



 本文探讨了无监督多模态域自适应中的挑战,提出了一种新方法,包括张量对齐(TAL)模块和动态域生成器(DDG),旨在建立跨域和模态的共享表示,通过自监督学习改善特征对齐并减少信息冗余。
本文探讨了无监督多模态域自适应中的挑战,提出了一种新方法,包括张量对齐(TAL)模块和动态域生成器(DDG),旨在建立跨域和模态的共享表示,通过自监督学习改善特征对齐并减少信息冗余。
一、研究背景
无监督多模态域自适应有两个主要问题:域适应和模态对齐。现有工作通常用独立的两个阶段处理上述问题,因此难以利用域和模态之间的互补信息。
二、研究目标
1.探索域与模态之间的关系;
2.寻找一个共同的域不变、跨模态表示空间来同时对齐域和模态。
三、研究动机
直接使用原始源域、目标域特征进行对抗性学习效果不佳:不同域之间的差距极大,难以学到共有特征
直接进行特征混合会造成信息冗余和震荡。
四、技术路线
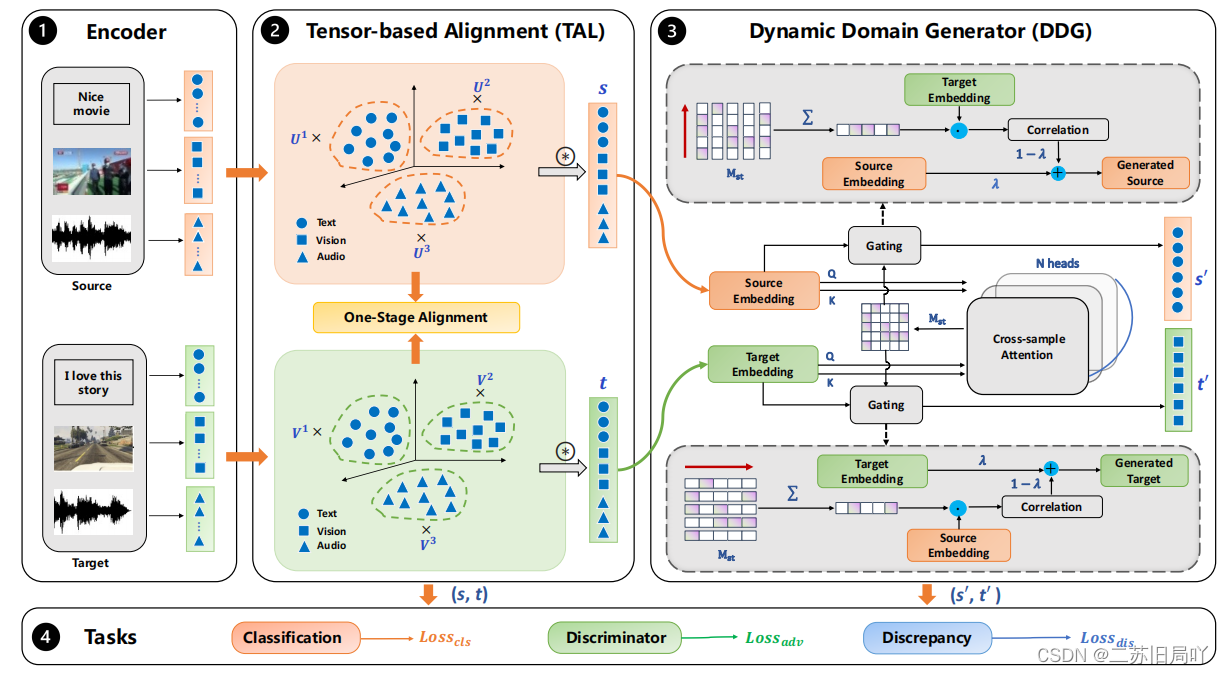
- Tensor-based Alignment:提出基于张量的对齐模块(TAL)来探索域和模态之间的关系,同时对齐域和模态,并利用互补信息获得更好的结果。
(1)建立特征对齐模型:
用U、VU、VU、V对源域、目标域各模态的特征进行映射,将其映射到两个(源、目标)低维子空间;
最大化不同域之间低维特征的相似度;
约束同一模态内低维特征的相似度矩阵为单位阵III;
因此,当实现最佳映射时,最大相似度为III,YV=XUYV=XUYV=XU。
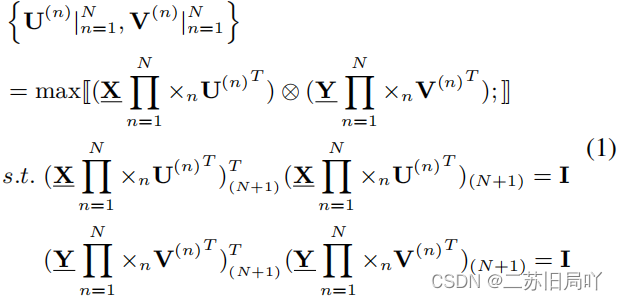
(2)模型求解:
分解为NNN个可求解的子问题;
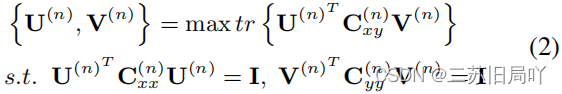
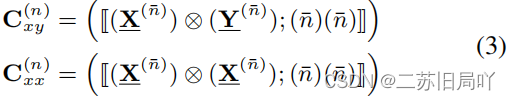
- Dynamic Domain Generator
提出动态域生成器(DDG)模块,通过自监督的方式混合两个域的共享信息来构建过渡样本。
(1)计算源-目标注意力矩阵MstM_{st}Mst
(2)根据MstM_{st}Mst选择共性元素ccc,进行融合特征计算
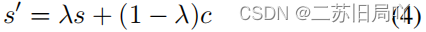

























 到【灌水乐园】发言
到【灌水乐园】发言









