








1、引言
主要思想
微小人脸的超分辨率与特征点定位是高度相关的任务。一方面,利用高分辨率的人脸可以获得更高的精度特征点的定位。另一方面,面部SR将受益于对面部属性(如特征点)的先验知识。(人脸的超分和人脸特征点的定位相互促进)。因此,我们提出了一种联合对齐和SR网络来同时检测人脸关键点和超分辨微小人脸。更具体地说,通过利用互补信息,应用共享深度编码器来提取这两个任务的特征。为了利用分级编码器的代表能力,将共享特征提取模块的中间层融合以形成有效的特征表示。融合后的特征被输入到特定任务的模块,以同时地检测人脸特征点和超分辨人脸图像。
本文贡献
- 提出了一个对微小人脸进行SR和特征点检测的网络(称为JASRNet)。
第一个联合学习特征点定位和SR的多任务模型。与现有的两步方法不同,我们利用两项任务的互补信息。这允许在LR空间中做出更准确的特征点预测,并改进LR到HR的重构。 - 在最大化程度地从LR人脸捕获信息时用到了新的深度特征提取和融合模块,而它们是在编码器中间层进行的,以便利用深度层次机制。
- 我们在SR和微小人脸(即16x16)特征点定位方面取得了很大的进步. 除此之外,我们的JASRNet在低分辨率人脸特征点定位产生的结果可与现存的评估HR人脸方法以较高低。并且我们提出的恢复HR人脸的方法比现有的方法有更锐利的边缘和形状。
背景:同时解决对齐和超分辨率任务时从微小的面部图像中获取最大的信息量。
方法:提出了一种联合对齐和SR网络来同时检测人脸关键点和超分辨微小人脸。利用互补信息,应用共享深度编码器来提取这两个任务的特征。
结论:提出的模型在关键点定位和人脸SR方面均明显优于最新技术。
2、网络结构
微小人脸的超分辨率与特征点定位是高度相关的任务。但是之前的工作要么使用SR来帮助对齐小脸,要么反之亦然,并不是两者兼而有之。我们认为,当只使用一个任务来帮助另一个任务时,从LR图像中提取的信息量并不是最大化的。因此,我们提出了一个联合对齐和超分辨率网络(JASRNet)来同时建模超分辨率和定位微小人脸的地标,这两个任务的信息都能提高另一个任务的性能。
如图所示,JASRNet由四部分组成:(1)一个共享的浅层编码器模块,用于提取两个任务的浅层和共享特征;(2)深度特征提取和融合,用于获得更好的特征表示;(3-4)特定于任务的模块,分别用于超分辨率和人脸对齐。
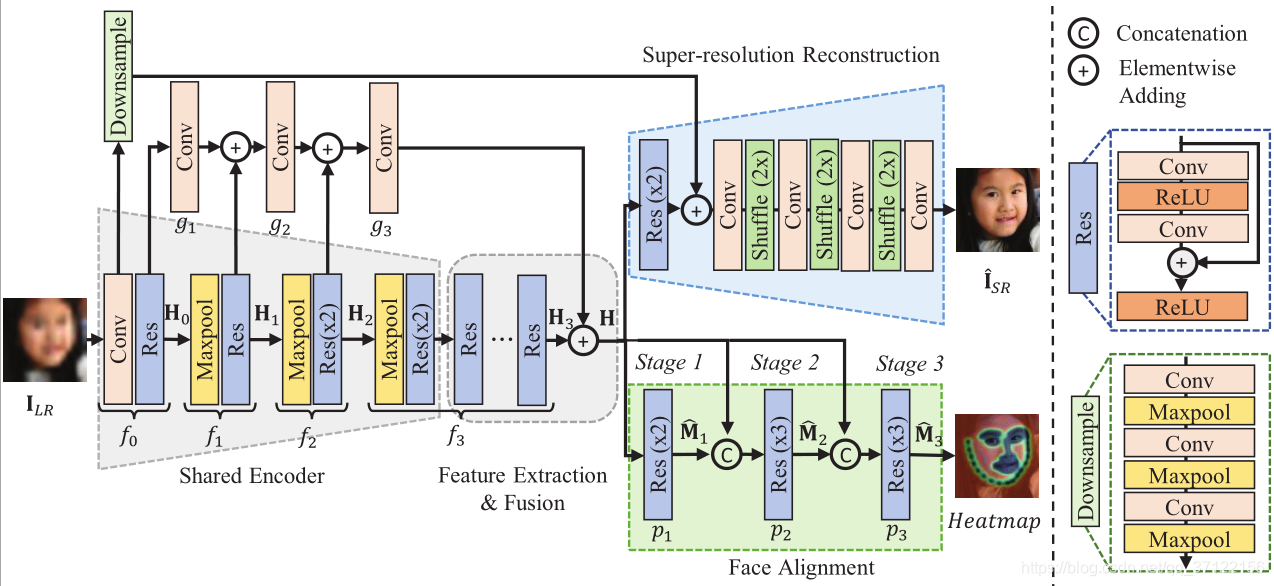
建议的JASRNet的体系结构。共享编码模块(Shared Encoder)是为双任务提取浅层特征和共享特征。采用深度特征提取和融合模块(The deep feature extraction and fusion)是为了获得更好的特征表示。super-resolution and face alignment模块是超分辨率重构模块和人脸对齐模块
原始LR图片被送入给共享的编码器,然后编码器将数据输入到特征提取模块,为这两个任务提取特征。接着,融合的特征被输入到两个特定任务的模块。同时生成超分辨率图片(I(i)HR)和特征点估计的概率图(M(i))。
3、损失函数
在人脸对齐方面,SR模块恢复了分辨率较高的图像,从而帮助模型检测到更准确的特征点。对齐模块定位脸部的边缘和结构,迫使更多的关注高频内容(即边缘)。因此这两种任务,即人脸SR和特征点定位,都适合相互受益。这项工作的目的是获得最大的信息量,而这些信息量是从低分斌率的人脸中提取的。信息的获得通过结合每个任务的损失函数来实现的。
对于SR任务,L1损失是最小的,因为它能提供比L2更好的收敛性。在对齐任务中,使用L2热图损失。加在一起,JASRNet的损失函数可以表示为
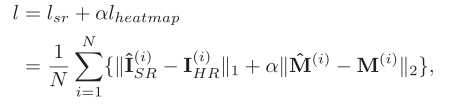
4、实验结果

视觉效果。不同超分辨率方法的比较。

定量比较。300W和HELEN数据集上的PSNR/SSIM比较

消融研究。突出特征融合,联合训练。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









