




1. Intorduction
Abbreviations Declaration
- SDM: sequential decision making 顺序决策
- DP: Dynamic Programming 动态规划
- MDP: Markov Decision Process 马尔科夫决策过程
这是在Quora上对动态规划(DP)说明的极好的例子
writes down “1+1+1+1+1+1+1+1 =” on a sheet of paper
“What’s that equal to?”
counting “Eight!”
writes down another “1+” on the left
“What about that?”
quickly “Nine!”
“How’d you know it was nine so fast?”
“You just added one more”
"So you didn’t need to recount because you remembered there were eight! Dynamic Programming is just a fancy way to say ‘remembering stuff to save time later’ "
这一部分是对被称为 memorization部分的的解释。
1.1 Decision making 决策
决策是人类或任何生物为了维持生存和存在而进行的最基本的活动。作为一个生存的决策者,他们在一个复杂的、未知的、不可预测的、不断变化的环境中不断遇到各种各样的挑战。为了应对这些挑战,应在评估情况或环境变化后作出相应的决定。可以说,做出正确决定的能力不是与生俱来的,但幸运的是,他们可以通过学习环境经验的过程获得。当然,获得这种学习能力往往伴随着一定的成本。也就是说,他们必须通过尝试各种决策,包括错误的决策来学习正确的决策,以对环境做出反应,接受环境的反馈,并在未来的决策中更新自己的策略。
例子, AlphaGo, Autonomous Driving
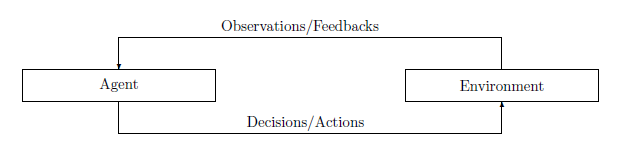
1.2 Modelling Sequential Decision Making
Definition 1.2 (Machine learning 机器学习).
机器学习是一个计算机程序,它 “关于某类任务 T \mathcal{T} T,从经验 E \mathcal{E} E中学习。它在 T \mathcal{T} T中的任务表现,由性能测量 P \mathcal{P} P度量,随着经验 E \mathcal{E} E的增加而提高”。
X \mathcal{X} X :状态空间,描述环境中所有情况的集合。
U \mathcal{U} U :可接受行动的集合。
X k , U k \mathcal{X}_k, \mathcal{U}_k Xk,Uk: 初始时间点之后的第 k k k个状态或阶段的可接受的状态空间和行动空间。
Definition 1.3 历史(history )或轨迹(trajectory )被定义为环境的状态和智能体的交互而产生的行动的序列,即。
h : = ( x 0 , u 0 , . . . , x N − 1 , u N − 1 , x N ) ∈ X 0 × U 0 × . . . × U N − 1 × X N (1.1) h :=(x_0,u_0,...,x_{N-1},u_{N-1},x_N) \in \mathcal{X}_0 \times \mathcal{U}_0 \times ... \times\mathcal{U}_{N-1} \times\mathcal{X}_N \tag{1.1} h:=(x0,u0,...,xN−1,uN−1,xN)∈X0×U0×...×UN−1×XN(1.1)
其中,
N N N: 交互的范围(horizon of interaction)
而当 范围(horizon ) 是有限的,相应的SDM问题被称为有限范围问题(finite horizon problem) 或RL背景下的事件问题(episodic problem)。
为了使状态转换问题更具有可操作性,我们需要建立一个系统演化的模型 ( x k , u k ) → x k + 1 (x_k, u_k) \to x_{k+1} (xk,uk)→xk+1。在一个状态 k k k,环境和智能体之间的交互被描述为以下离散时间动态系统
x k + 1 = f k ( x k , u k , w k ) , for k = 0 , . . . , N − 1 (1.2) x_{k+1} = f_k(x_k, u_k, w_k), \text{for} \ k = 0,..., N-1 \tag{1.2} xk+1=fk(xk,uk,wk),for k=0,...,N−1(1.2)
w k ∈ W k w_k \in \mathcal{W}_k wk∈Wk 表示阶段 k k k的扰动(perturbation) 或不确定性(uncertainty) 。
在状态 k k k的扰动可以由条件概率 p ( w k ∣ x k , u k ) p(w_k|x_k, u_k) p(wk∣xk,uk)驱动,而扰动往往要与历史无关,即 p ( w k ) p(w_k) p(wk)。我们用 h h h来表示轨迹或历史。在每个决策状态中,需要对轨迹 h h h进行适当的评估,以促进下一次决策。
Assumption 1.1 (Reinforcement hypothesis 强化假设).智能行为源于个人的行为,该行为寻求最大化其从环境中获得的奖励的积累。
具体来说,对于一个交互的基本部分( x k , u k , x k + 1 x_k, u_k, x_{k+1} xk,uk,xk+1)来说,我们可以构建一个实值评价,即对于 k = 0 , . . . , N − 1 k=0, ..., N-1 k=0,...,N−1来说
g k = X k × U k × W k → R , ( x k , u k , w k ) → g k ( x k , u k , w k ) . (1.3) g_k= \mathcal{X}_k \times \mathcal{U}_k \times \mathcal{W}_k \to \mathbb{R},\\ (x_k, u_k, w_k) \to g_k(x_k, u_k, w_k). \tag{1.3} gk=Xk×Uk×Wk→R,(xk,uk,wk)→gk(xk,uk,wk).(1.3)
这是一个局部评估函数, 对于一个基本的转换来说也被称为局部"成本去向函数(cost-to-go function) ", 或者在RL文献中被称为 奖励函数(reward function)。
Remark 1.1 (Cost function vs. reward function 成本函数 vs. 奖励函数)
DP和RL的区别可以从成本函数的选择来看。DP中的成本函数通常是客观地预先确定的。但在RL中,成本函数更多的是由解决方案提供者或工程师手动设计的。
使用(1.3)中定义的基本评估和强化假设,我们可以定义整个轨迹的评估,其中包括所有的局部转换,即
G ( h ) : = g N ( x N ) + ∑ k = 0 N − 1 g k ( x k , u k , w k ) (1.4) G(h):=g_N(x_N) + \sum_{k=0}^{N-1}g_k(x_k,u_k, w_k) \tag{1.4} G(h):=gN(xN)+k=0∑N−1gk(xk,uk,wk)(1.4)
其中 g N ( x N ) g_N(x_N) gN(xN)定义为在最终状态 N N N的的成本函数。为了使这种评估具有可比性, 通常假设成本函数具有边界性。
Assumption 1.2 (Bounded cost function 有边界的成本函数)
成本函数 g k ( x k , u k , w k ) g_k(x_k, u_k, w_k) gk(xk,uk,wk) 被假设为有边界, i.e., ∣ g k ( x k , u k , w k ) ∣ < ∞ for all k = 0 , . . . , N − 1 |g_k(x_k, u_k, w_k)| < \infin \text{ for all } k = 0, ..., N-1 ∣gk(xk,uk,wk)∣<∞ for all k=0,...,N−1
用 w : = [ w 0 , w 1 , . . . w N − 1 ] w :=[w_0, w_1, ... w_{N-1}] w:=[w0,w1,...wN−1]表示整个范围上的扰动,用 p ( w ) p(w) p(w)表示 w w w的概率密度函数。因此,从一个给定的初始状态 x 0 ∈ X 0 x_0\in \mathcal{X}_0 x0∈X0开始,跟随一连串的行动 π : = u 0 , u 1 , . . . , u N − 1 ∈ U 0 × . . . × U N − 1 \pi:= {u_0, u_1, ..., u_{N-1}} \in \mathcal{U}_0 \times ... \times\mathcal{U}_{N-1} π:=u0,u1,...
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1481
1481

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











