






由于TRPO实现起来需要使用二阶近似和共轭梯度,比较复杂,Deepmind又在TRPO的基础上提出了实现较为简单的PPO算法。
TRPO
TRPO的优化目标为
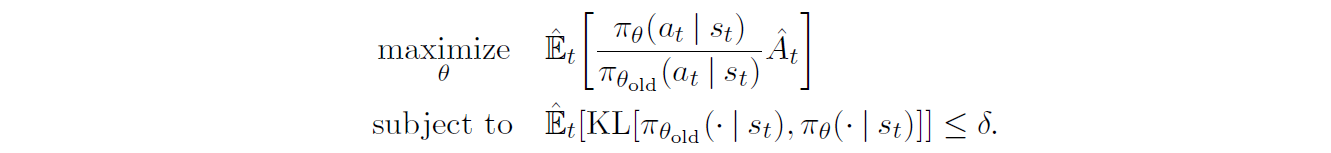
用惩罚项代替约束项后
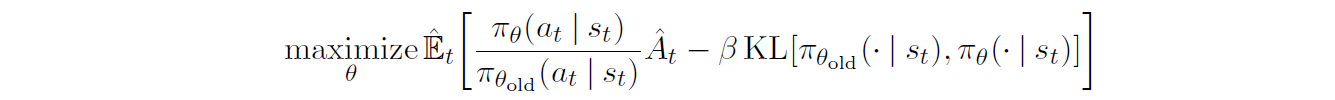
Adaptive KL Penalty Coefficient
PPO1为了避免TRPO中超参数
β
\beta
β的选择,采用自适应确定参数的方法
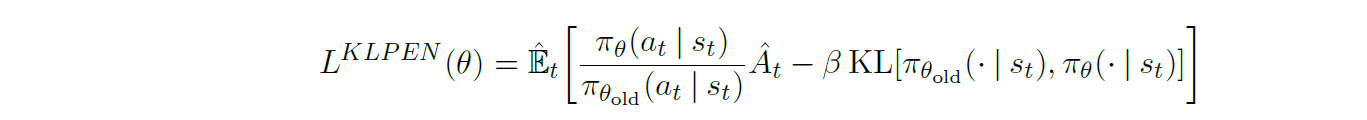
β
\beta
β由以下条件确定


Clipped Surrogate Objective
为了限制更新步长,原文还提出了PPO2,这是默认的PPO算法,因为PPO2的实验效果比PPO1更好。做法是在优化目标中加入一个clip函数
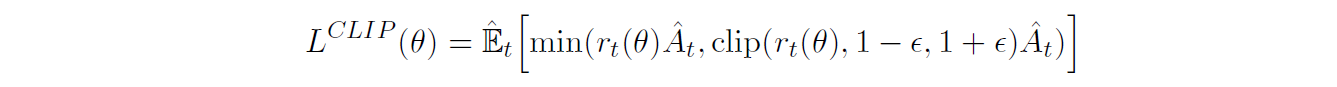
这里
r
(
t
)
r(t)
r(t)代表新旧策略动作的概率比,这样对策略更新速度进行了裁剪,防止参数更新过快

















 1863
1863

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









