






闭包的作用:
可以全局访问一个函数的成员变量,避免变量污染.
在循环的变量中找到自己的私有变量
闭包用法:A函数嵌套B函数,B函数可以访问A函数的成员变量,C函调用的时候有权访问A函数的成员变量
例子:
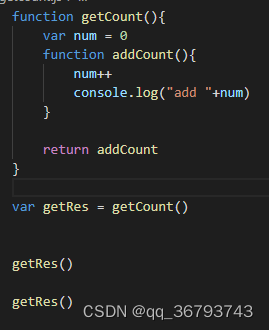
控制台输出 :
add 1
add 2
闭包原理:
每个函数都有自己的执行环境,当一个函数被执行时,其执行环境被推入到环境栈中,其活动对象(存储环境中定义的变量和函数)也被加入到作用域链中,一旦函数执行完毕,栈就会弹出该函数的执行环境,活动对象也被销毁。
对于上面的例子来说,getCount执行完之后,会返回addCount给getRes, getCount的执行环境从环境栈弹出,控制权交给全局环境,getCount的活动对象理应被销毁。 但此时addCount已经存储在全局活动对象中了,同时addCount需要访问num,所以getCount的活动对象没有被销毁,即使getRes执行完毕,getCount的活动对象依然存在作用域链中,直到getRes被销毁,getRes=null,getCount的活动对象才会被彻底释放.
闭包缺点:
闭包会造成getCount活动对象一直存在内存中,会造成内存泄漏
闭包只能取得外部函数中任何一个变量的最后一个值,在使用循环且返回的函数中带有循环变量是会得到错误结果
闭包有这么多缺点为什么还要有闭包??
先看下面例子:
let data = [];
for (var i = 0; i < 3; i++) {
data[i] = function () {
console.log(i);
};
}
data[0]();
data[1]();
data[2]();输出都是3,因为i是全局变量,在调用function的时候i在循环里面已经等于3了.
修改上面的使其正常打印0 1 2可以使用let 块级作用域
也可以使用
带有循环的闭包:
使用闭包使其正常使用
let data = [];
for (var i = 0; i < 3; i++) {
(function(j){ //函数A
data[j] = function () { //函数B
console.log(j);
}
})(i);
}
data[0]();
data[1]();
data[2]();打印出来是0,1,2
函数B访问函数A的变量
要想循环生成的每个函数B都真正拥有自己的私有变量,执行函数就要用一个函数包裹生成的闭包函数,并为闭包函数提供一个独立的变量,这个时候闭包函数中的 i 是来自包裹它们的自执行函数的参数
学习参考:https://blog.youkuaiyun.com/Jenn168/article/details/109276414

















 950
950

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









