381, je = 49.8002
1 steps for policy evaluation
After OPI, jh = 31.041547850465356, jl = 37.938099574603285, je = 49.80016854012053



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











