




 该Python代码用于从心电科住院部的心电图机XML数据中,批量提取II、III、V1至V6通道的心电信号,以500Hz采样率和30s时长。数据经过处理后,按列保存到以XML文件名命名的TXT文件中,便于后续分析使用。
该Python代码用于从心电科住院部的心电图机XML数据中,批量提取II、III、V1至V6通道的心电信号,以500Hz采样率和30s时长。数据经过处理后,按列保存到以XML文件名命名的TXT文件中,便于后续分析使用。
心电数据来自心电科住院部心电图机,原始数据格式为xml,保存在如下ecgData文件夹下,采样率 500Hz,采集时长均为30s,每份样本具有完整12导联心电信号。
每个xml格式心电文件内容如下:
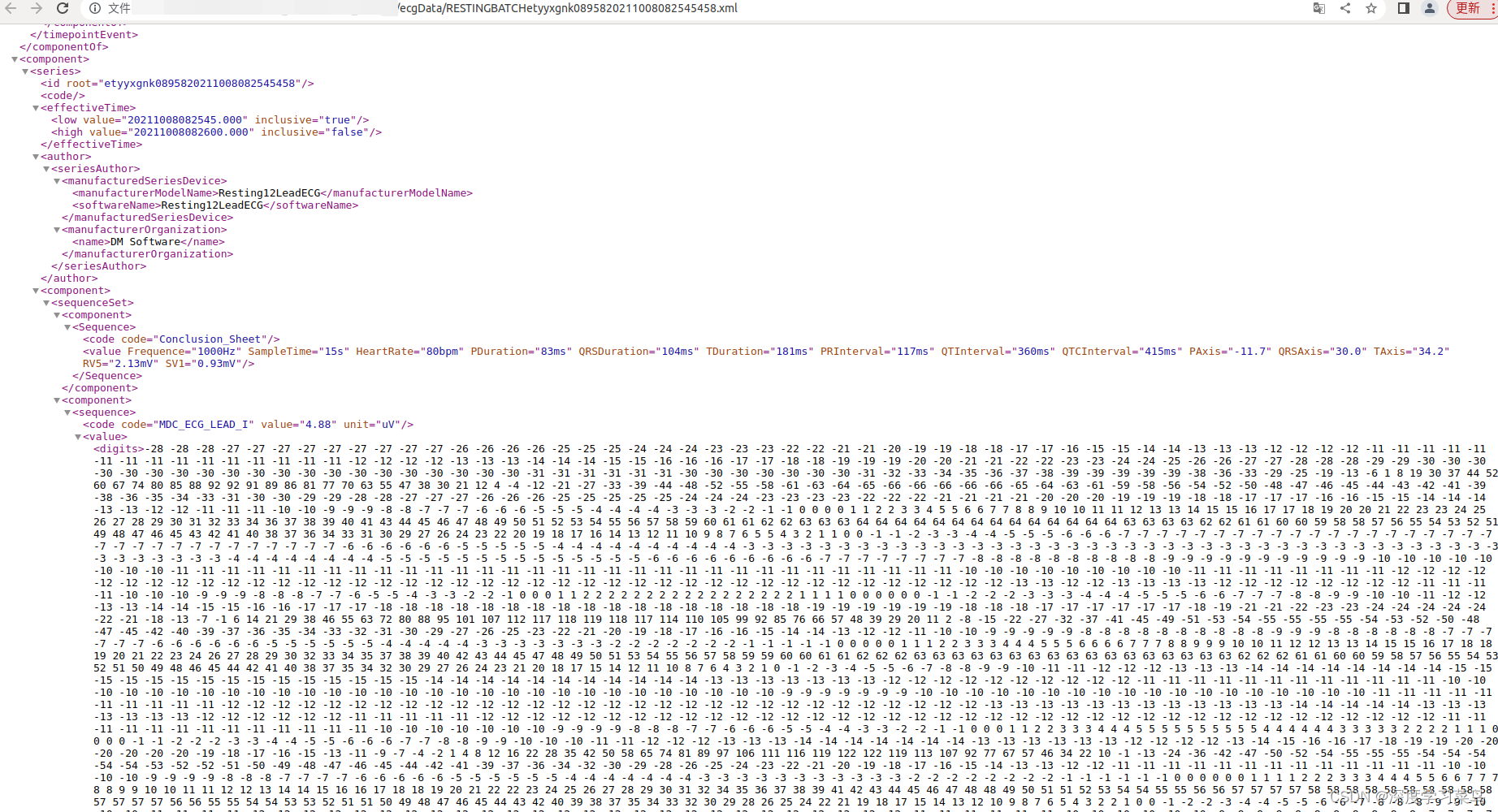

每个导联包括导联名称和心电数值(digits),心电数值有正负数值,数值之间以空格隔开。
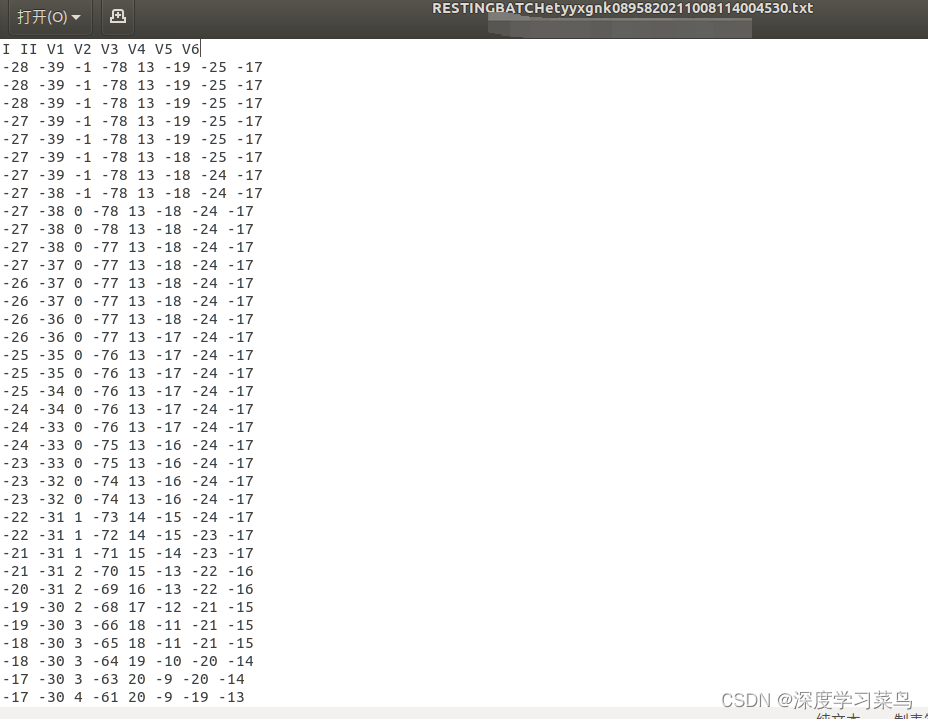
需求:批量提取每个xml格式中的心电数值和通道名称,提取I II V1 V2 V3 V4 V5 V6通道下的数据,批量保存到txt文件内,txt文件名以xml文件命名,每个通道的心电数值在txt中按列保存,不同通道之间以空格分开。
python代码如下:
# -*- coding:utf-8 -*-
import csv
import re
import os
from xml.dom import minidom
def readXML():
xml_filepath = "ecgData/" # 存放所有心电xml文件
txt_filepath = "xml_txt/" # 截取标注数据保存的csv文件路径
file_name_list = os.listdir(xml_filepath)
for xml_name in file_name_list:
# print("xml_name: ", xml_name)
txt_name = xml_name.split(".")[0] + ".txt" # RESTINGBATCHETYYXGNK0895820211019101323816.xml
print(txt_name)
# 打开xml文档
# dom = minidom.parse("ecgData/RESTINGBATCHETYYXGNK0895820211008083641980.xml") # parse用于打开一个XML文件
dom = minidom.parse(xml_filepath+xml_name) # parse用于打开一个XML文件
# 得到文档元素对象
# root = dom.documentElement # documentElement用于得到XML文件的唯一根元素
# print(root.nodeName) # nodeName为节点名称
# digits = root.getElementsByTagName('digits')
digits = dom.getElementsByTagName('digits')
MDC_ECG_LEAD_I_value = digits[0].firstChild.data # firstChild属性返回被选节点的第一个子节点,data表示获取该节点的数据
# print(MDC_ECG_LEAD_I_value)
MDC_ECG_LEAD_II_value = digits[1].firstChild.data # firstChild属性返回被选节点的第一个子节点,data表示获取该节点的数据
# print(MDC_ECG_LEAD_II_value)
# MDC_ECG_LEAD_III_value = digits[2].firstChild.data # firstChild属性返回被选节点的第一个子节点,data表示获取该节点的数据
# print(MDC_ECG_LEAD_III_value)
# MDC_ECG_LEAD_aVR_value = digits[3].firstChild.data # firstChild属性返回被选节点的第一个子节点,data表示获取该节点的数据
# print(MDC_ECG_LEAD_aVR_value)
# MDC_ECG_LEAD_aVL_value = digits[4].firstChild.data # firstChild属性返回被选节点的第一个子节点,data表示获取该节点的数据
# print(MDC_ECG_LEAD_aVL_value)
# MDC_ECG_LEAD_aVF_value = digits[5].firstChild.data # firstChild属性返回被选节点的第一个子节点,data表示获取该节点的数据
# print(MDC_ECG_LEAD_aVF_value)
MDC_ECG_LEAD_V1_value = digits[6].firstChild.data # firstChild属性返回被选节点的第一个子节点,data表示获取该节点的数据
# print(MDC_ECG_LEAD_V1_value)
MDC_ECG_LEAD_V2_value = digits[7].firstChild.data # firstChild属性返回被选节点的第一个子节点,data表示获取该节点的数据
# print(MDC_ECG_LEAD_V2_value)
MDC_ECG_LEAD_V3_value = digits[8].firstChild.data # firstChild属性返回被选节点的第一个子节点,data表示获取该节点的数据
# print(MDC_ECG_LEAD_V3_value)
MDC_ECG_LEAD_V4_value = digits[9].firstChild.data # firstChild属性返回被选节点的第一个子节点,data表示获取该节点的数据
# print(MDC_ECG_LEAD_V4_value)
MDC_ECG_LEAD_V5_value = digits[10].firstChild.data # firstChild属性返回被选节点的第一个子节点,data表示获取该节点的数据
# print(MDC_ECG_LEAD_V5_value)
MDC_ECG_LEAD_V6_value = digits[11].firstChild.data # firstChild属性返回被选节点的第一个子节点,data表示获取该节点的数据
# print(MDC_ECG_LEAD_V6_value)
# print(type(MDC_ECG_LEAD_V6_value)) <class 'str'>
# I通道
MDC_ECG_LEAD_I_value = re.split('\s+', MDC_ECG_LEAD_I_value) # 将字符串i以全部空白字符为分割符,将其分割成一个字符列表
new_MDC_ECG_LEAD_I_value = ','.join(MDC_ECG_LEAD_I_value) # 将字符列表用','拼接成一个新字符串
new_MDC_ECG_LEAD_I_value = new_MDC_ECG_LEAD_I_value.strip(',') # 将新字符串尾部产生的','去掉
list_new_MDC_ECG_LEAD_I_value = new_MDC_ECG_LEAD_I_value.split(',') # 按照,分隔成列表
list_new_MDC_ECG_LEAD_I_value_int = [int(i) for i in list_new_MDC_ECG_LEAD_I_value]
print(list_new_MDC_ECG_LEAD_I_value_int)
# II通道
MDC_ECG_LEAD_II_value = re.split('\s+', MDC_ECG_LEAD_II_value) # 将字符串i以全部空白字符为分割符,将其分割成一个字符列表
new_MDC_ECG_LEAD_II_value = ','.join(MDC_ECG_LEAD_II_value) # 将字符列表用','拼接成一个新字符串
new_MDC_ECG_LEAD_II_value = new_MDC_ECG_LEAD_II_value.strip(',') # 将新字符串尾部产生的','去掉
list_new_MDC_ECG_LEAD_II_value = new_MDC_ECG_LEAD_II_value.split(',') # 按照,分隔成列表
list_new_MDC_ECG_LEAD_II_value_int = [int(i) for i in list_new_MDC_ECG_LEAD_II_value]
print(list_new_MDC_ECG_LEAD_II_value_int)
# V1通道
MDC_ECG_LEAD_V1_value = re.split('\s+', MDC_ECG_LEAD_V1_value) # 将字符串i以全部空白字符为分割符,将其分割成一个字符列表
new_MDC_ECG_LEAD_V1_value = ','.join(MDC_ECG_LEAD_V1_value) # 将字符列表用','拼接成一个新字符串
new_MDC_ECG_LEAD_V1_value = new_MDC_ECG_LEAD_V1_value.strip(',') # 将新字符串尾部产生的','去掉
list_new_MDC_ECG_LEAD_V1_value = new_MDC_ECG_LEAD_V1_value.split(',') # 按照,分隔成列表
list_new_MDC_ECG_LEAD_V1_value_int = [int(i) for i in list_new_MDC_ECG_LEAD_V1_value]
print(list_new_MDC_ECG_LEAD_V1_value_int)
# V2通道
MDC_ECG_LEAD_V2_value = re.split('\s+', MDC_ECG_LEAD_V2_value) # 将字符串i以全部空白字符为分割符,将其分割成一个字符列表
new_MDC_ECG_LEAD_V2_value = ','.join(MDC_ECG_LEAD_V2_value) # 将字符列表用','拼接成一个新字符串
new_MDC_ECG_LEAD_V2_value = new_MDC_ECG_LEAD_V2_value.strip(',') # 将新字符串尾部产生的','去掉
list_new_MDC_ECG_LEAD_V2_value = new_MDC_ECG_LEAD_V2_value.split(',') # 按照,分隔成列表
list_new_MDC_ECG_LEAD_V2_value_int = [int(i) for i in list_new_MDC_ECG_LEAD_V2_value]
print(list_new_MDC_ECG_LEAD_V2_value_int)
# V3通道
MDC_ECG_LEAD_V3_value = re.split('\s+', MDC_ECG_LEAD_V3_value) # 将字符串i以全部空白字符为分割符,将其分割成一个字符列表
new_MDC_ECG_LEAD_V3_value = ','.join(MDC_ECG_LEAD_V3_value) # 将字符列表用','拼接成一个新字符串
new_MDC_ECG_LEAD_V3_value = new_MDC_ECG_LEAD_V3_value.strip(',') # 将新字符串尾部产生的','去掉
list_new_MDC_ECG_LEAD_V3_value = new_MDC_ECG_LEAD_V3_value.split(',') # 按照,分隔成列表
list_new_MDC_ECG_LEAD_V3_value_int = [int(i) for i in list_new_MDC_ECG_LEAD_V3_value]
print(list_new_MDC_ECG_LEAD_V3_value_int)
# V4通道
MDC_ECG_LEAD_V4_value = re.split('\s+', MDC_ECG_LEAD_V4_value) # 将字符串i以全部空白字符为分割符,将其分割成一个字符列表
new_MDC_ECG_LEAD_V4_value = ','.join(MDC_ECG_LEAD_V4_value) # 将字符列表用','拼接成一个新字符串
new_MDC_ECG_LEAD_V4_value = new_MDC_ECG_LEAD_V4_value.strip(',') # 将新字符串尾部产生的','去掉
list_new_MDC_ECG_LEAD_V4_value = new_MDC_ECG_LEAD_V4_value.split(',') # 按照,分隔成列表
list_new_MDC_ECG_LEAD_V4_value_int = [int(i) for i in list_new_MDC_ECG_LEAD_V4_value]
print(list_new_MDC_ECG_LEAD_V4_value_int)
# V5通道
MDC_ECG_LEAD_V5_value = re.split('\s+', MDC_ECG_LEAD_V5_value) # 将字符串i以全部空白字符为分割符,将其分割成一个字符列表
new_MDC_ECG_LEAD_V5_value = ','.join(MDC_ECG_LEAD_V5_value) # 将字符列表用','拼接成一个新字符串
new_MDC_ECG_LEAD_V5_value = new_MDC_ECG_LEAD_V5_value.strip(',') # 将新字符串尾部产生的','去掉
list_new_MDC_ECG_LEAD_V5_value = new_MDC_ECG_LEAD_V5_value.split(',') # 按照,分隔成列表
list_new_MDC_ECG_LEAD_V5_value_int = [int(i) for i in list_new_MDC_ECG_LEAD_V5_value]
print(list_new_MDC_ECG_LEAD_V5_value_int)
# V6通道
MDC_ECG_LEAD_V6_value = re.split('\s+', MDC_ECG_LEAD_V6_value) # 将字符串i以全部空白字符为分割符,将其分割成一个字符列表
new_MDC_ECG_LEAD_V6_value = ','.join(MDC_ECG_LEAD_V6_value) # 将字符列表用','拼接成一个新字符串
new_MDC_ECG_LEAD_V6_value = new_MDC_ECG_LEAD_V6_value.strip(',') # 将新字符串尾部产生的','去掉
list_new_MDC_ECG_LEAD_V6_value = new_MDC_ECG_LEAD_V6_value.split(',') # 按照,分隔成列表
list_new_MDC_ECG_LEAD_V6_value_int = [int(i) for i in list_new_MDC_ECG_LEAD_V6_value]
print(list_new_MDC_ECG_LEAD_V6_value_int)
fina_list = []
fina_list.append(list_new_MDC_ECG_LEAD_I_value_int)
fina_list.append(list_new_MDC_ECG_LEAD_II_value_int)
fina_list.append(list_new_MDC_ECG_LEAD_V1_value_int)
fina_list.append(list_new_MDC_ECG_LEAD_V2_value_int)
fina_list.append(list_new_MDC_ECG_LEAD_V3_value_int)
fina_list.append(list_new_MDC_ECG_LEAD_V4_value_int)
fina_list.append(list_new_MDC_ECG_LEAD_V5_value_int)
fina_list.append(list_new_MDC_ECG_LEAD_V6_value_int)
with open(txt_filepath + xml_name.split(".")[0] + ".txt", "w", newline="") as cf:
csvfile = csv.writer(cf, delimiter=' ')
for column in zip(*[i for i in fina_list]):
csvfile.writerow(column)
cf.close()
print("保存文件成功")
if __name__ == '__main__':
readXML()
批量提取后的txt文件保存到如下xml_txt文件夹内,txt文件名以xml文件命名。
保存到txt中内容如下:

















 3495
3495

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









