







 本文详细介绍了数据库索引的建立原则、优化方案及存储引擎的管理与优化,包括InnoDB与MyISAM的区别、事务特性、表空间管理等内容。
本文详细介绍了数据库索引的建立原则、优化方案及存储引擎的管理与优化,包括InnoDB与MyISAM的区别、事务特性、表空间管理等内容。

1. 建立索引的原则(DBA规范)

- 建表时一定要有主键,一般是个无关列
2. 选择唯一性索引
唯一性索引的值是唯一的,可以更快速的通过该索引来确定某条记录。
例如,学生表中学号是具有唯一性的字段。为该字段建立唯一性索引可以很快的确定某个学生的信息。
如果使用姓名的话,可能存在同名现象,从而降低查询速度。
#优化方案:
(1) 如果非得使用重复值较多的列作为查询条件(例如:男女),可以将表逻辑拆分
(2) 可以将此列和其他的查询类,做联和索引
select count(*) from world.city;
select count(distinct countrycode) from world.city;
select count(distinct countrycode,population ) from world.city;
- 为经常需要where 、ORDER BY、GROUP BY,join on等操作的字段,排序操作会浪费很多时间
如果为其建立索引,优化查询
注:如果经常作为条件的列,重复值特别多,可以建立联合索引。
4. 尽量使用前缀来索引
如果索引字段的值很长,最好使用值的前缀来索引。
5 限制索引的数目
索引的数目不是越多越好。
可能会产生的问题:
(1) 每个索引都需要占用磁盘空间,索引越多,需要的磁盘空间就越大。
(2) 修改表时,对索引的重构和更新很麻烦。越多的索引,会使更新表变得很浪费时间。
(3) 优化器的负担会很重,有可能会影响到优化器的选择.
percona-toolkit中有个工具,专门分析索引是否有用
- 删除不再使用或者很少使用的索引(percona toolkit)
pt-duplicate-key-checker
表中的数据被大量更新,或者数据的使用方式被改变后,原有的一些索引可能不再需要。数据库管理
员应当定期找出这些索引,将它们删除,从而减少索引对更新操作的影响。
7. 大表加索引,要在业务不繁忙期间操作
https://www.cnblogs.com/TeyGao/p/7160421.html
pt-osc(了解)
- 尽量少在经常更新值的列上建索引
- 建索引原则
(1) 必须要有主键,如果没有可以做为主键条件的列,创建无关列
(2) 经常做为where条件列 order by group by join on, distinct 的条件(业务:产品功能+用户行为)
(3) 最好使用唯一值多的列作为索引,如果索引列重复值较多,可以考虑使用联合索引
(4) 列值长度较长的索引列,我们建议使用前缀索引.
(5) 降低索引条目,一方面不要创建没用索引,不常使用的索引清理,percona toolkit(xxxxx)
(6) 索引维护要避开业务繁忙期
1.2 面试题:有索引,为什么查询效率还是很低?
1.有索引不走
2.联合索引没有完全覆盖
3.索引失效或同级信息不真实
4.索引重复值太多
我一般遇到这样的问题,排查和解决的方法有这几种方法
1.先看看这个语句的执行计划
table type key_len 判断联合索引覆盖长度 extra 额外排序 rows 重复值 ----->2.没索引建索引,改语句
2.建索引规范:
1. 主键
2. where group by order by distinct join on
3. 联合最左侧,唯一值
4. 尽量使用前缀索引
5. 索引条目
6. 频繁更新的列,不适合做索引列,
7. 避开业务繁忙期,pt-tools
3. 不走索引:
1. 本来全表扫描
2. 25%
3. 计算或函数
4. 隐式转换
5. like %xx%
6. != ,not in
7. 索引失效,统计信息不真实
数据库第一阶段END.
第五章节 存储引擎
第六章节 日志管理
第七章节 备份恢复和迁移
第八章节 主从基础和进阶
第九部分 高可用和读写分离
====================================
第十章节 分布式架构
十一章节 全面优化
NoSQL :
十二章节MongoDB
十三章节Redis
十四章节ES (待定)
十五章节 珍藏已久的就业指导
RDS 云数据库扩展
第五章 存储引擎
1. 简介
相当于Linux文件系统,只不过比文件系统强大
2. MySQL 存储引擎类型(笔试:3-4种)

oldguo[world]>show engines;
oldguo[world]>select @@default_storage_engine;
oldguo[world]>show variables like '%engine%';
InnoDB (5.5以后默认存储引擎) *****
MyISAM (5.5 以前的默认存储引擎) ***
MEMORY
ARCHIVE
EXAMPLE
BLACKHOLE
MERGE
NDBCLUSTER
CSV
FEDERATED (Oracle(dblink) ----> MySQL)**
第三方的存储引擎:
TokuDB
MyRocks
RocksDB
TokuDB优势:
1. 压缩比高
2. 插入性能很高
2.2 简历案例:
环境: zabbix 3.2 mariaDB 5.5 centos 7.3
现象 : zabbix卡的要死 , 每隔3-4个月,都要重新搭建一遍zabbix
问题 :
1. zabbix 版本
2. 数据库版本
3. zabbix数据库500G,存在一个文件里
优化建议:
* 1.数据库版本升级到10.x最新版本,zabbix升级更高版本
* 2 .存储引擎改为tokudb
3.监控数据按月份进行切割(二次开发:zabbix 数据保留机制功能重写,数据库分表)
* 4.关闭binlog和双1
* 5.参数调整....
优化结果:
监控状态良好
为什么?
1. 原生态支持tokudb,另外经过测试环境mariaDB 版本性能高, 2-3倍
2. TokuDB:insert数据比Innodb快的多,数据压缩比要Innodb高
3.监控数据按月份进行切割,为了能够truncate每个分区表,立即释放空间
4.关闭binlog ----->减少无关日志的记录
5.参数调整...----->安全性参数关闭,提高性能
3. InnoDB 与 MyISAM 的区别(笔试题)
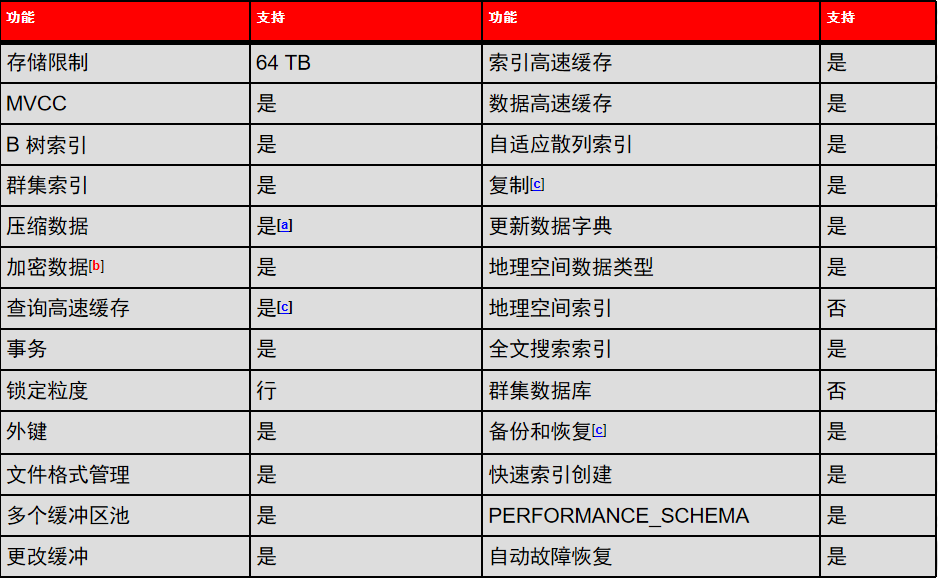
1、事务(Transaction)
2、MVCC(Multi-Version Concurrency Control多版本并发控制)
3、行级锁(Row-level Lock)
4、ACSR(Auto Crash Safey Recovery)自动的故障安全恢复
5、支持热备份(Hot Backup)
6、Replication: Group Commit , GTID (Global Transaction ID) ,多线程(Multi-Threads-SQL )
7. 索引 B+tree B*TREE
3.2 项目:某急送
环境: centos 5.8 ,MySQL 5.0版本,MyISAM存储引擎,网站业务(LNMPT),数据量50G左右
现象问题: 业务压力大的时候,非常卡;经历过宕机,会有部分数据丢失.
问题分析:
1.MyISAM存储引擎表级锁,在高并发时,会有很高锁等待
2.MyISAM存储引擎不支持事务,在断电时,会有可能丢失数据
职责
1.监控锁的情况:有很多的表锁等待
2.存储引擎查看:所有表默认是MyISAM
解决方案:
1.升级MySQL 5.6.10版本
2. 迁移所有表到新环境
3. 开启双1安全参数
4. 存储引擎查看简单修改
show engines
select @@default_storage_engine;
select table_name ,engine from information_schema.tables where table_schema='world';
oldguo[world]>create table t (id int) engine=myisam;
oldguo[world]>show create table t;
oldguo[world]>alter table t engine=innodb;
小扩展: 将world库下所有表的引擎替换为innoDB
select concat("alter table ",table_name," engine=innodb") from information_schema.tables where table_schema='world';
oldguo[world]>alter table t engine=innodb; 整理碎片
5. 存储引擎查看
5.1 使用 SELECT 确认会话存储引擎
SELECT @@default_storage_engine;
5.2 存储引擎(不代表生产操作)
会话级别:
set default_storage_engine=myisam;
全局级别(仅影响新会话):
set global default_storage_engine=myisam;
重启之后,所有参数均失效.
如果要永久生效:
写入配置文件
vim /etc/my.cnf
[mysqld]
default_storage_engine=myisam
存储引擎是表级别的,每个表创建时可以指定不同的存储引擎,但是我们建议统一为innodb.
5.3 SHOW 确认每个表的存储引擎:
SHOW CREATE TABLE city\G;
5.4 INFORMATION_SCHEMA 确认每个表的存储引擎
select table_schema,table_name ,engine from information_schema.tables where table_schema not in ('sys','mysql','information_schema','performance_schema');
select table_schema,table_name ,engine from information_schema.tables where table_schema not in ('sys','mysql','information_schema','performance_schema');
5.5 修改一个表的存储引擎
mysql[oldboy]>alter table t1 engine innodb;
注意:此命令我们经常使用他,进行innodb表的碎片整理
5.6 平常处理过的MySQL问题–碎片处理
环境:
centos7.4,MySQL 5.7.20,InnoDB存储引擎
业务特点:
数据量级较大,经常需要按月删除历史数据.
问题:
磁盘空间占用很大,不释放
处理方法:
以前:
将数据逻辑导出,手工drop表,然后导入进去
现在:
对表进行按月进行分表(partition,中间件)
业务替换为truncate方式
5.7 扩展:如何批量修改
需求:将zabbix库中的所有表,innodb替换为tokudb
需求:将zabbix库中的所有表,innodb替换为tokudb
select concat("alter table zabbix.",table_name," engine tokudb;") from information_schema.tables where table_schema='zabbix' into outfile '/tmp/tokudb.sql';
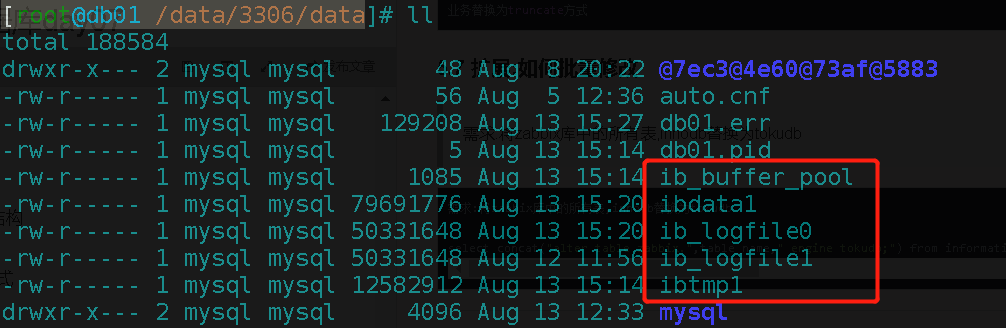
6. InnoDB存储引擎物理存储结构
6.1 InnoDB 最直观的存储方式
city.frm 表的列定义
city.ibd 表的数据和索引 ☆☆☆☆☆
ibdata1(5.7) 共享表空间文件(UNDO回滚数据(8.0独立),系统数据字典) ☆☆☆☆☆
ib_logfile0 ~ ib_logfileN redo log文件 ☆☆☆☆☆
ibtmp1(5.7) 存放临时表
ib_buffer_pool 缓冲区池的映射文件
6.2 InnoDB 的表空间管理模式
https://www.cnblogs.com/littlehb/archive/2013/05/08/3067095.html
共享表空间模式(5.5 默认)
ibdata1:目前遗留下来了,用来存储系统数据.
=============================================
5.5版本出现的管理模式,也是默认的管理模式。
5.6版本以,共享表空间保留,只用来存储:系统数据字典信息,undo,临时表。
5.7 版本,临时表被独立出来了
8.0版本,undo也被独立出去了
=============================================
独立表空间模式(5.6以后默认)
一个表一个ibd文件
6.3 共享表空间的设置
mysql[world]>select @@innodb_data_file_path; ---一般是在初始化数据之前
vim /etc/my.cnf
innodb_data_file_path=ibdata1:512M:ibdata2:512M:autoextend
oldguo[(none)]>show variables like '%extend%';
6.4 独立表空间设置
MySQL[(none)]>select @@innodb_file_per_table;
1:on 0:off
共享表空间体验(不代表生产操作):
MySQL[(none)]>set global innodb_file_per_table=0;
6.5 独立表空间迁移
alter table t1 discard tablespace;
alter table t1 import tablespace;
DDL DCL DML
city表 ----> 独立表空间 ------> 表空间数据文件:city.ibd -----> 段 区 页
innoDB表 : ibdata1 + frm + ibd
6.6 真实的学生案例
案例背景:
硬件及软件环境:
联想服务器(IBM)
磁盘500G 没有raid
centos 6.8
mysql 5.6.33 innodb引擎 独立表空间
备份没有,日志也没开
开发用户专用库:
jira(bug追踪) 、 confluence(内部知识库) ------>LNMT
故障描述:
断电了,启动完成后“/” 只读
fsck 重启,系统成功启动,mysql启动不了。
结果:confulence库在 , jira库不见了
学员求助内容:
求助:
这种情况怎么恢复?
我问:
有备份没
求助:
连二进制日志都没有,没有备份,没有主从
我说:
没招了,jira需要硬盘恢复了。
求助:
1、jira问题拉倒中关村了
2、能不能暂时把confulence库先打开用着
将生产库confulence,拷贝到1:1虚拟机上/var/lib/mysql,直接访问时访问不了的
问:有没有工具能直接读取ibd
我说:我查查,最后发现没有
我想出一个办法来:
表空间迁移:
create table xxx
alter table confulence.t1 discard tablespace;
alter table confulence.t1 import tablespace;
虚拟机测试可行。
处理问题思路:
confulence库中一共有107张表。
1、创建107和和原来一模一样的表。
他有2016年的历史库,我让他去他同时电脑上 mysqldump备份confulence库
mysqldump -uroot -ppassw0rd -B confulence --no-data >test.sql
拿到你的测试库,进行恢复
到这步为止,表结构有了。
2、表空间删除。
select concat('alter table ',table_schema,'.'table_name,' discard tablespace;') from information_schema.tables where table_schema='confluence' into outfile '/tmp/discad.sql';
source /tmp/discard.sql
执行过程中发现,有20-30个表无法成功。主外键关系
很绝望,一个表一个表分析表结构,很痛苦。
set foreign_key_checks=0 跳过外键检查。
把有问题的表表空间也删掉了。
3、拷贝生产中confulence库下的所有表的ibd文件拷贝到准备好的环境中
select concat('alter table ',table_schema,'.'table_name,' import tablespace;') from information_schema.tables where table_schema='confluence' into outfile '/tmp/discad.sql';
4、验证数据
表都可以访问了,数据挽回到了出现问题时刻的状态(2-8)
7. InnoDB核心特性–事务(Transaction)
7.1 简介
事务:保证在一个完整业务逻辑中,所有涉及到的语句,要么全成功,要么全失败
7.2 ACID
资料链接:https://blog.youkuaiyun.com/dengjili/article/details/82468576
#Atomic(原子性)
所有语句作为一个单元全部成功执行或全部取消。不能出现中间状态。
#Consistent(一致性)
如果数据库在事务开始时处于一致状态,则在执行该事务期间将保留一致状态。
#Isolated(隔离性)
事务之间不相互影响。
#Durable(持久性)
事务成功完成后,所做的所有更改都会准确地记录在数据库中。所做的更改不会丢失。

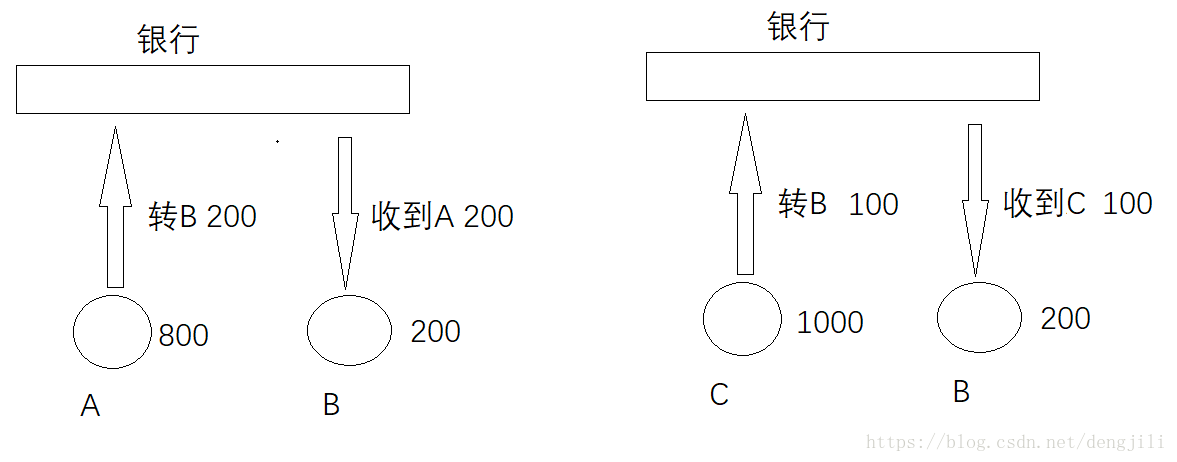
原子性
这个过程包含两个步骤
A: 800 - 200 = 600
B: 200 + 200 = 400
原子性表示,这两个步骤一起成功,或者一起失败,不能只发生其中一个动作
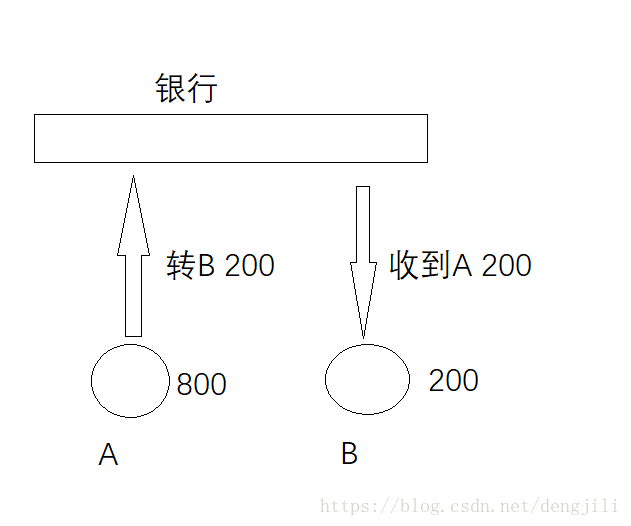
一致性(Consistency)
操作前A:800,B:200
操作后A:600,B:400一致性表示事务完成后,符合逻辑运算
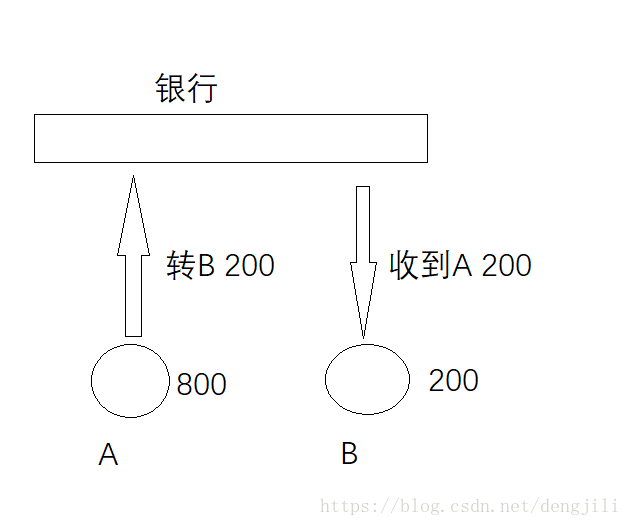
持久性(Durability)
表示事务结束后的数据不随着外界原因导致数据丢失操作前A:800,B:200
操作后A:600,B:400
如果在操作前(事务还没有提交)服务器宕机或者断电,那么重启数据库以后,数据状态应该为
A:800,B:200
如果在操作后(事务已经提交)服务器宕机或者断电,那么重启数据库以后,数据状态应该为
A:600,B:400
隔离性(Isolation)
两个事务同时进行,其中一个事务读取到另外一个事务还没有提交的数据,B
7.3 事务的生命周期管理(控制语句)
1. 开启事务
begin;
或者:
start transaction;
2. 标准的事务语句(DML: insert update delete)
oldguo[world]>delete from city where id>1000;
oldguo[world]>delete from city where id<500;
3. 事务的结束
(1) rollback; 回滚
oldguo[world]>begin;
oldguo[world]>delete from city where id>1000;
oldguo[world]>delete from city where id<500;
oldguo[world]>rollback;
(2) commit ;
oldguo[world]>begin;
oldguo[world]>delete from city where id>1000;
oldguo[world]>delete from city where id<500;
oldguo[world]>commit;
4. 自动提交功能
select @@autocommit;
set autocommit=0;
set global autocommit=0;
vim /etc/my.cnf
autocommit=0
5. 隐式提交的语句
用于隐式提交的 SQL 语句:
begin
a
b
begin
SET AUTOCOMMIT = 1
导致提交的非事务语句:
DDL语句: (ALTER、CREATE 和 DROP)
DCL语句: (GRANT、REVOKE 和 SET PASSWORD)
锁定语句:(LOCK TABLES 和 UNLOCK TABLES)
导致隐式提交的语句示例:
TRUNCATE TABLE
LOAD DATA INFILE
SELECT FOR UPDATE
未完待续…


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









