







一、评价指标
机器学习分类模型常用评价指标有Accuracy, Precision, Recall和F1-score,而回归模型最常用指标有MAE和RMSE
import numpy as np
from sklearn import metrics
from sklearn.metrics import accuracy_score, roc_auc_score, r2_score
# 分类指标
# accuracy
y_pred = [0, 1, 0, 1]
y_true = [0, 1, 1, 1]
print('ACC:', accuracy_score(y_true, y_pred))
# Precision,Recall,F1-score
y_pred = [0, 1, 0, 0]
y_true = [0, 1, 0, 1]
print('Precision', metrics.precision_score(y_true, y_pred))
print('Recall', metrics.recall_score(y_true, y_pred))
print('F1-score:', metrics.f1_score(y_true, y_pred))
# AUC
y_true = np.array([0, 0, 1, 1])
y_scores = np.array([0.1, 0.4, 0.35, 0.8])
print('AUC score:', roc_auc_score(y_true, y_scores))
# 回归指标
# MAPE需要自己实现
def mape(y_true, y_pred):
return np.mean(np.abs((y_pred - y_true) / y_true))
y_true = np.array([1.0, 5.0, 4.0, 3.0, 2.0, 5.0, -3.0])
y_pred = np.array([1.0, 4.5, 3.8, 3.2, 3.0, 4.8, -2.2])
# MSE
print('MSE:', metrics.mean_squared_error(y_true, y_pred))
# RMSE
print('RMSE:', np.sqrt(metrics.mean_squared_error(y_true, y_pred)))
# MAE
print('MAE:', metrics.mean_absolute_error(y_true, y_pred))
# MAPE
print('MAPE:', mape(y_true, y_pred))
# R2-score
y_true = [3, -0.5, 2, 7]
y_pred = [2.5, 0.0, 2, 8]
print('R2-score:', r2_score(y_true, y_pred))
ACC: 0.75
Precision 1.0
Recall 0.5
F1-score: 0.6666666666666666
AUC score: 0.75
MSE: 0.2871428571428571
RMSE: 0.5358571238146014
MAE: 0.4142857142857143
MAPE: 0.1461904761904762
R2-score: 0.9486081370449679
二、EDA-数据探索性分析
EDA的价值主要在于熟悉数据集,了解数据集,对数据集进行验证来确定所获得数据集可以用于接下来的机器学习或者深度学习使用。
当了解了数据集之后我们下一步就是要去了解变量间的相互关系以及变量与预测值之间的存在关系。
引导数据科学从业者进行数据处理以及特征工程的步骤,使数据集的结构和特征集让接下来的预测问题更加可靠。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import missingno as msno
import scipy.stats as st
# 载入训练集和测试集
Train_data = pd.read_csv('used_car_train_20200313.csv', sep=' ')
Test_data = pd.read_csv('used_car_testB_20200421.csv', sep=' ')
# 总览数据概况
print('Train data shape:', Train_data.shape)
print('TestA data shape:', Test_data.shape)
print('前五行', Train_data.head())
# 通过info()来熟悉数据类型
Train_data.info()
# 通过describe()来熟悉数据的相关统计量
print(Train_data.describe())
# 查看异常值检测;
# 判断数据缺失和异常 nan情况
missing = Train_data.isnull().sum()
print(missing)
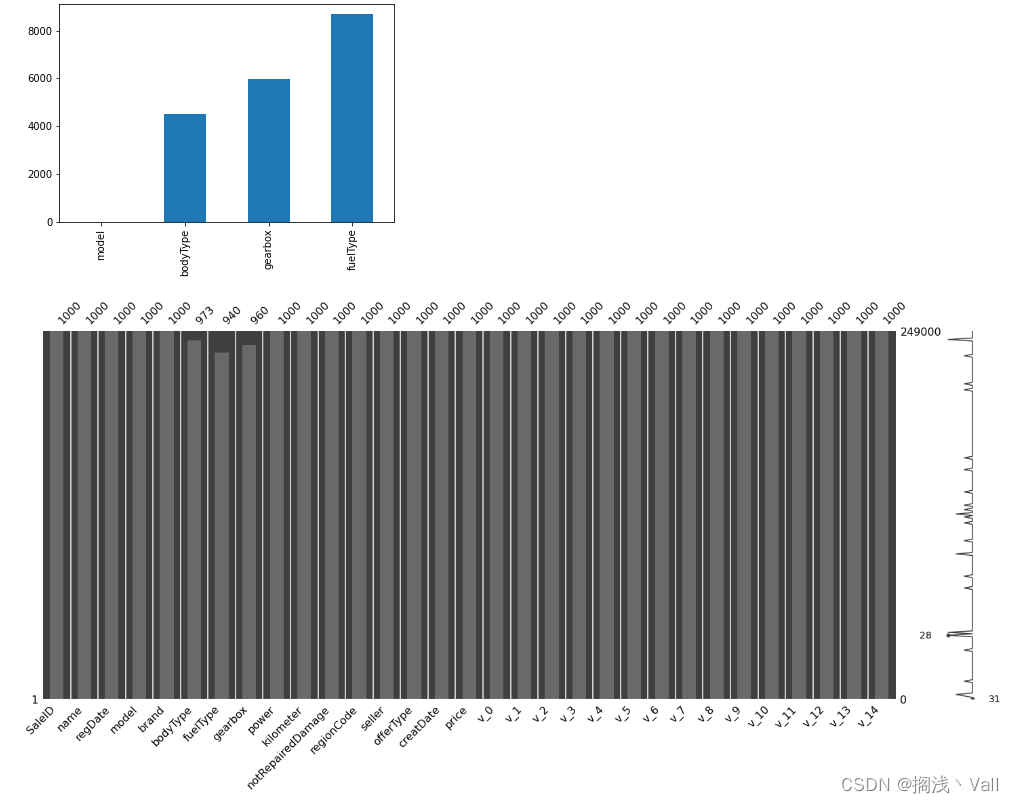
# 空数据柱状图可视化
missing = missing[missing > 0]
missing.sort_values(inplace=True)
missing.plot.bar()
# missingno缺失值矩阵图可视化
msno.matrix(Train_data.sample(250))
# missingno缺失值柱状图可视化
msno.bar(Train_data.sample(1000))
# 打印这个类型为Object的列,发现为 0 1 - ,即 - 也为空缺值
print(Train_data['notRepairedDamage'].value_counts())
# 给-换成nan
Train_data['notRepairedDamage'].replace('-', np.nan, inplace=True)
Test_data['notRepairedDamage'].replace('-', np.nan, inplace=True)
# 挨个字段打印一下 value_counts(),目的是看看特征倾斜情况 发现这俩几乎全是0,这两列没有吊毛用
print(Train_data["seller"].value_counts())
print(Train_data["offerType"].value_counts())
# 给他俩删了
del Train_data["seller"]
del Train_data["offerType"]
del Test_data["seller"]
del Test_data["offerType"]
# 了解预测值的分布;
print(Train_data['price'])
print(Train_data['price'].value_counts())
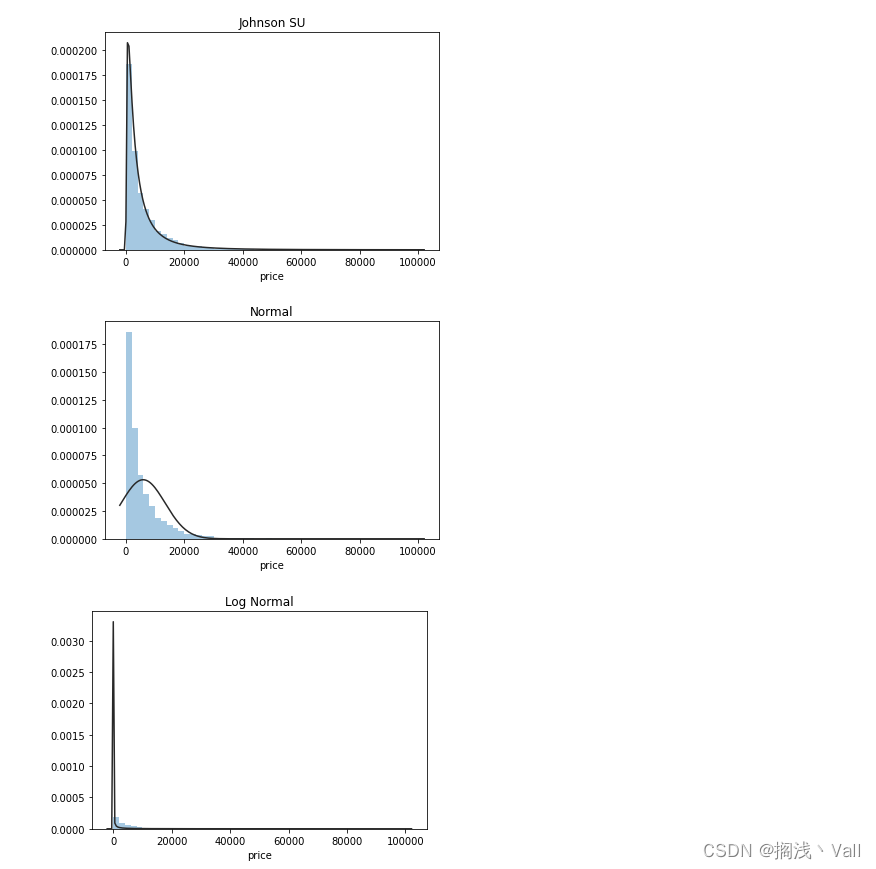
# 5) 线性拟合;
y = Train_data['price']
# 无界约翰逊分布johnsonsun拟合
plt.figure(1)
plt.title('Johnson SU')
sns.distplot(y, kde=False, fit=st.johnsonsu)
plt.figure(2)
plt.title('Normal')
sns.distplot(y, kde=False, fit=st.norm)
plt.figure(3)
plt.title('Log Normal')
sns.distplot(y, kde=False, fit=st.lognorm)
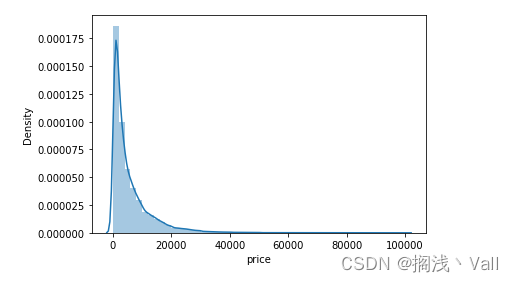
# 6) 偏度(skewness) and 峰度(peakedness;kurtosis)
# 偏度 是描述数据分布形态的统计量,其描述的是某总体取值分布的对称性,简单来说就是数据的不对称程度。
# 峰度 是描述某变量所有取值分布形态陡缓程度的统计量,简单来说就是数据分布顶的尖锐程度。
# Skewness or Kurtosis = 0 和正态一样
# Skewness > 0 右偏移 Kurtosis > 0 尖顶峰
# Skewness < 0 左偏移 Kurtosis < 0 平头哥
sns.distplot(Train_data['price'])
print("偏度Skewness: %f" % Train_data['price'].skew())
print("峰度Kurtosis: %f" % Train_data['price'].kurt())
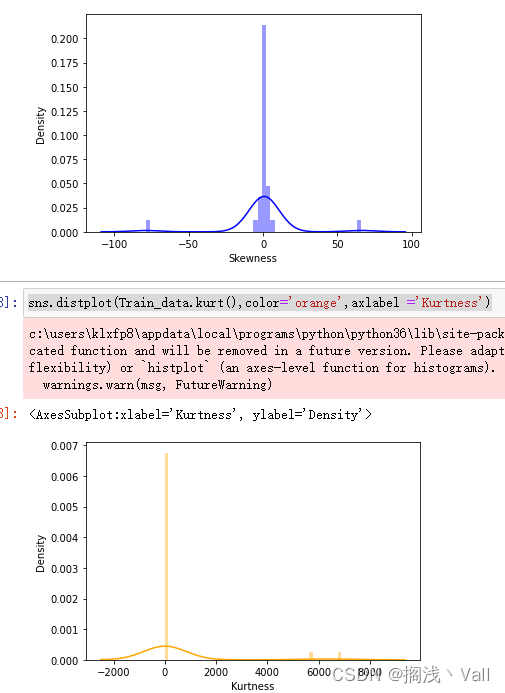
Train_data.skew(), Train_data.kurt()
sns.distplot(Train_data.skew(),color='blue',axlabel ='Skewness')
sns.distplot(Train_data.skew(),color='blue',axlabel ='Skewness')
sns.distplot(Train_data.kurt(),color='orange',axlabel ='Kurtness')
sns.distplot(Train_data.skew(),color=‘blue’,axlabel =‘Skewness’)
sns.distplot(Train_data.kurt(),color=‘orange’,axlabel =‘Kurtness’)
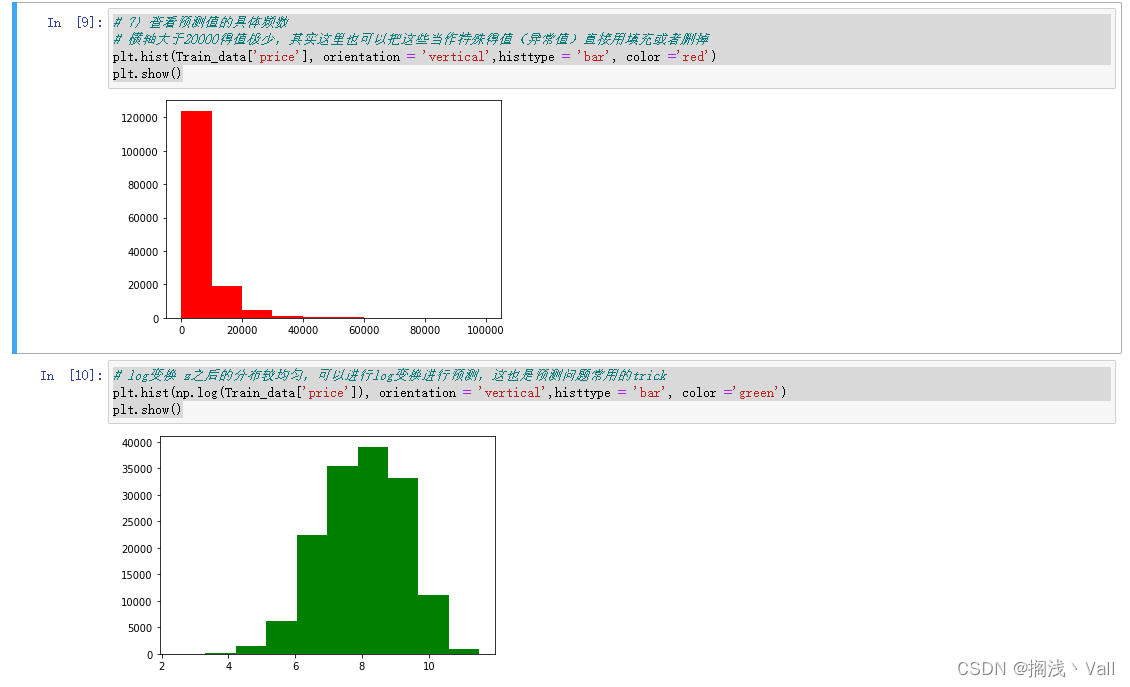
# 7) 查看预测值的具体频数
# 横轴大于20000得值极少,其实这里也可以把这些当作特殊得值(异常值)直接用填充或者删掉
plt.hist(Train_data['price'], orientation = 'vertical',histtype = 'bar', color ='red')
plt.show()
# log变换 z之后的分布较均匀,可以进行log变换进行预测,这也是预测问题常用的trick
plt.hist(np.log(Train_data['price']), orientation = 'vertical',histtype = 'bar', color ='green')
plt.show()
# 分离label即预测值
Y_train = Train_data['price']
# 人为根据实际含义来区分
numeric_features = ['power', 'kilometer', 'v_0', 'v_1', 'v_2', 'v_3', 'v_4', 'v_5', 'v_6', 'v_7', 'v_8', 'v_9', 'v_10', 'v_11', 'v_12', 'v_13','v_14' ]
categorical_features = ['name', 'model', 'brand', 'bodyType', 'fuelType', 'gearbox', 'notRepairedDamage', 'regionCode']
# 特征nunique分布 nunique()统计list中的不同值
for cat_fea in categorical_features:
print(cat_fea + "的特征分布如下:")
print("{}特征有个{}不同的值".format(cat_fea, Train_data[cat_fea].nunique()))
print(Train_data[cat_fea].value_counts())
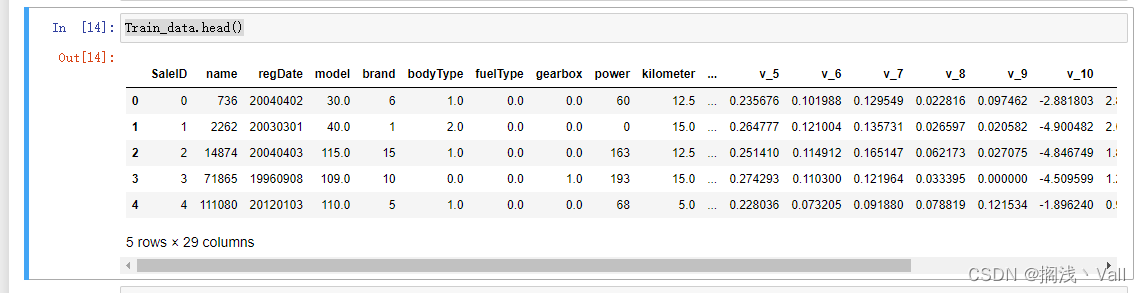
# 数字特征分析
numeric_features.append('price')
Train_data.head()
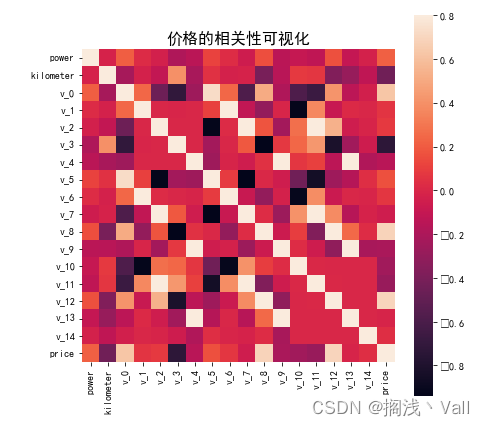
# 相关性分析
price_numeric = Train_data[numeric_features]
correlation = price_numeric.corr()
correlation['price'].sort_values(ascending = False)
f , ax = plt.subplots(figsize = (7, 7))
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.title('价格的相关性可视化',y=1,size=16)
sns.heatmap(correlation,square = True, vmax=0.8)
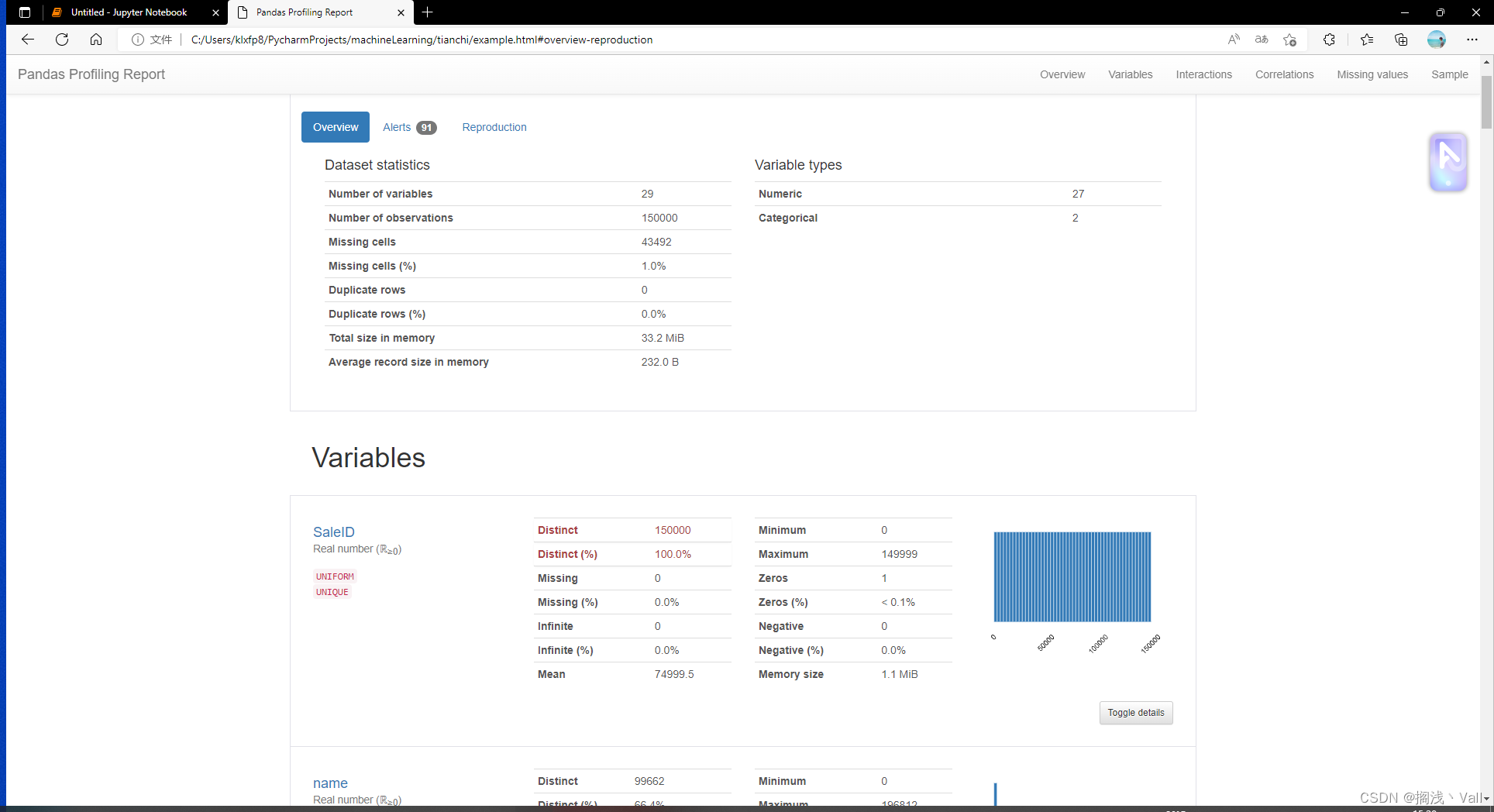
# 用pandas_profiling生成一个较为全面的可视化和数据报告
!pip install pandas_profiling
import pandas_profiling
pfr = pandas_profiling.ProfileReport(Train_data)
pfr.to_file("./example.html")

















 322
322

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









