







Pytorch半精度训练,只需要修改以下内容:
Variables:
x,y = x.cuda().half(),y.cuda().half()
model:
model.cuda().half()
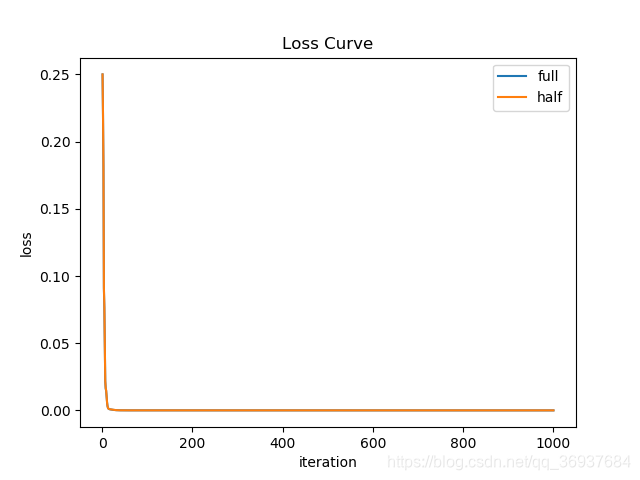
以两层累积BP网络为例,数据采用西瓜数据集3.0,分别使用全精度训练和半精度训练,发现在本文中网络很小的情况下,二者的loss曲线几乎是一样的(见下图),二者的测试结果也是一样的。
另外,使用Adam优化器注意需要设置eps参数,否则loss会报NaN:
使用SGD优化器则没有这个问题。
optimizer = optim.Adam(self.model.parameters(), lr=0.8,eps=1e-3)
Adam出现NaN的问题在这个博客中有具体提到。
完整代码
# -*- coding: utf-8 -*-
import pandas as pd
import numpy as np
from sklearn.preprocessing import LabelEncoder
from sklearn.preprocessing import StandardScaler
import torch
import torch.nn as nn
from torch.autograd import Variable
import torchvision.datasets as dset
import torchvision.transforms as transforms
import torch.nn.functional as F
import torch.optim as optim
seed = 2019
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed) # if you are using multi-GPU.
import random
np.random.seed(seed) # Numpy module.
random.seed(seed) # Python random module.
torch.manual_seed(seed)
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False #用来正常显示负号
plt.close('all')
def preprocess(data):
#将好瓜坏瓜映射为1/0
for title in data.columns:
if data[title].dtype=='object':
encoder = LabelEncoder()
data[title] 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 7849
7849

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









