







 本文从基础的蛮力算法出发,详细解析KMP算法,包括其原理、next数组的意义和计算,以及KMP的两种实现方法。通过理解KMP算法如何避免不必要的回溯,提高字符串匹配效率。同时,文章探讨了KMP算法的时间复杂度,并提及了针对KMP的两种改进算法,BC和BM,适用于大规模字符串匹配场景。
本文从基础的蛮力算法出发,详细解析KMP算法,包括其原理、next数组的意义和计算,以及KMP的两种实现方法。通过理解KMP算法如何避免不必要的回溯,提高字符串匹配效率。同时,文章探讨了KMP算法的时间复杂度,并提及了针对KMP的两种改进算法,BC和BM,适用于大规模字符串匹配场景。
1.前言(废话。)
初次接触KMP应该是在16年11月。当时做学校OJ的时候遇到一个KMP板子题,但是当时只写出来了O(mn)的算法,意料之中TLE。遂搜题解,但是当时水平很低(非OI出身),看的博客都没有让我具体理解next数组的具体含义。
再次接触KMP是在数据结构课上。但是老师匆匆带过...呃...然后自己匆匆扫了眼课本。。。
直到之前哪一天做青岛网络赛,遇到一个AC自动机的题。虽然后来A了,但是想起来自己连单模匹配都没看。遂回头看next数组,一看就看懂了。还是年轻,太浮躁了。面临失学和失业的惨痛现实才觉醒...
希望此文能帮助你学会KMP。我将从蛮力算法开始,到详解kmp,再到kmp的改进算法。
另外,明天icpc南京网络赛,祝各位acmer顺利。也祝我顺利。
2.蛮力算法
2.1蛮力算法原理及过程
蛮力算法很容易想到。但是理清思路有助于我们后面对KMP以及BM算法的理解。
我们要找模式串在目标串中的位置,但是我们没有任何信息来确定到底模式串在目标串是从哪开始的,那么我们只要枚举目标串的每一个位置,从这个位置开始匹配目标串,如果可以匹配完模式串的最后一个,就完全ok,找到了。如果中途失配,那么目标串匹配位置向后走一个,继续匹配。很简单的思路。
先上一张图(截于邓公的算法训练营第四周)以此来讲解一下蛮力匹配算法。
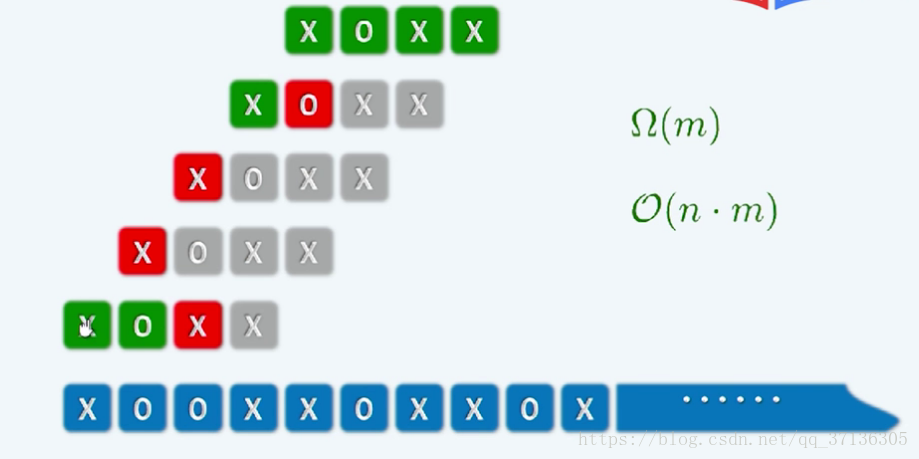
我们的模式串是XOXX,目标串是底下蓝色的XOOXOXXOX.
图上很好理解。绿色表示成功匹配的字符,红色表示失配字符,灰色表示失配后被跳过的字符(没人会傻到失配了还继续比较完吧)。具体过程不再赘述。
2.2蛮力算法的时空复杂度
空间复杂度很好理解,是m+n,只需要存储模式串和目标串即可。
时间复杂度的话,参考上图。对于每一个目标串的位置我们是要枚举的,在枚举的过程中,我们却不一定每次匹配m次,因为失配后我们会跳过灰色位置的匹配。具体跳过多少,我们不好说。但是考虑一种情况,也就是我们失配的字符是最后一个的话,那么我们要比较n*m次。因为枚举了n次目标串位置,对于每个目标串位置枚举了m次。

2.3蛮力算法的两种实现方法。
实现方法虽然名义上是两种,实际上是一样的。但是分开两种写有助于我们理解后面的两种优化。其中实现方法1对应KMP算法,实现方法2对应PM算法。
2.3.1实现方法1(失配后,目标串的起始匹配位置回退)
//Brute-Force Version1
int match1(char *P,char *T){
int n = strlen(T),i = 0;
int m = strlen(P),j = 0;
while(i < n && j < m){
if(T[i] == P[j]){i++;j++;}//匹配,ij都往后走
else{i -= j-1;j = 0;}//不匹配,i回退到原开始位置的下一个位置
}
return i - j;//这里有多种返回方式
}2.3.2实现方法2(枚举目标串每次匹配的位置)
//Brute_Force Version2
int match2(char *P,char *T){
int n = strlen(T),i = 0;
int m = strlen(P),j = 0;
for(i = 0;i < n-m+1;i++){//在目标串枚举模式串匹配的起始位置
for(j = 0;j < m;j++)//枚举模式串的每一个字符
if(T[i+j] != P[j]) break;//失配,转下一匹配位置
if(m == j) break;//是完美匹配
}
return i;//这里有多种返回方式
}3.KMP算法
Knuth-Morris-Pratt 字符串查找算法,简称为 “KMP算法”,常用于在一个文本串S内查找一个模式串P 的出现位置,这个算法由Donald Knuth、Vaughan Pratt、James H. Morris三人于1977年联合发表,故取这3人的姓氏命名此算法。
3.1从蛮力算法的过渡...
我们已经了解蛮力算法了,可以看出,每次匹配的时候我们都做了很多工作,但是一旦失配,我们毫不留情全部丢弃这些工作但是注意,当串比较长的时候如果能合理利用前面的工作,我们会把时间降低一个可观的数量。
回头看2.3.1的蛮力算法,如果我们失配后,不是i回退到原位置的下一个位置,而是j从另一个可能位置继续与当前的i进行匹配的话,这样每次匹配成功,i的值都是增加的,不再回退。效率也将大大提高。那么,j从哪个位置开始呢?我们又如何计算这个位置呢?
3.2KMP的一般流程及next数组的意义
其实KMP算法的精髓就是上一段话中加黑下划线的字体。我们不选择回退i,而是回退j到另一个可能位置。
这里我先给出KMP算法的一般流程,别急,相信我,马上就会柳暗花明的。
假设现在目标串S匹配到i位置,模式串P匹配到j位置
if(j = -1或者当前字符匹配成功)i++,j++;
if(j!= -1 并且当前字符未匹配成功)则令i不变,j = next【j】,也就是失配时,模式串相对于文本串回退了j - next【j】个位置。
以上就是kmp的一般化步骤。现在我们来思考next数组到底是存了啥,可以让失配的时候模式串按照next数组的值回退。
如果你不太明白的话,我们来模拟一下kmp的过程。如下图,蓝色的是目标串。现在我们匹配到了浅蓝色的X字符。
接下来我们看第二条(先不要看P区间)。第二条是当我们匹配到了Y字符的时候。绿色部分表示匹配。但是我们现在发现Y字符是失配的。于是我们执行 j = next[j] 这条语句,现在我们的模式串与i相比较的那个位置,从j位置回退到了t位置,继续比较。(当然,我们发现接下来的Z字符和X字符不相同,模式串还是要继续回退的。)

既然明白了kmp的过程,那么我们结合图来看,很容易发现(显然),当图上的三个P区间是一样的时候,这个流程是合理的。于是,next数组的含义也就出来了。他表示的就是当前下标之前的字符串前缀后缀相等的那部分最长的长度。
数学公式表达的话,就是
。其中,t就是相等的前缀后缀得长度
当然,我们定义,。我暂时不解释为什么赋值为-1.
举个例子,下图中绿色表示前后缀最大相同部分。
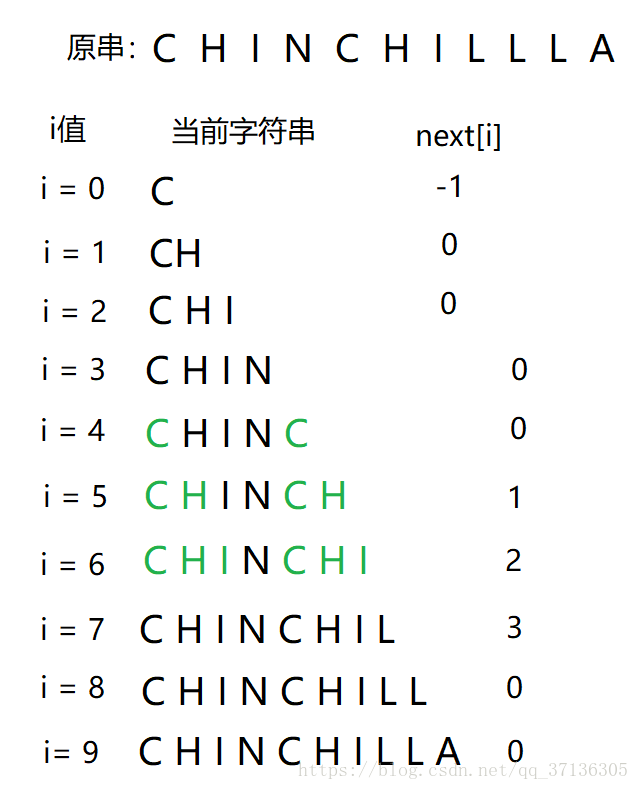
在我们匹配时,假设我们的目标串是CHINCHIXXXXXX...,我们看下图。当L不匹配的时候,我们模式串的下标是7,我们看i = 7事,发现CHINCHI的前后缀最长公共部分是3,于是可以跳到下标为3的位置。发现N和C不匹配,于是看CHI的前后缀最长公共部分是0,就从下标0开始接着匹配。
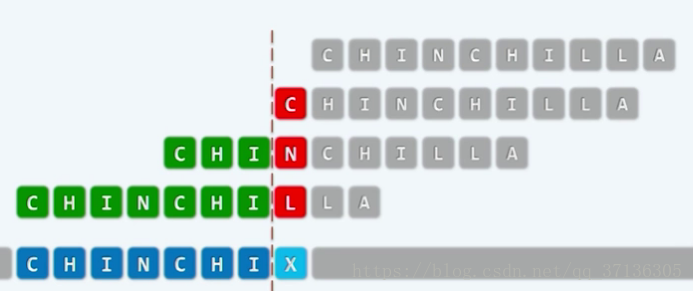
那么,在我们当前字符失配时,next数组就在告诉我们下一步模式串应该往前移动多少,然后接着匹配(然后才能不浪费之前做的功)。
至此,整个KMP的一般流程应该理解了。加上next数组的话应该就是以下两步了。
- 求模式串的next数组。
- 根据模式串的next数组来匹配目标串。
3.3next数组以及kmp的具体实现
根据上面的流程,我们首先要计算next数组。很明显,next数组是可以递推出来的。那么,怎么递推呢?
假设我们已经知道了next[j],要求next[j+1],怎么求呢?假如P是模式串。那么的意义,就是第j+1个字符之前的字符串的最长公共前缀后缀中后缀的后一个字符(有点绕,如果有些不适,自己好好想想,很好想的呢)。这时,如果
和
相等,也就是第j+1个字符之前的字符串的最长公共前缀后缀中后缀的的后一个字符和第j+1个字符之前的字符串的最长公共前缀后缀中前缀的的后一个字符相等,那么有
,否则让P[i]和P[next[next[j]]]比较...有点绕,具体看下图解释。(虽然我很懒但是我还是打算举个例子qaq有人看吗qaq应该没人看吧qaq我自娱自乐就当记录成长好了。)
蓝色为目标串。当前计算到第j个字符(计算完next[j])。
首先我们要明确,蓝色的X是P[j],绿色的X是P[next[j]即公共前缀的后一个字符(和
相等),红色的Y也是P[next[j](失配) 黄色的?是P[next[next[j]]]。
当成功配对(和
相等)时,相当于公共前后缀总长度+1.
当失配时,我们就要像KMP一样,把共同前缀的长度缩小到上一个可能位置继续比较。也就是.

现在,可以思考一下为什么next[0]的值为-1了。模拟一下就明白了。
板子参考了kuangbin的acm模板,kmp部分稍有改进。可以好好思考。
/*
* next[] 的含义:x[i-next[i]...i-1]=x[0...next[i]-1]
* next[i] 为满足 x[i-z...i-1]=x[0...z-1] 的最大 z 值(就是 x 的自身匹配)
*/
int next[10010];
void kmp_pre(char x[],int m,int next[]){
int i,j;
j=next[0]=−1;
i=0;
while(i<m){
while(−1!=j && x[i]!=x[j])j=next[j];
next[++i]=++j;
}
}
/*
* 返回 x 在 y 中出现的次数,可以重叠
*/
int KMP_Count(char x[],int m,char y[],int n) {//x 是模式串,y 是主串
int i, j;
int ans = 0;
kmp_pre(x, m, next);
i = j = 0;
while (i < n) {
while ( j != -1 && y[i] != x[j])j = next[j];
i++;
j++;
if (j >= m) {
ans++;
j = next[j];
}
}
return ans;
}3.4 为什么KMP的时间复杂度是线性的?
接下来我们考虑他的复杂度。假如我们一直失配,那么目标串会一直左移对吧,那么考虑一个极端情况。假如一直失配,会不会一直左移呢?那么在n个位置,会不会每次都回退m次呢?那变成m+n的话我们就白干活啦。
不会的。我们用一个非常简单的思路来证明。
假如说我现在有一个 i*2 - j,那么,如果走完每一步我这个表达式的值都在递增,那么可以说明实现性的吧,因为这个表达式的值不会超过2*n!(ij意义参考以上)
假如匹配成功,S[i] = P[j],那么i++,j++,表达式的值递增了1。
假如失配,S[i] != P[j],那么j = next[j],j的值减小,整个表达式的值增加1以上。
得证。
3.5改进一
来看这么一个串S:0 0 0 1 0 0 0 0 1 P:0 0 0 0 1
那么会匹配几次呢
P: 0 0 0 0 1
next数组:-1 0 1 2 3
匹配步骤:0 0 0 1 0 0 0 0 1
P:0 0 0 0
next:-1 0 1 2
P: 0 0 0
next: -1 0 1
P: 0 0
next: -1 0
P: 0
next: -1
P: 0 0 0 0 1
很容易发现我们做了很多无用功。因为我们当前位置是1的时候,模式串从0进行回退之后还是0.但是很容易想到,回退之后的新字符还是相等的话是不太好的,因为这样是肯定匹配不成功的。说到这,优化的思路就很简单了。看代码不解释了。
/*
* kmpNext[i] 的意思:next'[i]=next[next[...[next[i]]]](直到 next'[i]<0 或者 x[next'[i]]!=x[i])
* 这样的预处理可以快一些
*/
void preKMP(char x[],int m,int kmpNext[]){
int i,j;
j=kmpNext[0]=−1;
i=0;
while(i<m){
while(−1!=j && x[i]!=x[j])j=kmpNext[j];
if(x[++i]==x[++j])kmpNext[i]=kmpNext[j];
else kmpNext[i]=j;
}
}3.6改进二(BC,BM)
这一部分的话暂时不更了,因为叙述这个策略相对复杂一点,时间上没有优化太多,并且我记己学会之后用的次数也不多。如果有人想看的话再更qaq
但是时间不稳定的喂。。。BC一般是O(n/m),但是最差可以到O(n*m).BM复杂度是O(n/m),其实是BC用GS优化。。。但是这个策略相对复杂(我懒qaq)
总结:
一般情况(没有刻意设计过的情况),蛮力算法就够了(自己算算概率啊喂)复杂度是O(n)到O(n*m)
小规模字符串 用KMP,时间稳定在线性。
很大规模字符串 用BC,因为越长,匹配失败的概率越大,就会越早的结束算法。
至于BC + GS嗯。。。。。

















 7971
7971

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









