







 本文介绍了一种基于语义关系推理的few-shot目标检测方法SRR-FSD,旨在通过结合视觉信息和语义关系来提高检测器在不同shot数量下的稳定性。方法包括构建语义空间、动态关系图及解耦微调等步骤。
本文介绍了一种基于语义关系推理的few-shot目标检测方法SRR-FSD,旨在通过结合视觉信息和语义关系来提高检测器在不同shot数量下的稳定性。方法包括构建语义空间、动态关系图及解耦微调等步骤。
Semantic Relation Reasoning for Shot-Stable Few-Shot Object Detection
基于语义关系推理的fsod
虽然few shot的数据量很少,但是基类和novel类之间的语义关系应该是恒定的。在这篇工作中,调查了在使用视觉信息的同时使用语义关系,并且将显式的关系推理引入到fsod中。
具体来说,从大量的文本预料库中学习每个类的语义概念。让检测器把图像的表示投影到特征空间中。此外,还提出使用启发式的关系图来解决原始embedding的问题,并提出用动态关系图来增强embedding。
srr-fsd的实验结果对shot的数量具有鲁棒性。非sota,有竞争力的结果
提出从分类数据集中移除预训练的implicit shot的新评估标准,更实用
1.intro
fsod的性能对explicit shot和implicit shot的数量非常敏感
explicit shots: novel 类中的有标签对象数量(应该就是通常理解的shot数)
implicit shots: 根据下图理解为是否使用了imagenet预训练的backbone
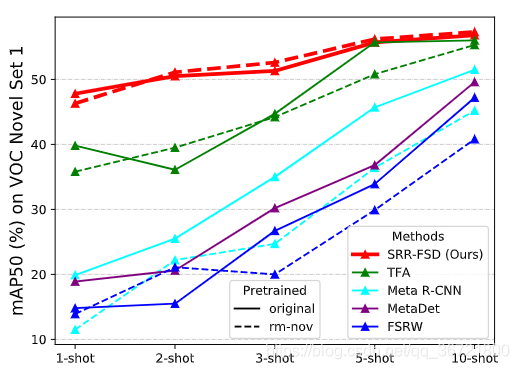
如上图所示,性能对x轴的shot数量非常敏感。实线表示 其中的backbone是在imagenet上预训练的。虚线表示训练backbone时,去掉了imagenet中novel类出现过的类。可见论文方法对explicit shots(x轴)和implicit shots都更为稳定。
关于implicit shots:用大型图像分类数据集上预训练的模型来初始化是一个非常常用的做法,然而,分类数据集中隐含的包含了很多novel 类中的图片,所以检测器实际上已经在backbone中包含并编码了novel类的知识。如上图所示,移除imagenet中预训练了的类确实会对性能有一定负面影响,所以当面对真实世界的极端情况时候,可能导致失败。
作者认为之所以对shot敏感,是因为没有考虑视觉信息之间的依赖关系。novel对象仅仅是独立的通过图像学习。但是,,不论novel类的shot有多少,基类和novel类之间的语义关系,都是永远存在滴!如下图所示,如果我们有着:摩托和自行车很
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 793
793

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









