







 超级会员免费看
超级会员免费看
 本文详细介绍了如何将SparkSQL与Hive进行整合,包括整合的步骤、配置文件的设置,以及如何在SparkSQL中使用Hive的元数据库、SQL语法和自定义函数。通过整合,可以在SparkSQL中直接查询Hive的表,实现数据的读取和操作。
本文详细介绍了如何将SparkSQL与Hive进行整合,包括整合的步骤、配置文件的设置,以及如何在SparkSQL中使用Hive的元数据库、SQL语法和自定义函数。通过整合,可以在SparkSQL中直接查询Hive的表,实现数据的读取和操作。
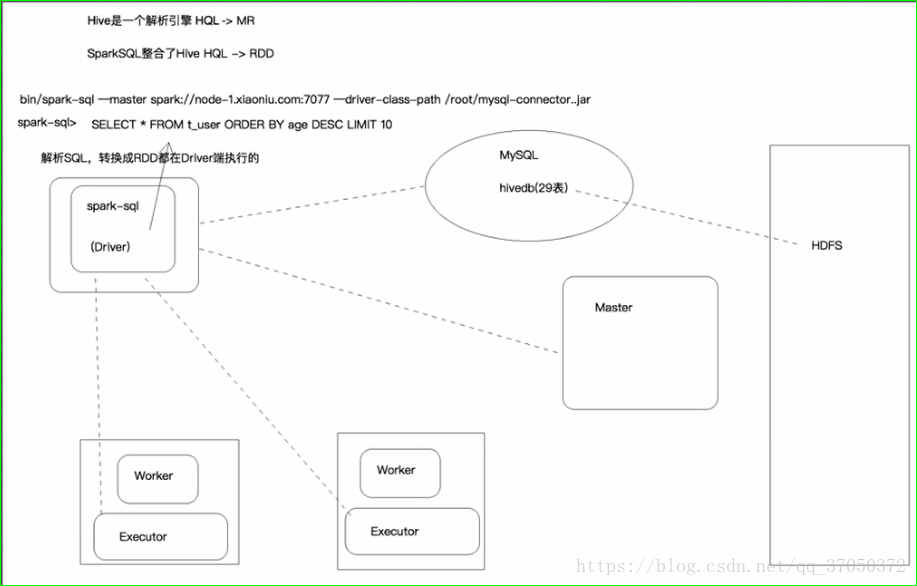
我们知道sparkSQL跟hive是兼容的,他支持hive的元数据库,sql语法,多种类型的UDF,
而且还支持hive的序列化和反序列化方式,意思就是hive写的自定义函数,spark拿过来就能用。

最重要的就是MetaStore元数据库,以后一旦我们使用hive的MetaStore,那么他以前建的表我们就可以使用了。
那么我们写的SQL就可以直接从hive的仓库中查询数据了。
所谓hive的仓库其实就是一个元数据库和hdfs
元数据库中指定了有哪些表,表中有哪些字段。每个字段叫什么名字,分别是什么类型。还有这张表对应的存放在hdfs的哪个目录下。以后我们执行sparksql的时候就可以根据元数据信息到hdfs中找对应的数据了。
元数据库中存放的是描述信息,hdfs中存放的是真正需要计算的信息。
接下来我们来整合hive,其实整合hive就是整合hive的元数据

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 382
382

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











