




 本文深入解析Spark中的WordCount案例,详细介绍了WordCount在Spark中的运行流程,包括从读取文件到执行计算的全过程,以及涉及的RDD转换和行动操作。
本文深入解析Spark中的WordCount案例,详细介绍了WordCount在Spark中的运行流程,包括从读取文件到执行计算的全过程,以及涉及的RDD转换和行动操作。
wordcount代码
wordcount作为大多数spark甚至大数据学习阶段的第一个案例,具有很好的教学意义,本文同样使用wordcount作为案例,对它在spark中的运行过程作一个详细的讲解。
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object WordCountScala {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("wordcount")
//本地运行
conf.setMaster("local")
val sc = new SparkContext(conf)
//单词统计
//DATASET
//hello world
// fileRDD.flatMap( _.split(" ") ).map((_,1)).reduceByKey( _+_ ).foreach(println)
val fileRDD: RDD[String] = sc.textFile("bigdata-spark/data/testdata.txt")
//hello world
val words: RDD[String] = fileRDD.flatMap((x:String)=>{x.split(" ")})
//hello
//world
val pairWord: RDD[(String, Int)] = words.map((x:String)=>{new Tuple2(x,1)})
//(hello,1)
//(hello,1)
//(world,1)
val res: RDD[(String, Int)] = pairWord.reduceByKey( (x:Int,y:Int)=>{x+y} )
//X:oldValue Y:value
//(hello,2) -> (2,1)
//(world,1) -> (1,1)
//(msb,2) -> (2,1)
val fanzhuan: RDD[(Int, Int)] = res.map((x)=>{ (x._2,1) })
val resOver: RDD[(Int, Int)] = fanzhuan.reduceByKey(_+_)
resOver.foreach(println)
res.foreach(println)
Thread.sleep(Long.MaxValue)
}
}
首先我们忽略前面的参数配置过程,从sc.textfile()开始进行分析,sc(SparkContext)的源码不做分析,进入textfile()(鼠标移动到方法名上,cltr+鼠标左键)。
/**
* Read a text file from HDFS, a local file system (available on all nodes), or any
* Hadoop-supported file system URI, and return it as an RDD of Strings.
* @param path path to the text file on a supported file system
* @param minPartitions suggested minimum number of partitions for the resulting RDD
* @return RDD of lines of the text file
*/
def textFile(
path: String,
minPartitions: Int = defaultMinPartitions): RDD[String] = withScope {
assertNotStopped()
//注意,这里看到默认的文本输入类就是TextInputFormat,与mapreduce一样
//TextInputFormat会拿到splits信息和recoredreader
//这个方法传入的参数有,文件路径Path,TextInputFormat,<k,v>类型
hadoopFile(path, classOf[TextInputFormat], classOf[LongWritable], classOf[Text],
minPartitions).map(pair => pair._2.toString).setName(path)
}
第一个参数传了path,就是文件路径,第二个参数minpartitions,最小分区数,用户可以自己定义minpartitions,但是不一定会取到它,因为spark取并行度的原则是并行度最高优先,比如用户定义了一个minpartitions为10,而程序计算出来的minpartitions是15,那么取二者的最大值,也就是15,;如果用户定义的并行度为 20,程序算出来的并行度为15,那么就取20。继续看,发现这里调用了一个hadoopfile().map()方法,我们看看这个hadoopfile()是什么。
/** Get an RDD for a Hadoop file with an arbitrary InputFormat
*
* @note Because Hadoop's RecordReader class re-uses the same Writable object for each
* record, directly caching the returned RDD or directly passing it to an aggregation or shuffle
* operation will create many references to the same object.
* If you plan to directly cache, sort, or aggregate Hadoop writable objects, you should first
* copy them using a `map` function.
* @param path directory to the input data files, the path can be comma separated paths
* as a list of inputs
* @param inputFormatClass storage format of the data to be read
* @param keyClass `Class` of the key associated with the `inputFormatClass` parameter
* @param valueClass `Class` of the value associated with the `inputFormatClass` parameter
* @param minPartitions suggested minimum number of partitions for the resulting RDD
* @return RDD of tuples of key and corresponding value
*/
def hadoopFile[K, V](
path: String,
inputFormatClass: Class[_ <: InputFormat[K, V]],
keyClass: Class[K],
valueClass: Class[V],
minPartitions: Int = defaultMinPartitions): RDD[(K, V)] = withScope {
assertNotStopped()
// This is a hack to enforce loading hdfs-site.xml.
// See SPARK-11227 for details.
FileSystem.getLocal(hadoopConfiguration)
// A Hadoop configuration can be about 10 KB, which is pretty big, so broadcast it.
val confBroadcast = broadcast(new SerializableConfiguration(hadoopConfiguration))
val setInputPathsFunc = (jobConf: JobConf) => FileInputFormat.setInputPaths(jobConf, path)
new HadoopRDD(
this,
confBroadcast,
Some(setInputPathsFunc),
inputFormatClass,
keyClass,
valueClass,
minPartitions).setName(path)
}
我们看到这里最终返回了一个HadoopRDD,也就是说这个fileRDD就是一个HadoopRDD,我们看一下这个HadoopRDD是什么。
class HadoopRDD[K, V](
sc: SparkContext,
broadcastedConf: Broadcast[SerializableConfiguration],
initLocalJobConfFuncOpt: Option[JobConf => Unit],
inputFormatClass: Class[_ <: InputFormat[K, V]],
keyClass: Class[K],
valueClass: Class[V],
minPartitions: Int)
extends RDD[(K, V)](sc, Nil) with Logging {
可以看到,这个HadoopRDD是RDD的一个子类,并将scparkcontext和一个Nil(这个Nil就是java中的null)传进去。我们看一下RDD类。
abstract class RDD[T: ClassTag](
@transient private var _sc: SparkContext,
@transient private var deps: Seq[Dependency[_]]
) extends Serializable with Logging {
这里的第二个参数deps表示的是依赖,我们用图来解释一下什么是依赖。
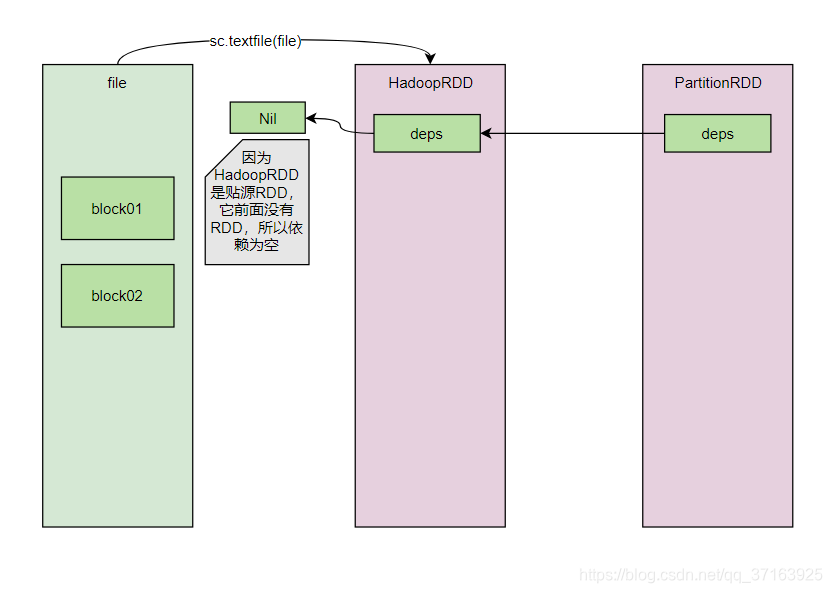
RDD的依赖就像是一个单链表,后一个RDD的依赖中包含了前一个RDD。此外,HadoopRDD中还包含了2个重要的方法:GetPartitions()和compute(),我们首先来看看GetPartitions()。
override def getPartitions: Array[Partition] = {
val jobConf = getJobConf()
// add the credentials here as this can be called before SparkContext initialized
SparkHadoopUtil.get.addCredentials(jobConf)
val allInputSplits = getInputFormat(jobConf).getSplits(jobConf, minPartitions)
val inputSplits = if (ignoreEmptySplits) {
allInputSplits.filter(_.getLength > 0)
} else {
allInputSplits
}
val array = new Array[Partition](inputSplits.size)
for (i <- 0 until inputSplits.size) {
array(i) = new HadoopPartition(id, i, inputSplits(i))
}
array
}
这里有一个`getsplits()`方法,了解过MapReduce的同学对它一定不陌生,因为MapReduce也有`getsplits()`这个方法,进去看我们就会发现,这个`getsplits()`方法的实现逻辑和MapReduce几乎一模一样。
/** Splits files returned by {@link #listStatus(JobConf)} when
* they're too big.*/
public InputSplit[] getSplits(JobConf job, int numSplits)
throws IOException {
Stopwatch sw = new Stopwatch().start();
FileStatus[] files = listStatus(job);
// Save the number of input files for metrics/loadgen
job.setLong(NUM_INPUT_FILES, files.length);
long totalSize = 0; // compute total size
for (FileStatus file: files) { // check we have valid files
if (file.isDirectory()) {
throw new IOException("Not a file: "+ file.getPath());
}
totalSize += file.getLen();
}
long goalSize = totalSize / (numSplits == 0 ? 1 : numSplits);
long minSize = Math.max(job.getLong(org.apache.hadoop.mapreduce.lib.input.
FileInputFormat.SPLIT_MINSIZE, 1), minSplitSize);
// generate splits
ArrayList<FileSplit> splits = new ArrayList<FileSplit>(numSplits);
NetworkTopology clusterMap = new NetworkTopology();
for (FileStatus file: files) {
Path path = file.getPath();
long length = file.getLen();
if (length != 0) {
FileSystem fs = path.getFileSystem(job);
BlockLocation[] blkLocations;
if (file instanceof LocatedFileStatus) {
blkLocations = ((LocatedFileStatus) file).getBlockLocations();
} else {
blkLocations = fs.getFileBlockLocations(file, 0, length);
}
if (isSplitable(fs, path)) {
long blockSize = file.getBlockSize();
long splitSize = computeSplitSize(goalSize, minSize, blockSize);
long bytesRemaining = length;
while (((double) bytesRemaining)/splitSize > SPLIT_SLOP) {
String[][] splitHosts = getSplitHostsAndCachedHosts(blkLocations,
length-bytesRemaining, splitSize, clusterMap);
splits.add(makeSplit(path, length-bytesRemaining, splitSize,
splitHosts[0], splitHosts[1]));
bytesRemaining -= splitSize;
}
if (bytesRemaining != 0) {
String[][] splitHosts = getSplitHostsAndCachedHosts(blkLocations, length
- bytesRemaining, bytesRemaining, clusterMap);
splits.add(makeSplit(path, length - bytesRemaining, bytesRemaining,
splitHosts[0], splitHosts[1]));
}
} else {
String[][] splitHosts = getSplitHostsAndCachedHosts(blkLocations,0,length,clusterMap);
splits.add(makeSplit(path, 0, length, splitHosts[0], splitHosts[1]));
}
} else {
//Create empty hosts array for zero length files
splits.add(makeSplit(path, 0, length, new String[0]));
}
}
sw.stop();
if (LOG.isDebugEnabled()) {
LOG.debug("Total # of splits generated by getSplits: " + splits.size()
+ ", TimeTaken: " + sw.elapsedMillis());
}
return splits.toArray(new FileSplit[splits.size()]);
}
这里我们不再赘述getsplits()方法,接着看compute()方法。
override def compute(theSplit: Partition, context: TaskContext): InterruptibleIterator[(K, V)] = {
val iter = new NextIterator[(K, V)] {
private val split = theSplit.asInstanceOf[HadoopPartition]
logInfo("Input split: " + split.inputSplit)
private val jobConf = getJobConf()
private val inputMetrics = context.taskMetrics().inputMetrics
private val existingBytesRead = inputMetrics.bytesRead
// Sets InputFileBlockHolder for the file block's information
split.inputSplit.value match {
case fs: FileSplit =>
InputFileBlockHolder.set(fs.getPath.toString, fs.getStart, fs.getLength)
case _ =>
InputFileBlockHolder.unset()
}
这里我们可以看到,compute()方法里创建了一个迭代器NextIterator[(K, V)],我们进入这个迭代器。
override def hasNext: Boolean = {
if (!finished) {
if (!gotNext) {
nextValue = getNext()
if (finished) {
closeIfNeeded()
}
gotNext = true
}
}
!finished
}
override def next(): U = {
if (!hasNext) {
throw new NoSuchElementException("End of stream")
}
gotNext = false
nextValue
}
迭代器有hasNext()和next()方法,这就是获取文件中<key,value>的方法,也就是说,compute()方法通过这个迭代器来迭代获取<k,v>数据。值得一提的是:getPartition()和compute()方法并没有被执行。现在我们来更新一下我们的图。
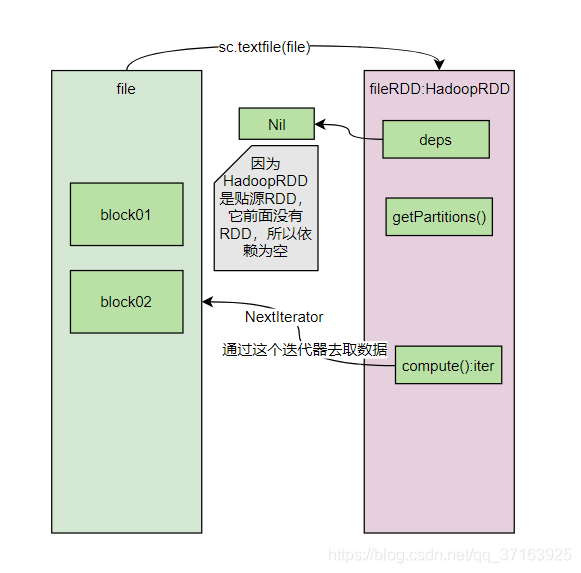
至此我们已经得到了第一个RDD:fileRDD(是的,只是完成了第一行逻辑运算过程的分析),下面我们进入到第二行,进入flatMap()方法。
val words: RDD[String] = fileRDD.flatMap((x:String)=>{x.split(" ")})
/**
* Return a new RDD by first applying a function to all elements of this
* RDD, and then flattening the results.
*/
def flatMap[U: ClassTag](f: T => TraversableOnce[U]): RDD[U] = withScope {
//clean(f)是将函数f序列化,并将其闭包进一个flatMap()中分发出去
val cleanF = sc.clean(f)
new MapPartitionsRDD[U, T](this, (context, pid, iter) => iter.flatMap(cleanF))
}
我们看到,flatMap()方法里又定义了一个新的RDD:MapPartitionsRDD,而且在new MapPartitionsRDD的时候还将 f 这个匿名函数传进去了,并且最终会调用一个迭代器去执行flatMap(cleanF)方法,我们进入MapPartitionsRDD去看看。
private[spark] class MapPartitionsRDD[U: ClassTag, T: ClassTag](
var prev: RDD[T],
f: (TaskContext, Int, Iterator[T]) => Iterator[U], // (TaskContext, partition index, iterator)
preservesPartitioning: Boolean = false,
isOrderSensitive: Boolean = false)
extends RDD[U](prev) {
override val partitioner = if (preservesPartitioning) firstParent[T].partitioner else None
override def getPartitions: Array[Partition] = firstParent[T].partitions
override def compute(split: Partition, context: TaskContext): Iterator[U] =
f(context, split.index, firstParent[T].iterator(split, context))
override def clearDependencies() {
super.clearDependencies()
prev = null
}
注意,这里的prev指的是前一个RDD,也就是fileRDD,MapPartitionsRDD在调用RDD的构造方法时将fileRDD传给了RDD,这样MapPartitionsRDD就持有了一个对fileRDD的引用。并且函数 f 也被传进来了,我们看一下这个RDD的构造方法。
def this(@transient oneParent: RDD[_]) =
this(oneParent.context, List(new OneToOneDependency(oneParent)))
这里我们看到,MapPartitionsRDD和fileRDD的 依赖关系是一对一的(OneToOneDependency(oneParent)),所以MapPartitionsRDD中也有一个deps,并且和fileRDD是一对一的。我们更新一下图。
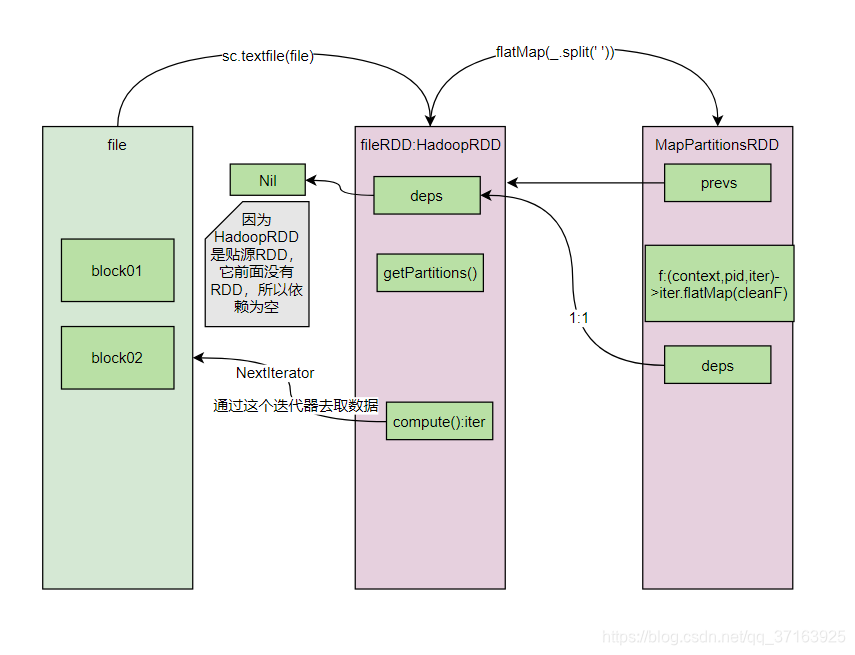
我们注意到,MapPartiotion中也有一个compute()方法,我们看看这个compute()方法。
override def compute(split: Partition, context: TaskContext): Iterator[U] =
f(context, split.index, firstParent[T].iterator(split, context))
我们看到,传进来的 f 函数在这里被调起了,第一个参数sparkcontext是它自己的context,第二个参数是切片的分区数,第三个参数是前一个RDD的iterator()方法。但是HadoopRDD类中并没有iterator()方法,所以我们去它的父类RDD中找。
/**
* Internal method to this RDD; will read from cache if applicable, or otherwise compute it.
* This should ''not'' be called by users directly, but is available for implementors of custom
* subclasses of RDD.
*/
final def iterator(split: Partition, context: TaskContext): Iterator[T] = {
if (storageLevel != StorageLevel.NONE) {
getOrCompute(split, context)
} else {
computeOrReadCheckpoint(split, context)
}
}
看这段代码的逻辑,如果没有缓存和持久化,那么它就会调用自己的compute()方法,这样我们发现,MapPartitinsRDD调用了fileRDD的iterator方法,fileRDD的iterator方法又调用了自己的compute()方法,compute()方法会返回一个拉取数据的迭代器,我们来更新一下图。
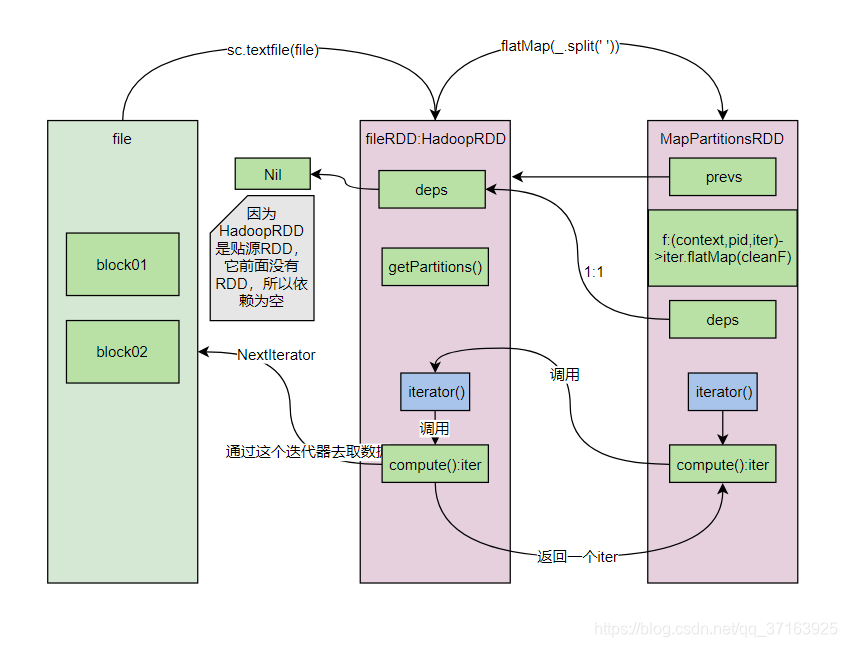
至此,第二行逻辑代码val words: RDD[String] = fileRDD.flatMap((x:String)=>{x.split(" ")})分析完毕,我们进入第三行,val pairWord: RDD[(String, Int)] = words.map((x:String)=>{new Tuple2(x,1)})
/**
* Return a new RDD by applying a function to all elements of this RDD.
*/
def map[U: ClassTag](f: T => U): RDD[U] = withScope {
val cleanF = sc.clean(f)
new MapPartitionsRDD[U, T](this, (context, pid, iter) => iter.map(cleanF))
}
这段代码和flatMap()的代码几乎一模一样,其实map()方法的执行逻辑和flatMap()方法是一样的。我们更新一下图。
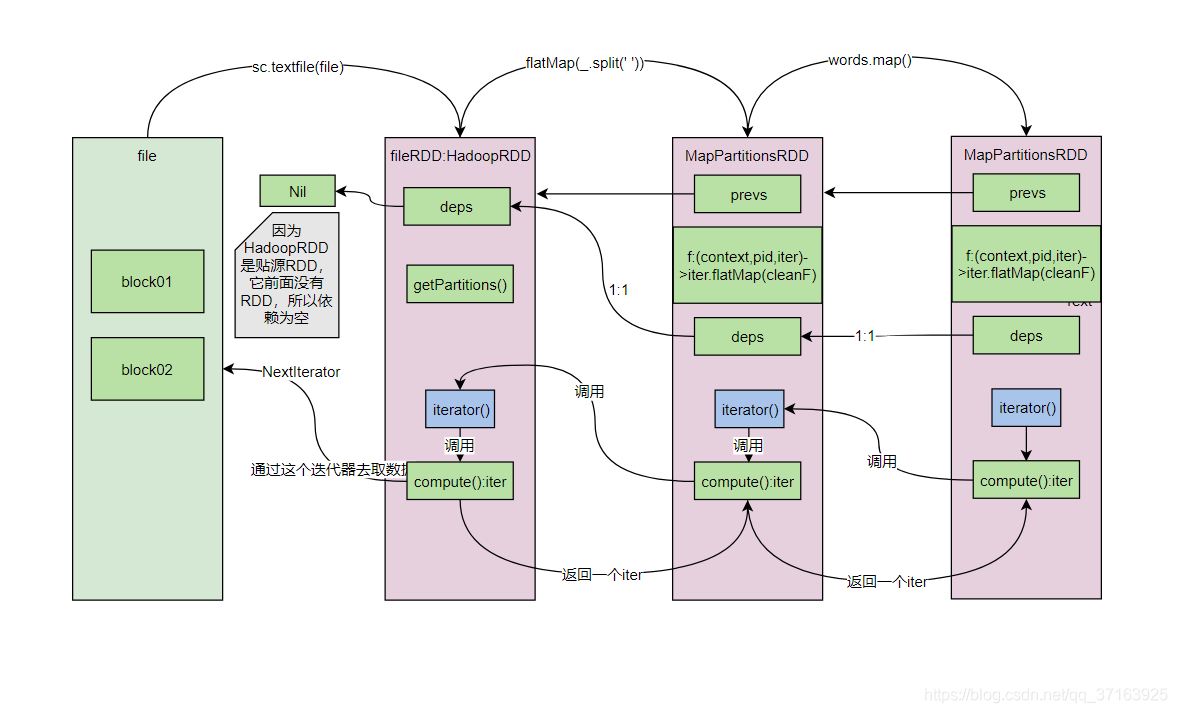
下面进入下一行val res: RDD[(String, Int)] = pairWord.reduceByKey( (x:Int,y:Int)=>{x+y} ),reduceBykey会触发shuffle,因为之前的RDD只关心自己处理的一条记录,不用管其他的记录,而reduceBykey要处理的是key相同的一组记录,所以需要把相同的key的记录发送到相同的reducer中,我们进入reduceBykey()。
/**
* Merge the values for each key using an associative and commutative reduce function. This will
* also perform the merging locally on each mapper before sending results to a reducer, similarly
* to a "combiner" in MapReduce. Output will be hash-partitioned with the existing partitioner/
* parallelism level.
*/
def reduceByKey(func: (V, V) => V): RDD[(K, V)] = self.withScope {
reduceByKey(defaultPartitioner(self), func)
}
这个方法又调用了一次它自己,并且调用时传了2个参数进去,第一个是defaultPartitioner(self),这个defaultPartitioner就是HashPartitioner(又和mapredcue一样)。我们进入这个reduceBykey(defaultPartitioner(self), func)方法。
/**
* Merge the values for each key using an associative and commutative reduce function. This will
* also perform the merging locally on each mapper before sending results to a reducer, similarly
* to a "combiner" in MapReduce.
*/
def reduceByKey(partitioner: Partitioner, func: (V, V) => V): RDD[(K, V)] = self.withScope {
combineByKeyWithClassTag[V]((v: V) => v, func, func, partitioner)
}
这里它调用了combineByKeyWithClassTag[V]((v: V) => v, func, func, partitioner)方法,并传入了4个参数,第一个参数应该匿名函数,第二个参数和第三个参数都是用户定义的function。第四个参数是partition。我们进入这个方法。
def combineByKeyWithClassTag[C](
createCombiner: V => C,
mergeValue: (C, V) => C,
mergeCombiners: (C, C) => C,
partitioner: Partitioner,
mapSideCombine: Boolean = true,
serializer: Serializer = null)(implicit ct: ClassTag[C]): RDD[(K, C)] = self.withScope {
require(mergeCombiners != null, "mergeCombiners must be defined") // required as of Spark 0.9.0
if (keyClass.isArray) {
if (mapSideCombine) {
throw new SparkException("Cannot use map-side combining with array keys.")
}
if (partitioner.isInstanceOf[HashPartitioner]) {
throw new SparkException("HashPartitioner cannot partition array keys.")
}
}
val aggregator = new Aggregator[K, V, C](
self.context.clean(createCombiner),
self.context.clean(mergeValue),
self.context.clean(mergeCombiners))
if (self.partitioner == Some(partitioner)) {
self.mapPartitions(iter => {
val context = TaskContext.get()
new InterruptibleIterator(context, aggregator.combineValuesByKey(iter, context))
}, preservesPartitioning = true)
} else {
new ShuffledRDD[K, V, C](self, partitioner)
.setSerializer(serializer)
.setAggregator(aggregator)
.setMapSideCombine(mapSideCombine)
}
}
了解combinerbykey()方法的同学应该对这个方法很熟悉,combinerbykey()要经历三个阶段,第一个阶段是第一条记录的处理,第二个阶段是第二条及之后的记录的处理,第三个阶段是合并之前溢写出来多个小文件的处理。这也是combinerbykey()要传入三个函数的原因。这个函数将三个函数封装进一个aggregator里面,在函数的最后,会 new 一个ShuffledRDD,并调用setSerializer(),setAggregator(),setMapSideCombine()三个方法,第一个方法是序列化,第二个方法是聚合操作,即执行传入的三个方法,第三个是设置map端聚合。我们先来看一下ShuffledRDD。
class ShuffledRDD[K: ClassTag, V: ClassTag, C: ClassTag](
@transient var prev: RDD[_ <: Product2[K, V]],
part: Partitioner)
extends RDD[(K, C)](prev.context, Nil) {
注意,这里prev加了一个@transient注解,@transient的意思就是序列化时忽略这个变量。这意味着shuffledRDD序列化时,无法将其前面的RDD也序列化,后面的RDD也就无法获取shuffledRDD之前的RDD的引用了,所以shuffledRDD需要从前一个RDD的输出中拉取数据,而不是通过迭代器从源头开始计算。
再看构造shuffledRDD的过程中传入的参数,deps参数是Nil,也就是说它的依赖是空,不依赖前一个RDD了。我们更新一下图。
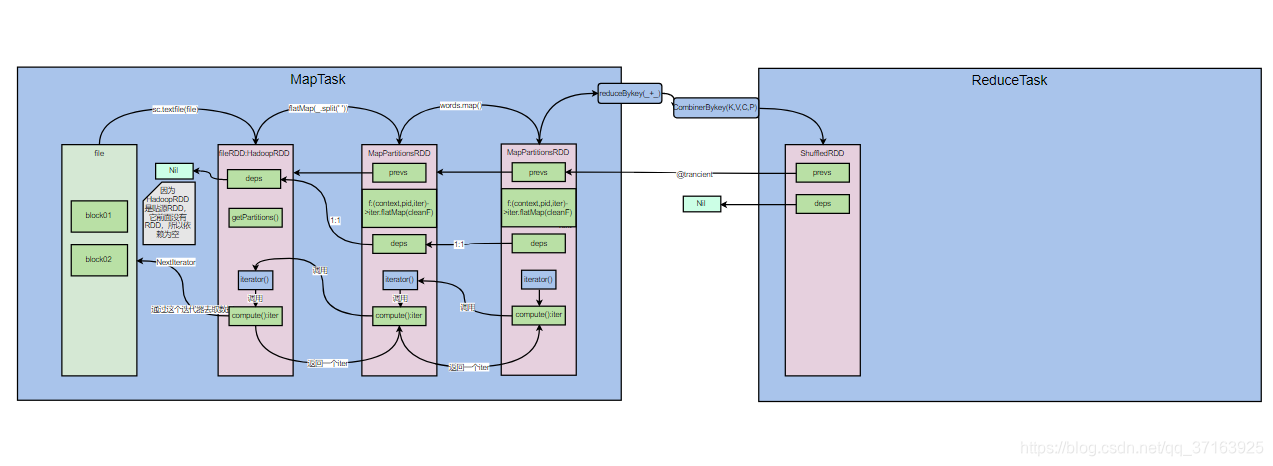
但是shuffledRDD有一个getDependencies()方法来获取依赖。我们看一下这个方法。
override def getDependencies: Seq[Dependency[_]] = {
val serializer = userSpecifiedSerializer.getOrElse {
val serializerManager = SparkEnv.get.serializerManager
if (mapSideCombine) {
serializerManager.getSerializer(implicitly[ClassTag[K]], implicitly[ClassTag[C]])
} else {
serializerManager.getSerializer(implicitly[ClassTag[K]], implicitly[ClassTag[V]])
}
}
List(new ShuffleDependency(prev, part, serializer, keyOrdering, aggregator, mapSideCombine))
}
这个方法最终会返回一个List,List里面new 了一个ShuffleDependency(),第一个参数是前一个RDD,第二个参数是分区器,第三个是序列化器,第四个是key是否排序,第五个是聚合器,聚合器存的就是combinerBykey()方法中的三个聚合函数,第六个参数是map端是否聚合。这些参数共同构成了一个ShuffleDependency()。
此外,shuffledRDD也有一个compute()方法,我们看一下这个方法。
override def compute(split: Partition, context: TaskContext): Iterator[(K, C)] = {
val dep = dependencies.head.asInstanceOf[ShuffleDependency[K, V, C]]
SparkEnv.get.shuffleManager.getReader(dep.shuffleHandle, split.index, split.index + 1, context)
.read()
.asInstanceOf[Iterator[(K, C)]]
}
这个compute()同样会被RDD的iterator()方法调用,那么它被调用时会发生哪些事呢?它会拿到上一个RDD的依赖,然后通过sparkEnv来获取ShuffleManager,最终返回一个Reader,这个reader调用read()方法返回一个迭代器Iterator。这里我们发现,它没有调用父类的迭代器,因为前面是一个独立的计算过程,它会将自己的结果输出到一个文件中,shuffledRDD只是从这个文件中拉取上一个计算过程中输出的结果,而不用去重新跑一遍。我们更新一下图。
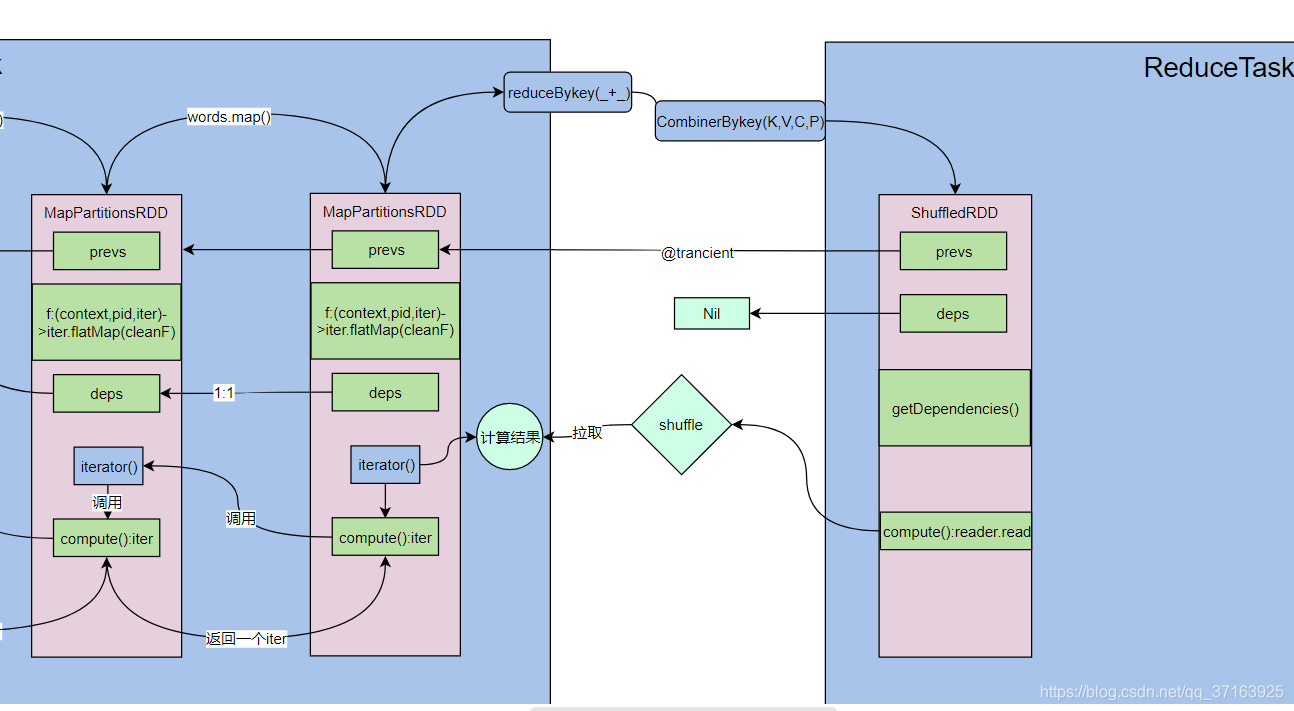
为了更直观的了解spark的运行过程,我们在reduceTask端再加一个map()操作,这个map方法和之前的一样,从shuffledRDD中获取数据。我们更新一下图。
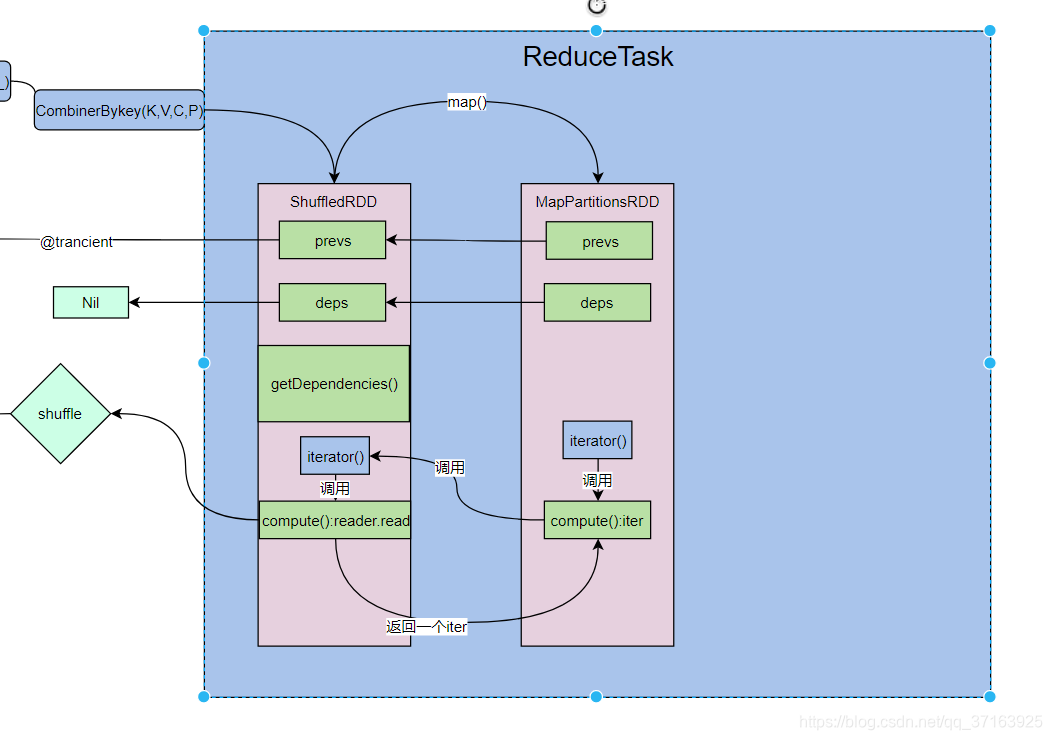
这时我们在执行foreach(println)。进入foreach()方法。
/**
* Applies a function f to all elements of this RDD.
*/
def foreach(f: T => Unit): Unit = withScope {
val cleanF = sc.clean(f)
sc.runJob(this, (iter: Iterator[T]) => iter.foreach(cleanF))
}
foreach()最终又调用了sparkcontext.runJob(),我们更新一下图。
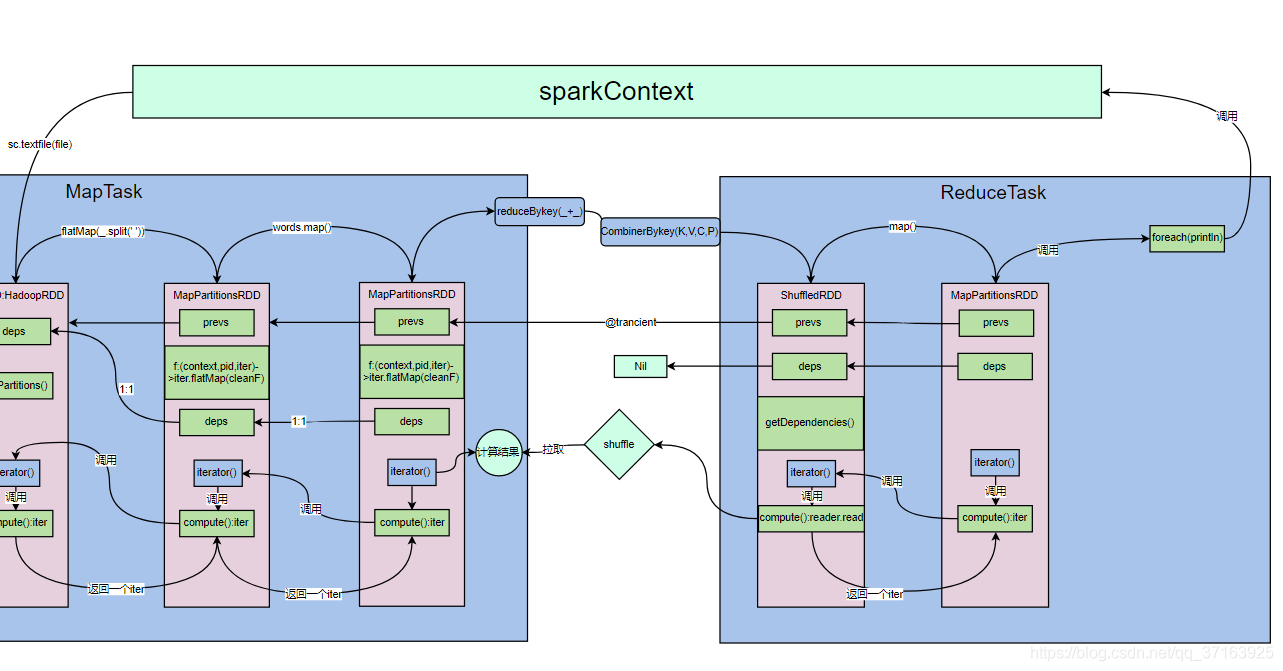
抱歉前面作图不严谨,应该是sparkcontext调用textFile()方法。但是并不影响我们理解执行过程,至于任务的调度,stage的切分,内存的管理等工作不在本文讨论。
下面我们对RDD做一个分类。
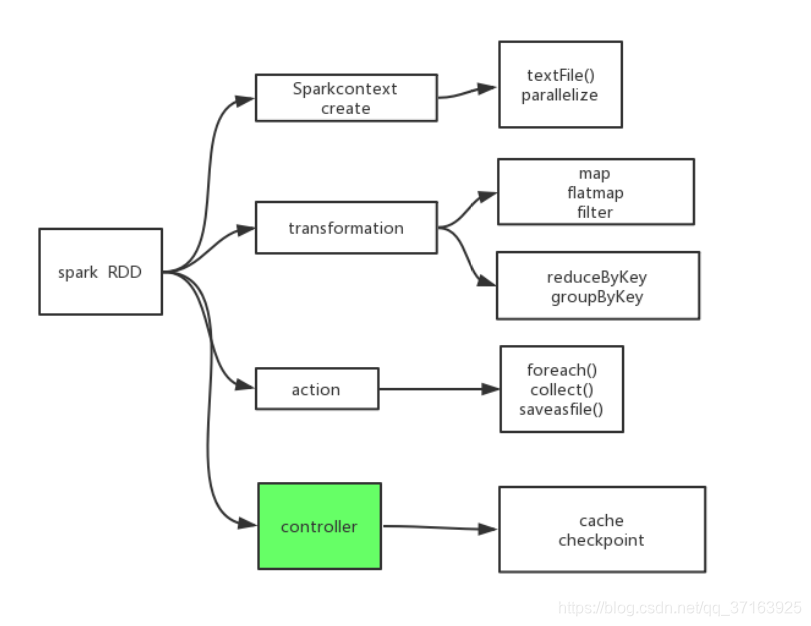
注:create算子一定能从上下文中得到一个算子;transformation会对RDD进行转换,使之成为一个新的算子,transformation算子中,map(),flatMap(),filter()不会触发shuffle,而reducBykey(),groupBykey()会触发shuffle;执行算子会触发runJob();控制算子可以让RDD缓存数据到内存里,提高后续算子重复利用的效率。

















 1173
1173

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









