







 本文深入探讨了目标检测在计算机视觉中的重要性及其挑战,包括非刚性目标、复杂背景和遮挡问题。文章梳理了目标检测的发展历程,从传统方法到深度学习的转变,介绍了CNN在提升检测精度中的作用。此外,还讨论了目标检测的算法流程、主要技术,如滑动窗口、特征提取、分类器和非极大值抑制,并展望了基于anchor-free设计和AutoML的未来研究趋势。同时,文章列举了评价指标和常用数据集,如Pascal VOC和COCO,强调了mAP作为主要评估标准的重要性。
本文深入探讨了目标检测在计算机视觉中的重要性及其挑战,包括非刚性目标、复杂背景和遮挡问题。文章梳理了目标检测的发展历程,从传统方法到深度学习的转变,介绍了CNN在提升检测精度中的作用。此外,还讨论了目标检测的算法流程、主要技术,如滑动窗口、特征提取、分类器和非极大值抑制,并展望了基于anchor-free设计和AutoML的未来研究趋势。同时,文章列举了评价指标和常用数据集,如Pascal VOC和COCO,强调了mAP作为主要评估标准的重要性。
计算机视觉领域研究的绝大多数问题均存在诸多不确定性因素,因为图像理解是成像的逆过程。成像是从三维向二维投影的过程,在此过程中不仅会丢失深度信息,而且光照、材料特性、朝向、距离等信息都反映成唯一的测量值,即灰度或色彩,而要从这唯一的测量值中恢复上述一个或几个特征参数是一个病态的过程。不仅如此,大气扰动、镜头因素、传感器噪声,以及量化噪声等的干扰都会造成成像失真,而这些干扰大多具有随机性。
图像或视频中的目标检测,意在基于目标的表观和轮廓区域等信息,准确地对其中感兴趣的目标进行定位,将目标的分类与定位合二为一。复杂环境下可靠的目标检测算法还有待进一步研究,原因在于:(1)一些目标是非刚性、多姿态、多角度的物体,如人体目标;(2)含有目标的图像背景一般都是复杂多变的;(3)目标很容易被其他目标或者物体遮挡;等等。因此,通过运用机器学习与模式识别的相关知识,使计算机能够自动、准确地检测目标,实现鲁棒、快速的目标自动提取和检测显得极为重要。
目标检测是计算机视觉和数字图像处理的一个热门方向,广泛应用于机器人导航、智能视频监控、工业检测、航空航天等诸多领域,通过计算机视觉减少对人力资本的消耗,具有重要的现实意义。因此,目标检测也就成为了近年来理论和应用的研究热点,它是图像处理和计算机视觉学科的重要分支,也是智能监控系统的核心部分,同时目标检测也是泛身份识别领域的一个基础性的算法,对后续的人脸识别、步态识别、人群计数、实例分割等任务起着至关重要的作用。
目标检测的发展历程
图像的目标检测(Object Detection)算法大体上可以分为基于传统手工特征的时期(2013年以前)以及基于深度学习的目标检测时期。从技术发展上来讲,目标检测的发展则经历了包围框回归、卷积神经网络的兴起、多参考窗口(anchors)、困难样本挖掘、多尺度多端口检测、特征融合等几个里程碑式的进步。如下图所示,为2019年5月发表的目标检测综述《Object Detection in 20 Years: A Survey》,它除了对目标检测从2001到2009年的里程碑式算法和start-of-art算法进行了总结,帮助我们建立一个完整的知识体系,还对算法流程各个技术模块的演进也进行了说明。
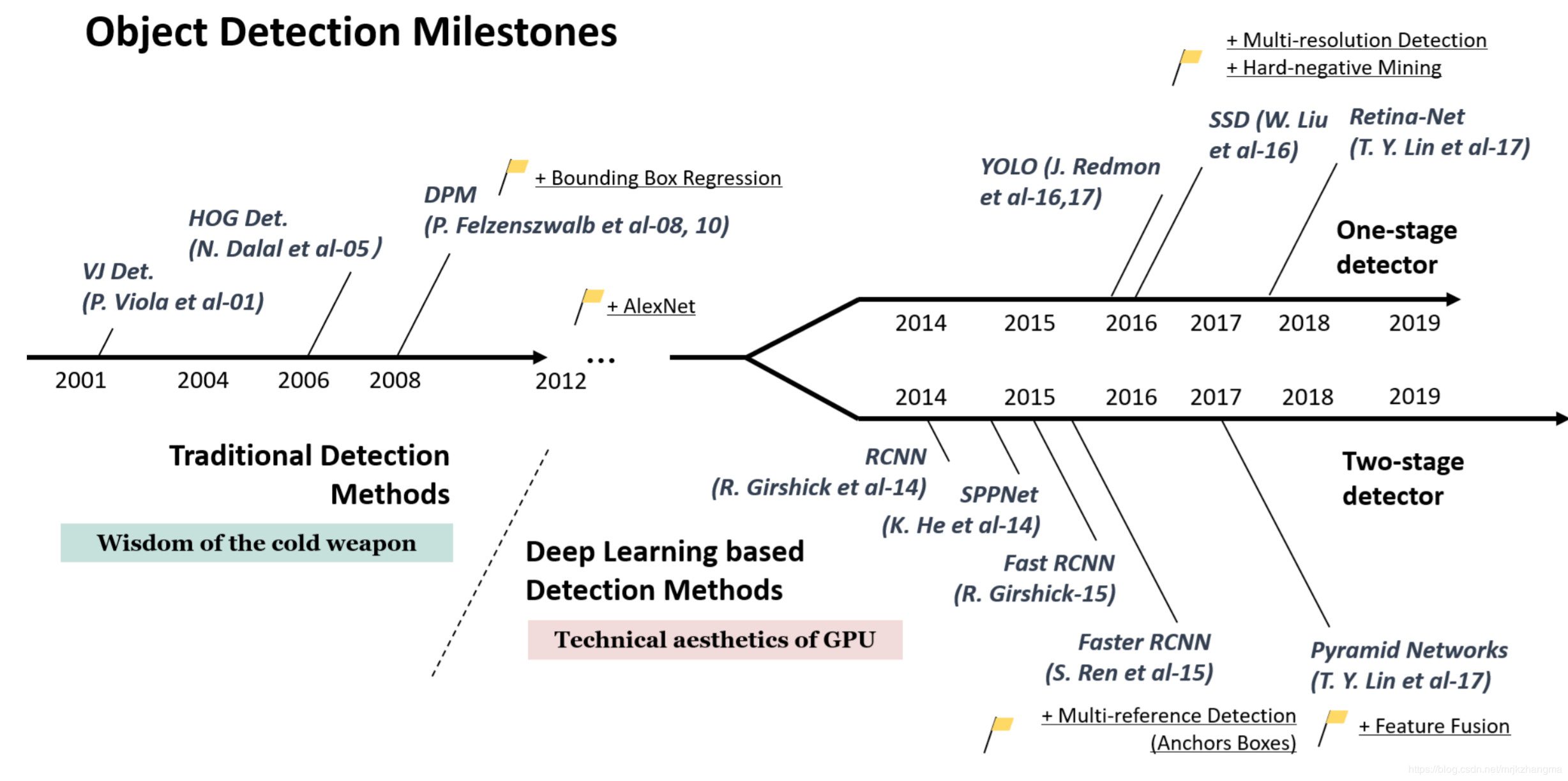
| 传统的里程碑方法 | 基于 CNN 的里程碑方法(two stage) | 基于 CNN 的里程碑方法(one stage) |
|---|---|---|
| VJ Detector | RCNN | You Only Look Once (YOLO) |
| HOG Detector | SPPNet | Single Shot MultiBox Detector (SSD) |
| Deformable Part-based Model (DPM) | Fast RCNN | RetinaNet |
| Faster RCNN | ||
| Feature Pyramid Networks (FPN) |
近年来,CNN在许多计算机视觉任务中发挥了核心作用,因此基于深度学习的检测器的精度在很大程度上取决于其特征提取网络。这些主干网络(backbone)如VGG和ResNet等对应于目标检测的发展阶段如下图所示,该图出自2019年8月发表的《Recent Advances in Deep Learning for Object Detection》。同样,自2012年以来,基于深卷积神经网络的目标检测研究具有重大里程碑意义,而图中红色箭头和绿色箭头分别代表着去年的两个研究趋势,一是基于anchor-free设计目标检测,二是基于AutoML技术的检测器,也是未来两个重要的研究方向。
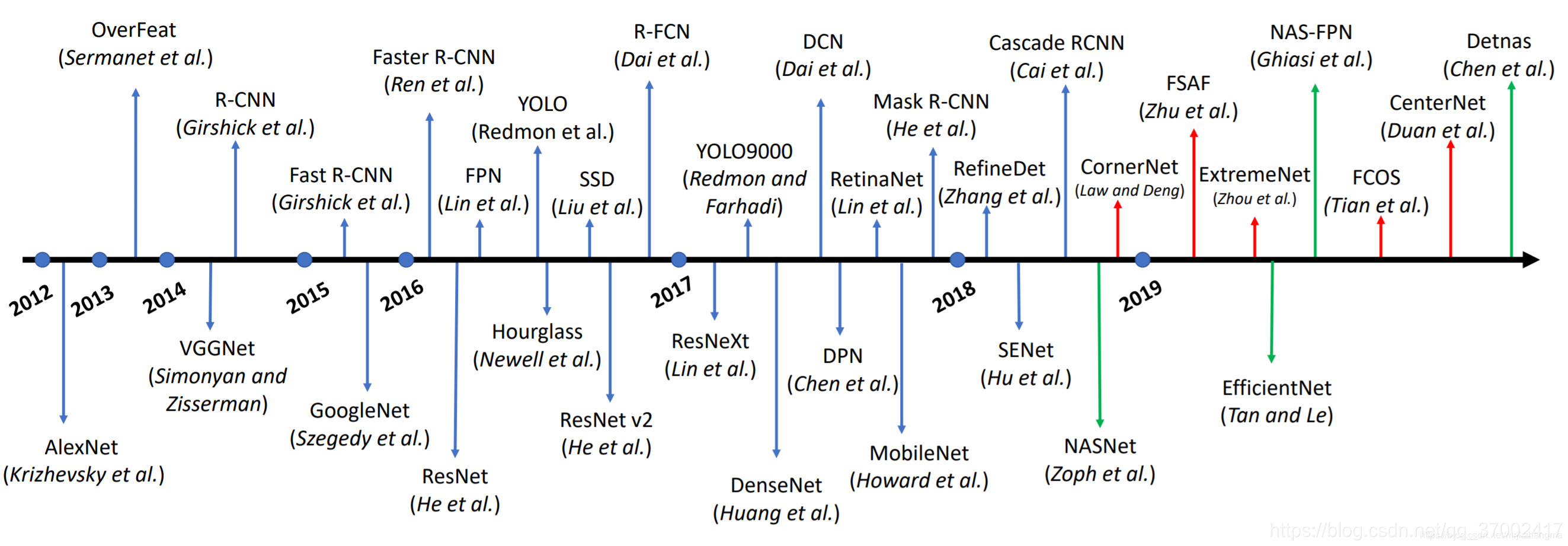
为了进一步整合各个网络模型的特点,我后续会将主要算法进行归纳。同时,github上面的开源仓库里面https://github.com/hoya012/deep_learning_object_detection,也有2020年最新更新的检测论文&#x
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









