







 本文介绍基于深度学习的文本分类,重点讨论FastText模型的原理和使用。通过FastText解决传统文本表示方法存在的高维度问题,利用 Embedding 层将单词映射到低维空间。在文本分类任务上,FastText表现出优势,尤其在CPU训练效率和精度方面。文章还提及使用交叉验证集调参以优化模型,并提供了作业,鼓励读者实践调整FastText参数。
本文介绍基于深度学习的文本分类,重点讨论FastText模型的原理和使用。通过FastText解决传统文本表示方法存在的高维度问题,利用 Embedding 层将单词映射到低维空间。在文本分类任务上,FastText表现出优势,尤其在CPU训练效率和精度方面。文章还提及使用交叉验证集调参以优化模型,并提供了作业,鼓励读者实践调整FastText参数。
NLP入门——天池新闻文本分类(4)基于深度学习的文本分类
基于深度学习的文本分类
深度学习的模型既可以提供特征提取的功能,也可以完成分类。
学习目标
- 学习FastText的使用和基础原理
- 学会使用验证集进行模型参数调优
文本表示方法 Part2
之前的文本表示方法的缺陷
之前我们对文档提供的表示方法包括
- One-hot
- Bag of Words
- N-gram
- TF-IDF
这些表示方法存在一个问题:我们得到的单词表示向量维度都很高,训练需要很长的时间;并且这些向量只考虑的单词的统计信息,没有办法表示单词与单词之间的关系。
深度学习中的文本表示方法可以将文本映射到更低维度的空间中,得到更稠密的词向量,包括像FastText、Word2Vec和Bert等,本次任务我们会用到的就是FastText。
FastText
FastText是一种典型的深度学习词向量表示方法,通过Embedding层将单词映射到稠密空间,然后将句子中所有单词在Embedding空间中进行平均,进而完成分类。
FaxstText是一个三层神经网络,输入层、隐含层和输出层。
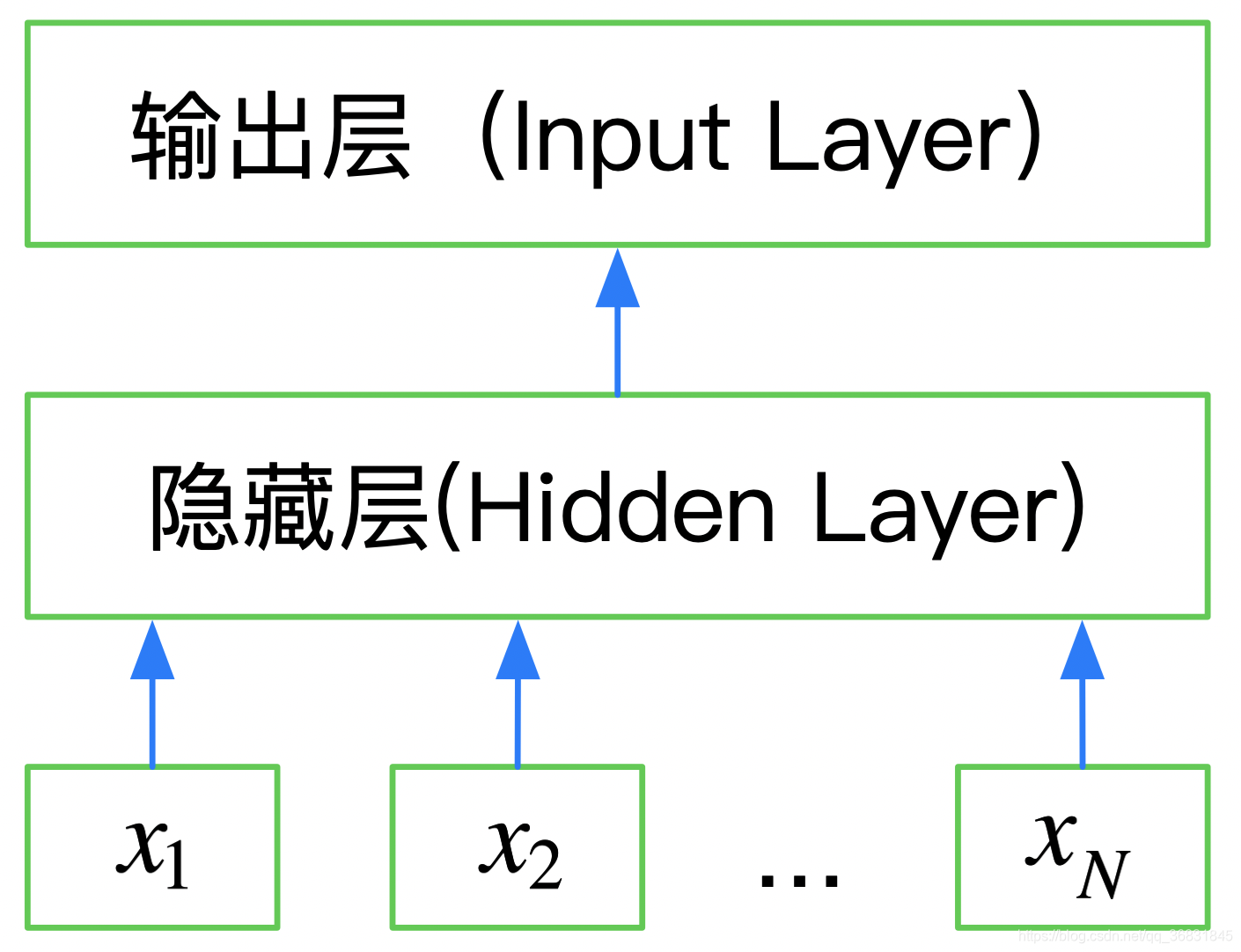
使用keras实现FastText网络结构如下:
# coding: utf-8
from __future__ import unicode_literals
from keras.models import Sequential
from keras.layers import Embedding
from keras.layers import GlobalAveragePooling1D
from keras.layers import Dense
VOCAB_SIZE = 2000
EMBEDDING_DIM = 100
MAX_WORDS = 500
CLASS_NUM = 5
def build_fastText():
model = Sequential()
# 通过embedding层,我们将词汇映射成EMBEDDING_SIZE维向量
model.add(Embedding(VOCAB_SIZE, EMBEDDING_SIZE, input_length=MAX_WORDS))
# 通过GlobalAveragePooling1D, 我们平均了文档中所有词的embedding
model.add(GlobalAveragePooling1D())
# 输出层通过Softmax分类,得到类别概率分布
model.add(Dense(CLASS_NUM, activation='softmax'))
# 定义损失函数、优化器、度量指标
model.compile(loss='categorical_crossentropy', optimizer='SGD', metrics='accuracy')
return model
if __name__ == '__main__':
model = bu[添加链接描述](https://github.com/facebookresearch/fastText/tree/master/python)ild_fastText()
print(model.summary())
FastText在文本分类的任务上是优于TF-IDF的:
- FastText使用Embedding叠加获得的文档向量,将相似的句子分为一类
- FastText学习到的Embedding向量空间维度低,可以更快训练
参考论文:Bag of Tricks for Efficient Text Classification, https://arxiv.org/abs/1607.01759
基于FastText的文本分类
FastText可以快速的在CPU上进行训练,最好的实践方法就是谷歌官方开源的版本:
https://github.com/facebookresearch/fastText/tree/master/python
安装方法:
- pip安装
pip install fasttext
- 源码安装
git clone https://github.com/facebookresearch/fastText.git
cd fastText
sudo pip install .
3.在学习赛数据集上的实践效果:
import pandas as pd
from sklearn.metrics import f1_score
# 转换为FastText需要的格式
train_df = pd.read_csv('../input/train_set.csv', sep='\t', nrows=15000)
train_df['label_ft'] = '__label__' + train_df['label'].astype(str)
train_df[['text','label_ft']].iloc[:-5000].to_csv('train.csv', index=None, header=None, sep='\t')
import fasttext
model = fasttext.train_supervised('train.csv', lr=1.0, wordNgrams=2, verbose=2, minCount=1, epoch=25, loss="hs")
val_pred = [model.predict(x)[0][0].split('__')[-1] for x in train_df.iloc[-5000:]['text']]
print(f1_score(train_df['label'].values[-5000:].astype(str), val_pred, average='macro'))
# 0.82
当数据量不断增加时,FastText的精度会不断上升,在测试集A上的f1_score达到了0.93
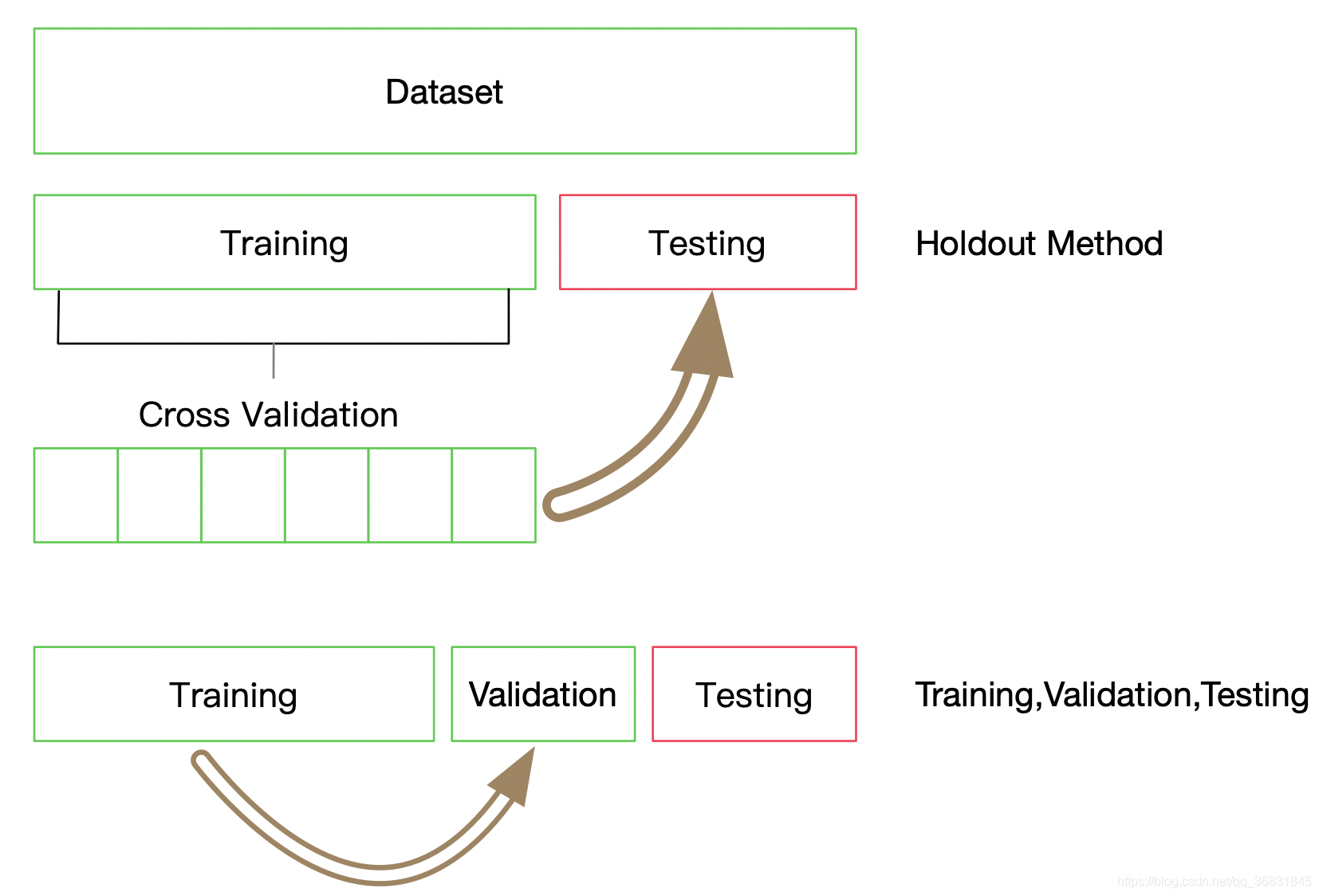
使用交叉验证集调参
在使用机器学习模型时,有些参数需要选择,这些参数会影响模型精度,选择的方法:
1.阅读AP文档,理清参数含义,合理调整
2.通过构造验证集,找到模型是否存在过拟合或者欠拟合的现象
本章作业
- 阅读FastText的文档,尝试修改参数, 并使用交叉验证
input # training file path (required)
lr # learning rate [0.1]
dim # size of word vectors [100]
ws # size of the context window [5]
epoch # number of epochs [5]
minCount # minimal number of word occurences [1]
minCountLabel # minimal number of label occurences [1]
minn # min length of char ngram [0]
maxn # max length of char ngram [0]
neg # number of negatives sampled [5]
wordNgrams # max length of word ngram [1]
loss # loss function {ns, hs, softmax, ova} [softmax]
bucket # number of buckets [2000000]
thread # number of threads [number of cpus]
lrUpdateRate # change the rate of updates for the learning rate [100]
t # sampling threshold [0.0001]
label # label prefix ['__label__']
verbose # verbose [2]
pretrainedVectors # pretrained word vectors (.vec file) for supervised learning []
我们通过阅读发现minCount、wordNgrams、loss几个参数可能会对结果影响较大,通过交叉验证,来得到参数结果
import pandas as pd
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
import fasttext
train_df = pd.read_csv("E:\学习\机器学习\新闻文本分类\input\\train_set.csv", sep='\t', nrows=15000)
train_df['label_ft'] = '__label__' + train_df['label'].astype(str)
kfold = KFold(n_splits=10)
for ngrams in [1,2,3,4]:
for minCount in [1,5,10,15,20]:
for loss in ["hs", "ns", "softmax", "ova"]:
for train,test in kfold.split(train_df):
train_df[['text', 'label_ft']].iloc[train].to_csv('train.csv', index=None, header=None, sep='\t')
model = fasttext.train_supervised('train.csv', lr=1.0, wordNgrams=2,verbose=2, minCount=1, epoch=25, loss="hs")
val_pred = [model.predict(x)[0][0].split('__')[-1] for x in train_df.iloc[test]['text']]
print("ngrams:{},minCount:{},loss:{}".format(ngrams, minCount, loss) ,f1_score(train_df['label'].values[test].astype(str), val_pred, average='macro'))

















 1431
1431

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









