








 超级会员免费看
超级会员免费看
 本文介绍了如何使用Python爬虫获取淘宝商品信息,包括商品标题、价格、销量和店铺位置。通过requests库发送HTTP请求,解析JSON数据,存储数据到CSV文件。爬虫流程包括爬虫规则、数据清洗和数据存储。关键词可动态设置,实现多关键字搜索功能。
本文介绍了如何使用Python爬虫获取淘宝商品信息,包括商品标题、价格、销量和店铺位置。通过requests库发送HTTP请求,解析JSON数据,存储数据到CSV文件。爬虫流程包括爬虫规则、数据清洗和数据存储。关键词可动态设置,实现多关键字搜索功能。
我们先来解决一下前置知识,本爬虫会用到以下库
- requests 是一个很实用Python的一个很实用的HTTP客户端,可以满足如今爬虫的需要
- json 用于数据的处理
- csv 用于数据的储存
分析说明
爬取淘宝商品的信息,数据主要用于分析市场趋势,从而制定一系列营销方案。实现功能如下:
- 使用者提供关键字,利用淘宝搜索功能获取搜索后的数据
- 获取商品信息:标题,价格,销量,店铺所在区域
- 数据以文件格式存储
功能实现依次体现了爬虫的开发流程:爬虫规则->数据清洗->数据存储。
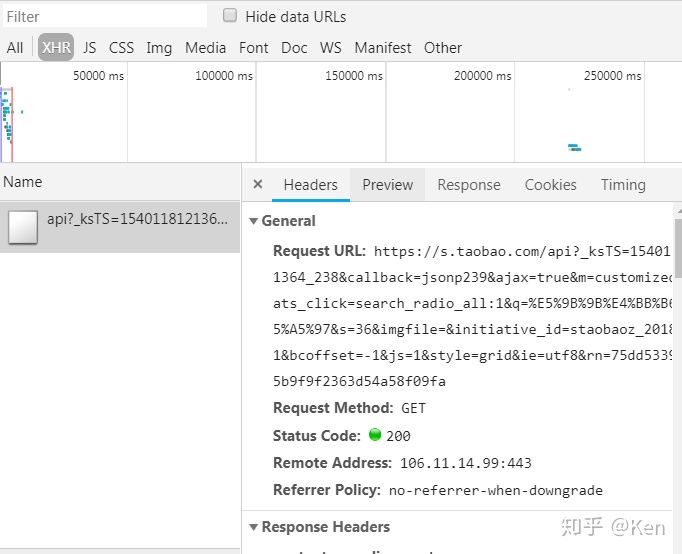
使用谷歌浏览器进入淘宝网站,利用搜索的功能输入‘四件套’关键字,
使用浏览器的调试功能捕捉信息,如果在响应的HTML中找不到数据,
那么可能数据是通过Ajax请求后台的,再通过前端渲染到页面上去的,
单击XHR,发送一个请求,查看数据请求信息如下图所示
接下来,我们单击Preview查看该URL的响应数据格式,
发现数据是JSON格式的,商品的标题,价格,销量,店铺名称和店铺所在地点
分别对应的数据为raw_title,view_price,view_sales,nick,item

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 4541
4541

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









