




 本文深入探讨了Python中的编码问题,特别是Python 2与Python 3之间的差异。解释了ASCII、Unicode、UTF-8等编码概念,并提供了如何处理不同操作系统下文本编码问题的实际案例。
本文深入探讨了Python中的编码问题,特别是Python 2与Python 3之间的差异。解释了ASCII、Unicode、UTF-8等编码概念,并提供了如何处理不同操作系统下文本编码问题的实际案例。
引文
初学Python,其中的编码问题很是让人头疼
爬取的文字有时会出现乱码,在不同的操作系统会有区别
看了不少关于编码的文章,结合着自己的理解来总结一下
实验环境:Linux (ubuntu16.4)
名词解释:
- ASCII———–单字节编码系统,包含2^7=127个字符(首位为0)
- unicode——–是一个字符集,为每种语言的每个字符设定了统一并且唯一的二进制编码
- utf-8————对unicode的一种编码方式
- GB2312———GB2312-80(中国制定),在windows中的代码页(codepage)是936y页
- GBK————-GBK由微软制定,是GB2312-80的扩展,在现在的windows系统中仍使用代码页CP936(新)表示,向下兼容GB2312
- codepage——-字符内码列表,与unicode之间的映射表
- cp936———–(codepage)第936页—简体中文(GBK)
学习一门新的计算机语言,总要先问候一下世界~

来运行一下这个程序

语法错误:文件中存在非ASCII字符
在文件首部加一行代码
# -*- coding:utf-8 -*-
ps:'-*-'这些多余的字符没有任何意义,只是起到美观的作用第一行注释的作用是告诉Python解释器按照指定的编码方式(这里是utf-8)读取源代码,要跟文件本身的编码一直才不会出现乱码

☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆
后来发现linux上的默认Python解释器是Python2.7

python2和Python3在编码问题上区别还是很大滴
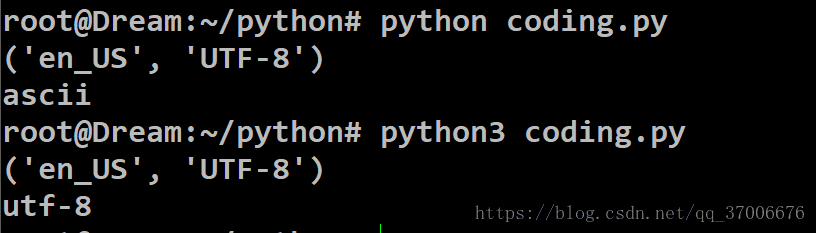
分别用python2和python3来运行以下代码
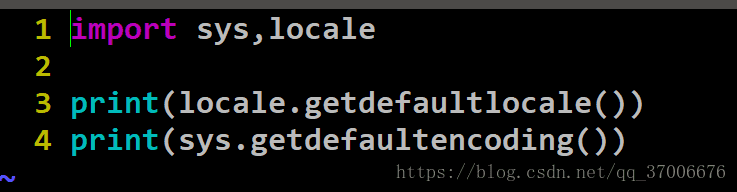
sys.getdefaultencoding() 用来获取系统默认编码
locale.getdefaultlocale() 用来获取本地编码系统默认编码和本地编码如下:
可以看出python2的系统默认编码为ASCII,Python3的默认编码为UTF-8
LInux中的本地编码为utf-8
(python2和Python3在字符串和编码问题上有很大区别,可以自行了解)
☆ ☆ ☆ ☆ ☆ ☆ ☆ ☆ ☆ ☆ ☆ ☆ ☆ ☆ ☆ ☆ ☆ ☆ ☆ ☆ ☆ ☆ ☆ ☆ ☆ ☆ ☆ ☆
Python3字符串和编码
python3中的str类型和bytes类型之间的转换
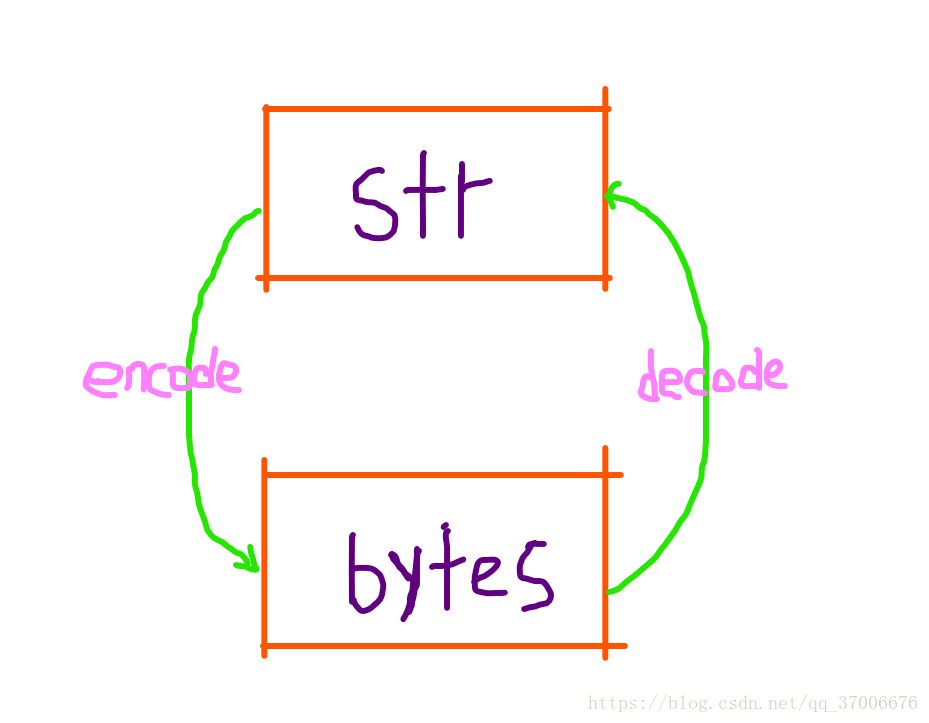
- “编码”是针对于文本 (str) 进行编码
- “解码”是针对于比特流 (bytes) 进行解码
demo

out

将bytes类型转化为str类型时,要知道bytes是以何种编码方式编码得到的,然后用此方式进行解码成str, 解码与编码方式不同会出错。
在计算机内存中,统一使用 Unicode 编码,当需要保存到硬盘或者需要
传输的时候,就转换为 UTF-8 编码。用记事本编辑的时候,从文件读取的 UTF-8 字符被转换为 Unicode 字符
到内存里,编辑完成后,保存的时候再把 Unicode 转换为 UTF-8 保存到
文件。
总结
Python 3最重要的新功能是文本和二进制数据之间更清晰的分离。文本始终为Unicode,由str类型表示,二进制数据由字节类型 (bytes) 表示。因为计算机只能处理数字,如果要处理文本,就必须先把文本转换为数字(比特流)才能处理
可以这样想:字符串是文本的抽象表示。字符串由字符组成,这些字符也是与任何特定二进制表示无关的抽象实体。我们不关心它们在内部如何表示以及在其中保存每个字符所需的字节数。我们只是在将字符串编码为字节时(例如,为了通过通信信道发送它们)或者从字节(对于另一个方向)解码字符串时开始关心这一点。
赋予编码和解码的参数是编码(或编解码器)。编码是一种表示二进制数据中的抽象字符的方法。有许多可能的编码。如上所示,UTF-8是一个。
(翻译自https://eli.thegreenplace.net/2012/01/30/the-bytesstr-dichotomy-in-python-3)
☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆
摘自《python3》—廖雪峰:
在计算机内存中,统一使用 Unicode 编码,当需要保存到硬盘或者需要传输的时候,就转换为 UTF-8 编码。
用记事本编辑的时候,从文件读取的 UTF-8 字符被转换为 Unicode 字符到内存里,编辑完成后,保存的时候再把 Unicode 转换为 UTF-8 保存到文件:浏览网页的时候,服务器会把动态生成的 Unicode 内容转换为 UTF-8 再传输到浏览器:所以你看到很多网页的源码上会有类似的信息,表示该网页正是用的 UTF-8 编码。

















 2692
2692

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









