



 研究针对身份交换任务,通过LSDA和特征空间操作,增强模型对多种伪造方法的鲁棒性,缓解过拟合。
研究针对身份交换任务,通过LSDA和特征空间操作,增强模型对多种伪造方法的鲁棒性,缓解过拟合。
一、研究背景
1.每种伪造方法都具有自己的特征。
2.如果检测器过拟合于训练数据特有的伪影信息而不是提取伪造方法的共有特征,当训练数据与测试数据的分布差异过大时,检测器性能会骤降。
3.可利用数据增强方法提高模型泛化性能,但现有基于数据增强的检测方法具有局限性:
- 像素级混合方法易受后处理步骤影响,呈现出的特有变化会造成过拟合。
- 不规则交换方法较容易识别。
- 依赖伪影进行检测不适用于全脸合成场景。
二、研究目标
1.主要针对身份交换任务进行研究。
2.通过样本插值来扩大伪造空间,以此鼓励模型习得更具泛化性的表征和更鲁棒的决策边界,缓解模型对特定伪造方法的过拟合。
三、研究动机
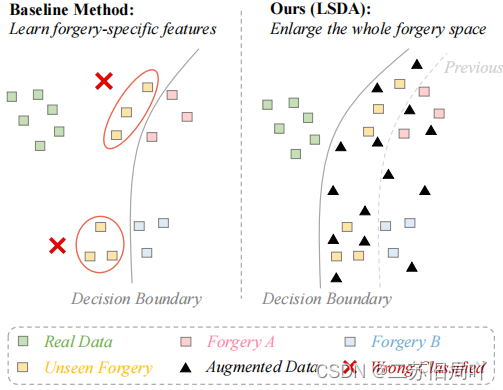
表征种类繁多的伪造类型需要更具泛化性的决策边界,从而减轻对特定方法的过拟合。
难样本可以在域内扩大特征空间。
四、技术路线
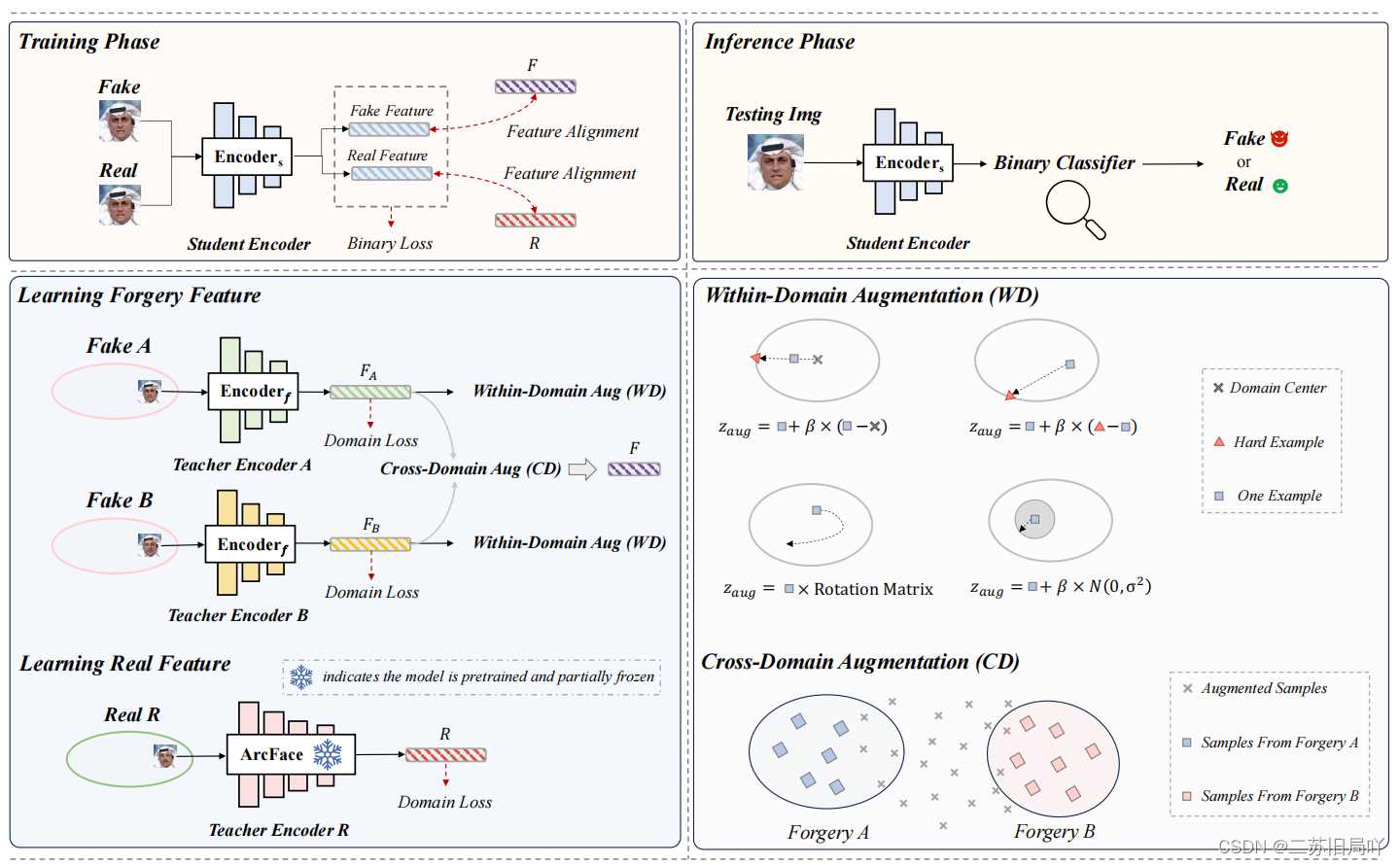
对潜在特征空间而不是传统空间进行操作,减轻域差异。提出LSDA(Latent Space Data Augmentation)检测器,利用数据增强提高伪造空间的多样性,利用预训练人脸识别模型学习更综合的真实人脸特征。
1.域内增强:通过插值难样本来获取更丰富域特有特征
- Centrifugal Transformation:转换为难样本,减轻对低级特征的过拟合
(1)直接转换:远离域中心μd\mu^dμd
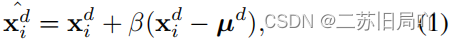
(2)间接转换:靠拢难样本ada^dad
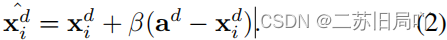
- Affine Transformation:旋转潜在特征的元素级位置信息,提取更鲁棒特征

- Additive Transformation:添加噪声,提取更鲁棒特征

2.跨域增强:通过插值特征明显的潜在向量来促进不同伪造类型间的平滑转换
- Mixup augmentation technique:混合d1d_1d1、d2d_2d2两种域的特征
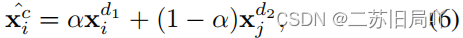
- 拼接域内增强、跨域增强特征
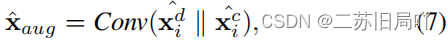
- 拼接增强特征、原始特征
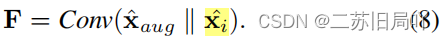
3.损失
- 多分类域损失:区分不同伪造域和真实域,令正确分类的概率接近1
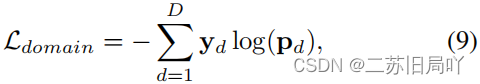
- 蒸馏损失:令真假样本特征图分别靠拢预训练真样本特征图和增强假样本特征图
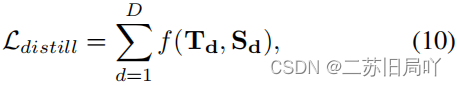
- 二元分类损失
利用增强特征进行知识蒸馏,获取更具泛化性的Deepfake检测器。
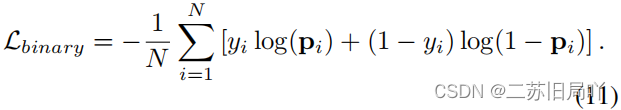
- 总损失
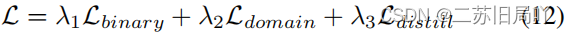
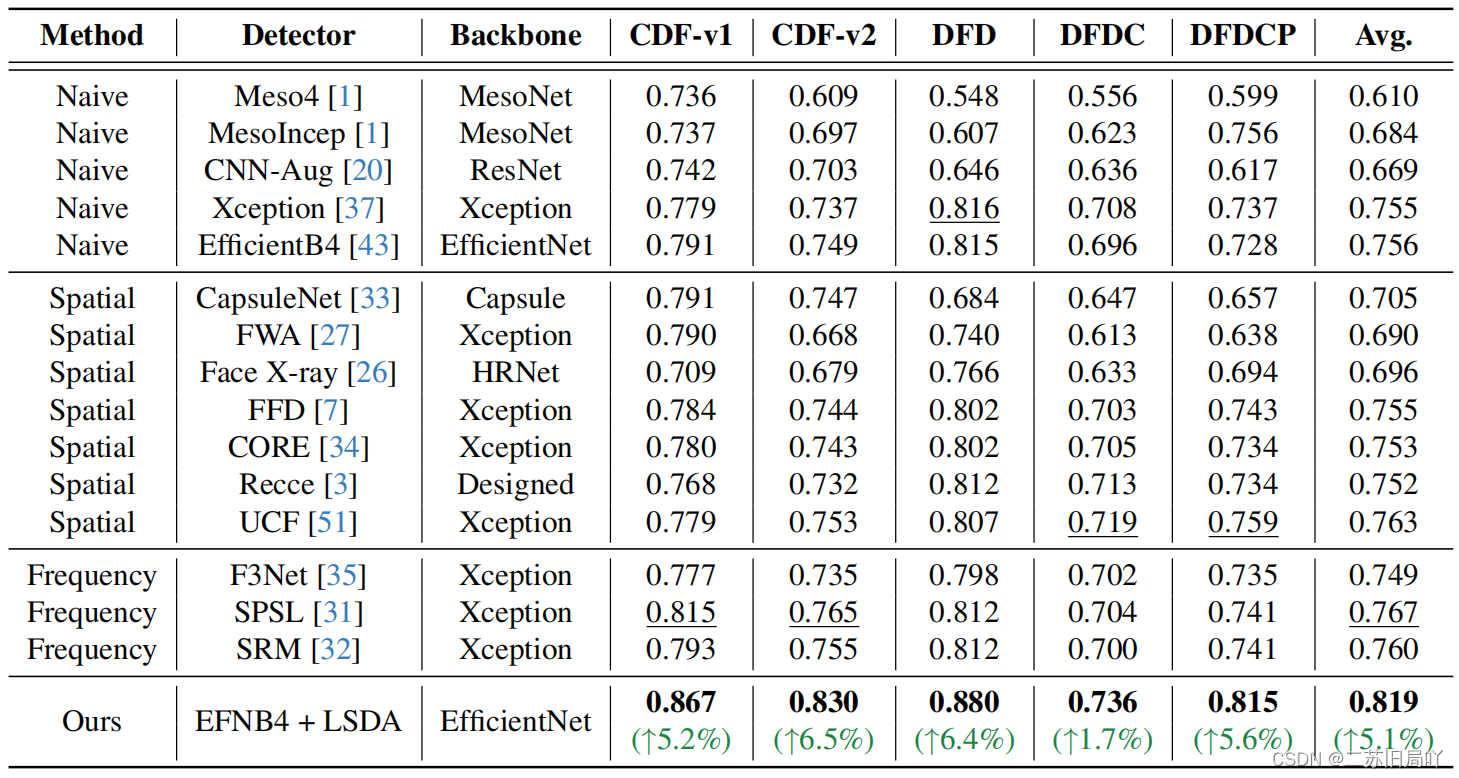
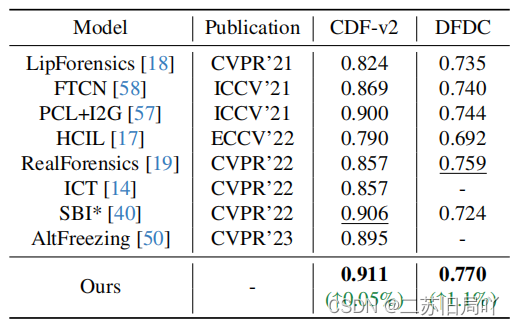
五、实验结果
1.帧级
2.视频级
六、思考
区分不同域的过程是扩大决策边界
域间平滑过渡是模糊不同域的差异,提取一致特征




















 462
462

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











